This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
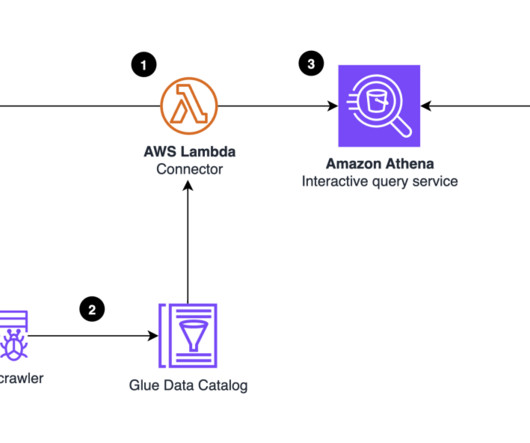
Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values. Although LLMs can generate syntactically correct SQL queries, they still need the table metadata for writing accurate SQL query.
Central to a transactional data lake are open table formats (OTFs) such as Apache Hudi , Apache Iceberg , and Delta Lake , which act as a metadata layer over columnar formats. For more examples and references to other posts, refer to the following GitHub repository. This post is one of multiple posts about XTable on AWS.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. Refer to Service Quotas for more details.
These organizations often maintain multiple AWS accounts for development, testing, and production stages, leading to increased complexity and cost. This micro environment is particularly well-suited for development, testing, or small production workloads where resource optimization and cost-efficiency are primary concerns.
As an important part of achieving better scalability, Ozone separates the metadata management among different services: . Ozone Manager (OM) service manages the metadata of the namespace such as volume, bucket and keys. Datanode service manages the metadata of blocks, containers and pipelines running on the datanode. .
At the same time, Miso went about an in-depth chunking and metadata-mapping of every book in the O’Reilly catalog to generate enriched vector snippet embeddings of each work. If the original Answers release was a LLM-driven retrieval engine, today’s new version of Answers is an LLM-driven research engine (in the truest sense).
The Eightfold Talent Intelligence Platform integrates with Amazon Redshift metadata security to implement visibility of data catalog listing of names of databases, schemas, tables, views, stored procedures, and functions in Amazon Redshift. This post discusses restricting listing of data catalog metadata as per the granted permissions.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. In internal tests, AI-driven scaling and optimizations showcased up to 10 times price-performance improvements for variable workloads.
For customers to gain the maximum benefits from these features, Cloudera best practice reflects the success of thousands of -customer deployments, combined with release testing to ensure customers can successfully deploy their environments and minimize risk. Traditional data clusters for workloads not ready for cloud. Networking .
Organization’s cannot hope to make the most out of a data-driven strategy, without at least some degree of metadata-driven automation. Metadata-Driven Automation in the BFSI Industry. Metadata-Driven Automation in the Pharmaceutical Industry. Metadata-Driven Automation in the Insurance Industry.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
You can now test the newly created application by running the following command: npm run dev By default, the application is available on port 5173 on your local machine. Unfiltered Table Metadata This tab displays the response of the AWS Glue API GetUnfilteredTableMetadata policies for the selected table.
Product Managers are responsible for the successful development, testing, release, and adoption of a product, and for leading the team that implements those milestones. Some of the best lessons are captured in Ron Kohavi, Diane Tang, and Ya Xu’s book: Trustworthy Online Controlled Experiments : A Practical Guide to A/B Testing.
To learn more about this process, refer to Enabling SAML 2.0 Save the federation metadata XML file You use the federation metadata file to configure the IAM IdP in a later step. In the Single sign-on section , under SAML Certificates , choose Download for Federation Metadata XML. Choose Test this application.
To learn more about working with events using EventBridge, refer to Events via Amazon EventBridge default bus. After you create the asset, you can add glossaries or metadata forms, but its not necessary for this post. We refer to this role as the instance-role throughout the post. Enter a name for the asset.
There are no automated tests , so errors frequently pass through the pipeline. There is no process to spin up an isolated dev environment to quickly add a feature, test it with actual data and deploy it to production. The pipeline has automated tests at each step, making sure that each step completes successfully.
In this post, well see the fundamental procedures, tools, and techniques that data engineers, data scientists, and QA/testing teams use to ensure high-quality data as soon as its deployed. First, we look at how unit and integration tests uncover transformation errors at an early stage. Key Tools & Processes Testing frameworks (e.g.,
These include internet-scale web and mobile applications, low-latency metadata stores, high-traffic retail websites, Internet of Things (IoT) and time series data, online gaming, and more. Table metadata, such as column names and data types, is stored using the AWS Glue Data Catalog. To create an S3 bucket, refer to Creating a bucket.
Iceberg tables store metadata in manifest files. As the number of data files increase, the amount of metadata stored in these manifest files also increases, leading to longer query planning time. The query runtime also increases because it’s proportional to the number of data or metadata file read operations. with Spark 3.3.2,
Data quality refers to the assessment of the information you have, relative to its purpose and its ability to serve that purpose. While the digital age has been successful in prompting innovation far and wide, it has also facilitated what is referred to as the “data crisis” – low-quality data. 2 – Data profiling.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and test data sources. The SageMaker Lakehouse data connection testing capability boosts your confidence in established connections. To learn more, refer to Amazon SageMaker Unified Studio.
The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day. For the template and setup information, refer to Test Your Streaming Data Solution with the New Amazon Kinesis Data Generator. We use two datasets in this post.
Running Apache Airflow at scale puts proportionally greater load on the Airflow metadata database, sometimes leading to CPU and memory issues on the underlying Amazon Relational Database Service (Amazon RDS) cluster. A resource-starved metadata database may lead to dropped connections from your workers, failing tasks prematurely.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Apache Iceberg addresses customer needs by capturing rich metadata information about the dataset at the time the individual data files are created.
There’s a very important difference between these two almost identical sentences: in the first, “it” refers to the cup. In the second, “it” refers to the pitcher. It’s by far the most convincing example of a conversation with a machine; it has certainly passed the Turing test. Ethan Mollick says that it is “only OK at search.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the context of Data in Place, validating data quality automatically with Business Domain Tests is imperative for ensuring the trustworthiness of your data assets.
They have dev, test, and production clusters running critical workloads and want to upgrade their clusters to CDP Private Cloud Base. Customer Environment: The customer has three environments: development, test, and production. Test and QA. Test and QA. Let’s take a look at one customer’s upgrade journey. Background: .
We use AWS Glue , a fully managed, serverless, ETL (extract, transform, and load) service, and the Google BigQuery Connector for AWS Glue (for more information, refer to Migrating data from Google BigQuery to Amazon S3 using AWS Glue custom connectors ). If you don’t have one, refer to Amazon Redshift Serverless. An S3 bucket.
’ It assigns unique identifiers to each data item—referred to as ‘payloads’—related to each event. Payload DJs facilitate capturing metadata, lineage, and test results at each phase, enhancing tracking efficiency and reducing the risk of data loss.
Apache Airflow is an open source tool used to programmatically author, schedule, and monitor sequences of processes and tasks, referred to as workflows. For detailed steps to create an Amazon MWAA environment using the Amazon MWAA console, refer to Introducing Amazon Managed Workflows for Apache Airflow (MWAA). Add the constraints-3.11-updated.txt
Benchmark setup In our testing, we used the 3 TB dataset stored in Amazon S3 in compressed Parquet format and metadata for databases and tables is stored in the AWS Glue Data Catalog. When statistics aren’t available, Amazon EMR and Athena use S3 file metadata to optimize query plans. With Amazon EMR 6.10.0
Backup and restore architecture The backup and restore strategy involves periodically backing up Amazon MWAA metadata to Amazon Simple Storage Service (Amazon S3) buckets in the primary Region. Refer to the detailed deployment steps in the README file to deploy it in your own accounts. The steps are as follows: [1.a]
According to Bob Lambert , analytics delivery lead at Anthem and former director of CapTech Consulting, important data architect skills include: A foundation in systems development: Data architects must understand the system development life cycle, project management approaches, and requirements, design, and test techniques.
The individual pieces of data within these streams are often referred to as records. client('kinesis', region_name='ap-southeast-2') def lambda_handler(event, context): try: response = client.put_record( StreamName='test', Data=b'Sample 1 MB.', To help you understand better, we experimented by trying to send a record of 1.5
While data management has become a common term for the discipline, it is sometimes referred to as data resource management or enterprise information management (EIM). Programs must support proactive and reactive change management activities for reference data values and the structure/use of master data and metadata.
If you have integrated IAM Identity Center with your Identity Provider (IdP), you can use existing users and groups mapped to your IdP for this test. Test your users in IAM Identity Center (to create users, refer to Add users ). For more information, refer to SAML authentication for OpenSearch Dashboards.
Apache Iceberg manages these schema changes in a backward-compatible way through its innovative metadata table evolution architecture. With Lake Formation, you can manage fine-grained access control for your data lake data on Amazon S3 and its metadata in the Data Catalog. Iceberg maintains the table state in metadata files.
We split the solution into two primary components: generating Spark job metadata and running the SQL on Amazon EMR. The first component (metadata setup) consumes existing Hive job configurations and generates metadata such as number of parameters, number of actions (steps), and file formats. sql_path SQL file name.
Pre-loading of reference data provides low latency and high throughput. For a general overview of data enrichment patterns, refer to Common streaming data enrichment patterns in Amazon Managed Service for Apache Flink. To compare the performance of the enrichment patterns, we ran performance testing based on synthetic data.
Figure 1: Flow of actions for self-service analytics around data assets stored in relational databases First, the data producer needs to capture and catalog the technical metadata of the data asset. Second, the data producer needs to consolidate the data asset’s metadata in the business catalog and enrich it with business metadata.
Zookeeper or KRaft for cluster coordination – Kafka relies on Apache ZooKeeper or KRaft for cluster coordination and metadata management. To learn more about the core components of Amazon MSK tiered storage, refer to Deep dive on Amazon MSK tiered storage. To test it, we created a three-node cluster with the new m7g instance type.
You can list all the datasets available in the repository, and see associated metadata: all_datasets = pycaret.datasets.get_data('index'). handling missing values with various imputation methods available), splitting into train and test sets, as well as some aspects of feature engineering and training. Domino Reference Project.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content