This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon Redshift is used to analyze structured and semi-structureddata across data warehouses, operational databases, and data lakes. Table metadata is fetched from AWS Glue.
In order to figure out why the numbers in the two reports didn’t match, Steve needed to understand everything about the data that made up those reports – when the report was created, who created it, any changes made to it, which system it was created in, etc. Enterprise data governance. Metadata in data governance.
Untapped data, if mined, represents tremendous potential for your organization. While there has been a lot of talk about big data over the years, the real hero in unlocking the value of enterprise data is metadata , or the data about the data. Metadata Is the Heart of Data Intelligence.
Good data governance has always involved dealing with errors and inconsistencies in datasets, as well as indexing and classifying that structureddata by removing duplicates, correcting typos, standardizing and validating the format and type of data, and augmenting incomplete information or detecting unusual and impossible variations in the data.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. Industry-leading price-performance: Amazon Redshift launches RA3.large
Content management systems: Content editors can search for assets or content using descriptive language without relying on extensive tagging or metadata. Intelligent data and content analysis Sentiment analysis Lets look at a practical example: an internal system allows employees to post short status messages about their work.
If you’re serious about a data-driven strategy , you’re going to need a data catalog. Organizations need a data catalog because it enables them to create a seamless way for employees to access and consume data and business assets in an organized manner. Three Types of Metadata in a Data Catalog.
Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. By some estimates, unstructured data can make up to 80–90% of all new enterprise data and is growing many times faster than structureddata.
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust datastrategy incorporating a comprehensive data governance approach. Let’s look at some of the key changes in the data pipelines namely, data cataloging, data quality, and vector embedding security in more detail.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with data quality, and lack of cross-functional governance structure for customer data. Then, you transform this data into a concise format.
The Data Management Association (DAMA) International defines it as the “planning, oversight, and control over management of data and the use of data and data-related sources.” Such a framework provides your organization with a holistic approach to collecting, managing, securing, and storing data.
Data scientists are becoming increasingly important in business, as organizations rely more heavily on data analytics to drive decision-making and lean on automation and machine learning as core components of their IT strategies. Data scientist job description. Semi-structureddata falls between the two.
The results showed that (among those surveyed) approximately 90% of enterprise analytics applications are being built on tabular data. The ease with which such structureddata can be stored, understood, indexed, searched, accessed, and incorporated into business models could explain this high percentage.
S3 Tables integration with the AWS Glue Data Catalog is in preview, allowing you to stream, query, and visualize dataincluding Amazon S3 Metadata tablesusing AWS analytics services such as Amazon Data Firehose , Amazon Athena , Amazon Redshift, Amazon EMR, and Amazon QuickSight. With AWS Glue 5.0,
As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Newer data lakes are highly scalable and can ingest structured and semi-structureddata along with unstructured data like text, images, video, and audio.
Data consumers need detailed descriptions of the business context of a data asset and documentation about its recommended use cases to quickly identify the relevant data for their intended use case. Go to your asset in your data project and choose Generate summary to obtain the detailed description of the asset and its columns.
Unlike structureddata, which fits neatly into databases and tables, etc. Going back to our early examples of unstructured data and depending on what business you’re in, ancient artifacts may or may not be relevant to your organization’s goals and AI strategy.
Metadata management. Users can centrally manage metadata, including searching, extracting, processing, storing, sharing metadata, and publishing metadata externally. The metadata here is focused on the dimensions, indicators, hierarchies, measures and other data required for business analysis.
As it relates to the use case in the post, ZS is a global leader in integrated evidence and strategy planning (IESP), a set of services that help pharmaceutical companies to deliver a complete and differentiated evidence package for new medicines. We use various chunking strategies to enhance text comprehension.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structureddata from open format files in Amazon S3 data lake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your data lake, enabling you to run analytical queries.
We live in a hybrid data world. In the past decade, the amount of structureddata created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
JSON data in Amazon Redshift Amazon Redshift enables storage, processing, and analytics on JSON data through the SUPER data type, PartiQL language, materialized views, and data lake queries. The function JSON_PARSE allows you to extract the binary data in the stream and convert it into the SUPER data type.
Applications such as financial forecasting and customer relationship management brought tremendous benefits to early adopters, even though capabilities were constrained by the structured nature of the data they processed. have encouraged the creation of unstructured data. Artificial Intelligence
‘Data Fabric’ has reached where ‘Cloud Computing’ and ‘Grid Computing’ once trod. Data Fabric hit the Gartner top ten in 2019. The Data Fabric paradigm combines design principles and methodologies for building efficient, flexible and reliable data management ecosystems.
We live in a hybrid data world. In the past decade, the amount of structureddata created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. It is designed for analyzing large volumes of data and performing complex queries on structured and semi-structureddata. Data mapping involves identifying and documenting the flow of personal data in an organization.
This recognition underscores Cloudera’s commitment to continuous customer innovation and validates our ability to foresee future data and AI trends, and our strategy in shaping the future of data management. Cloudera, a leader in big data analytics, provides a unified Data Platform for data management, AI, and analytics.
We use Snowflake very heavily as our primary data querying engine to cross all of our distributed boundaries because we pull in from structured and non-structureddata stores and flat objects that have no structure,” Frazer says. “We think we found a good balance there. Now that’s down to a number of hours.”
AWS Glue crawls both S3 bucket paths, populates the AWS Glue database tables based on the inferred schemas, and makes the data available to other analytics applications through the AWS Glue Data Catalog. Athena is used to run geospatial queries on the location data stored in the S3 buckets. Choose Run.
If the point of Business Intelligence (BI) data governance is to leverage your datasets to support information transparency and decision-making, then it’s fair to say that the data catalog is key for your BI strategy. At least, as far as data analysis is concerned. The Benefits of StructuredData Catalogs.
You can build projects and subscribe to both unstructured and structureddata assets within the Amazon DataZone portal. For structured datasets, you can use Amazon DataZone blueprint-based environments like data lakes (Athena) and data warehouses (Amazon Redshift).
A modern information lifecycle management approach Today’s ILM approach recognizes the enterprise value of all digitized and enriched assets , avoiding the habituated, narrow reliance ontraditional structureddata. Here is a high-level overview of the ILM steps and structure. Structure/Operationalize.
A data catalog is a central hub for XAI and understanding data and related models. While “operational exhaust” arrived primarily as structureddata, today’s corpus of data can include so-called unstructured data. Data management can never be a pure, complete process. Other Technologies. The challenge?
This shift of both a technical and an outcome mindset allows them to establish a centralized metadata hub for their data assets and effortlessly access information from diverse systems that previously had limited interaction. There are four groups of data that are naturally siloed: Structureddata (e.g.,
Executing dbt docs creates an interactive, automatically generated data model catalog that delineates linkages, transformations, and test coverageessential for collaboration among data engineers, analysts, and business teams. Data freshness propagation: No automatic tracking of data propagation delays across multiplemodels.
This approach ensures that the CDO role (I have a number of CDOs functionally reporting to me) remains close to the business and the local entity it supports, it ensures that my management team is directly connected to the needs of the business locally, and that the local businesses have a direct connection to the global strategy.
Here, the ability of knowledge graphs to integrate diverse data from multiple sources is of high relevance. As you can see from the slide below, knowledge graphs can provide a single access point for various types of data such as structureddata, knowledge organization systems, transactional data and signals from unstructured content.
Specifically, the increasing amount of data being generated and collected, and the need to make sense of it, and its use in artificial intelligence and machine learning, which can benefit from the structureddata and context provided by knowledge graphs. We get this question regularly. million users.
RED’s focus on news content serves a pivotal function: identifying, extracting, and structuringdata on events, parties involved, and subsequent impacts. Understanding how certain types of events have historically affected their stock prices can guide future business decisions and communication strategies.
We fetch the metadata of the users_xxxxxx table from Athena. The following are a few important considerations regarding how the Lambda function handles Iceberg table metadata changes: In this approach, target metadata takes precedence during DML operations. It’s imperative that the source and target metadata match.
That dirty data then corrupts analyses and forces mistakes. A frequent and periodic data cleansing strategy is. Lack of metadata. A lack of organization is another sign of a data swamp, typically driven by bad or incomplete metadata.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. These optimizations are enabled by default and Amazon Redshift users will benefit with better query response times for their workloads.
Knowledge graphs, while not as well-known as other data management offerings, are a proven dynamic and scalable solution for addressing enterprise data management requirements across several verticals. Knowledge graphs are also essential for any semantic AI and explainable AI strategy.
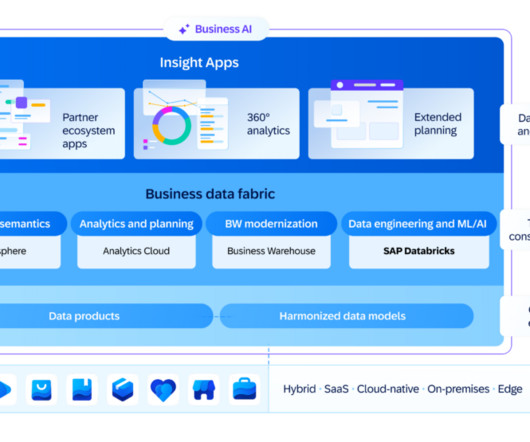
SAP has recently started to emphasize the business aspect in its messaging (see related BARC blog post in German ), a strategy it is continuing with BDC. Instead, SAP is focusing on its core strength leveraging its deep understanding of business processes to transform the resulting data and metadata into valuable D&A insights.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content