This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now With Actionable, Automatic, Data Quality Dashboards Imagine a tool that can point at any dataset, learn from your data, screen for typical data quality issues, and then automatically generate and perform powerful tests, analyzing and scoring your data to pinpoint issues before they snowball. New Quality Dashboard & Score Explorer.
Collaborating closely with our partners, we have tested and validated Amazon DataZone authentication via the Athena JDBC connection, providing an intuitive and secure connection experience for users. After connecting, you can query, visualize, and share data—governed by Amazon DataZone—within the tools you already know and trust.
OpenSearch Service stores different types of stored objects, such as dashboards, visualizations, alerts, security roles, index templates, and more, within the domain. es.amazonaws.com' # e.g. my-test-domain.us-east-1.es.amazonaws.com, Jenkins retrieves JSON files from the GitHub repository and performs validation.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and test data sources. The SageMaker Lakehouse data connection testing capability boosts your confidence in established connections. Lets try a quick visualization to analyze the rating distribution.
We are excited to announce the preview of API-driven, OpenLineage-compatible data lineage in Amazon DataZone to help you capture, store, and visualize lineage of data movement and transformations of data assets on Amazon DataZone. The lineage visualized includes activities inside the Amazon DataZone business data catalog.
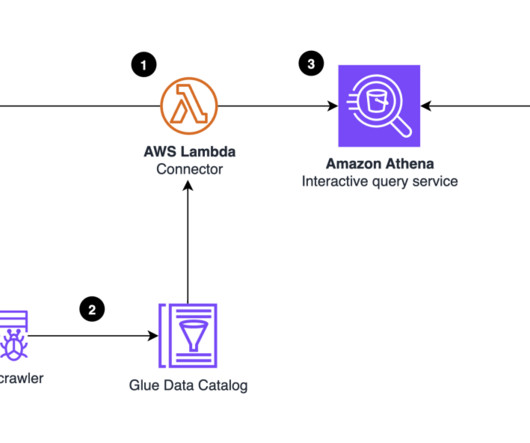
These include internet-scale web and mobile applications, low-latency metadata stores, high-traffic retail websites, Internet of Things (IoT) and time series data, online gaming, and more. Table metadata, such as column names and data types, is stored using the AWS Glue Data Catalog. You don’t need to write any code. Choose Next.
Through a visual designer, you can configure custom AI search flowsa series of AI-driven data enrichments performed during ingestion and search. You can use the flow builder through APIs or a visual designer. The visual designer is recommended for helping you manage workflow projects. Flows are a pipeline of processor resources.
The Query Editor V2 offers a user-friendly interface for connecting to your Redshift clusters, executing queries, and visualizing results. Save the federation metadata XML file You use the federation metadata file to configure the IAM IdP in a later step. Test the SSO setup You can now test the SSO setup.
They realized that the search results would probably not provide an answer to my question, but the results would simply list websites that included my words on the page or in the metadata tags: “Texas”, “Cows”, “How”, etc. That’s enterprise-wide agile curiosity, question-asking, hypothesizing, testing/experimenting, and continuous learning.
For the purposes of this post, we use a local machine based on MacOS and Visual Studio Code as our integrated development environment (IDE), but you could use your preferred development environment and IDE. Unfiltered Table Metadata This tab displays the response of the AWS Glue API GetUnfilteredTableMetadata policies for the selected table.
That’s because it’s the best way to visualizemetadata , and metadata is now the heart of enterprise data management and data governance/ intelligence efforts. erwin DM 2020 is an essential source of metadata and a critical enabler of data governance and intelligence efforts. Click here to test drive of the new erwin DM.
Execution of this mission requires the contribution of several groups: data center/IT, data engineering, data science, data visualization, and data governance. Data Visualization, Preparation – Self-service tools sucha as Tableau, Alteryx. Data Visualization, Preparation – Self-service tools sucha as Tableau, Alteryx.
Duplicating data from a production database to a lower or lateral environment and masking personally identifiable information (PII) to comply with regulations enables development, testing, and reporting without impacting critical systems or exposing sensitive customer data. These tables are the metadata representation of the customer tables.
In the context of Data in Place, validating data quality automatically with Business Domain Tests is imperative for ensuring the trustworthiness of your data assets. Running these automated tests as part of your DataOps and Data Observability strategy allows for early detection of discrepancies or errors. What is Data in Use?
With all these diverse metadata sources, it is difficult to understand the complicated web they form much less get a simple visual flow of data lineage and impact analysis. The metadata-driven suite automatically finds, models, ingests, catalogs and governs cloud data assets. GDPR, CCPA, HIPAA, SOX, PIC DSS).
DataOps Automation (Orchestration, Environment Management, Deployment Automation) DataOps Observability (Monitoring, Test Automation) Data Governance (Catalogs, Lineage, Stewardship) Data Privacy (Access and Compliance) Data Team Management (Projects, Tickets, Documentation, Value Stream Management) What are the drivers of this consolidation?
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. In internal tests, AI-driven scaling and optimizations showcased up to 10 times price-performance improvements for variable workloads.
Amazon SageMaker Unified Studio brings together functionality and tools from the range of standalone studios, query editors, and visual tools available today in Amazon EMR , AWS Glue , Amazon Redshift , Amazon Bedrock , and the existing Amazon SageMaker Studio. With AWS Glue 5.0,
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
Everything is being tested, and then the campaigns that succeed get more money put into them, while the others aren’t repeated. BI users analyze and present data in the form of dashboards and various types of reports to visualize complex information in an easier, more approachable way. 6) Smart and faster reporting.
The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day. The near-real-time insights can then be visualized as a performance dashboard using OpenSearch Dashboards. client("s3") S3_BUCKET = ' ' kinesis_client = boto3.client("kinesis")
As quality issues are often highlighted with the use of dashboard software , the change manager plays an important role in the visualization of data quality. It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. 2 – Data profiling.
The data architect is responsible for visualizing and designing an organization’s enterprise data management framework. Data architects and data engineers work together to visualize and build the enterprise data management framework. In some ways, the data architect is an advanced data engineer.
In this post, well see the fundamental procedures, tools, and techniques that data engineers, data scientists, and QA/testing teams use to ensure high-quality data as soon as its deployed. First, we look at how unit and integration tests uncover transformation errors at an early stage. Key Tools & Processes Testing frameworks (e.g.,
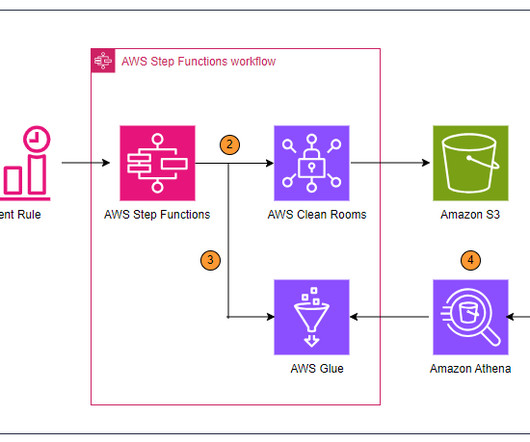
Instead, they rely on up-to-date dashboards that help them visualize data insights to make informed decisions quickly. QuickSight is used to query, build visualizations, and publish dashboards using the data from the query results. After a successful update of the AWS Glue table metadata, the state machine is complete.
Metadata is the basis of trust for data forensics as we answer the questions of fact or fiction when it comes to the data we see. Being that AI is comprised of more data than code, it is now more essential than ever to combine data with metadata in near real-time. And lets not forget about the controls.
However, these two processes are essentially distinct, and their testing needs differ in manyways. As enterprises extend their data pipelines, high-quality, automated testing for both transformations and conversions is critical to assuring data integrity, performance, and compliance across many platforms.
AWS Glue Data Catalog stores information as metadata tables, where each table specifies a single data store. The AWS Glue crawler writes metadata to the Data Catalog by classifying the data to determine the format, schema, and associated properties of the data. For additional information, see Visualize with QuickSight using Athena.
Metadata Harvesting and Ingestion : Automatically harvest, transform and feed metadata from virtually any source to any target to activate it within the erwin Data Catalog (erwin DC). Data Cataloging: Catalog and sync metadata with data management and governance artifacts according to business requirements in real time.
Programs must support proactive and reactive change management activities for reference data values and the structure/use of master data and metadata. Key features include a collaborative business glossary, the ability to visualize data lineage, and generate data quality measurements based on business definitions.
Through use of data analytics, data visualization, and data modeling techniques and technologies, BI analysts can identify trends that can help other departments, managers, and executives make business decisions to modernize and improve processes in the organization.
It also integrates with other OpenSearch integrations so you can install prepackaged queries and visualizations to analyze your data, making it straightforward to quickly get started. You can now analyze data in cloud object stores and simultaneously use the operational analytics and visualizations of OpenSearch Service.
With the right data catalog tool, organizations can automate enterprise metadata management – including data cataloging, data mapping, data quality and code generation for faster time to value and greater accuracy for data movement and/or deployment projects. A data catalog benefits organizations in a myriad of ways.
It serves as a visual guide in designing and deploying databases with high-quality data sources as part of application development. A data model is a visual representation of data elements and the relationships between them. Data modeling is a critical component of metadata management , data governance and data intelligence.
Additionally, if any user makes changes to the information, the metadata should be configured to identify the user or computer resource that made those changes. Instead of the government acting as a watchdog, it aims to strike a balance between fostering innovation and mitigating potential risks associated with AI technologies.
We discuss how to visualize data quality scores in Amazon DataZone, enable AWS Glue Data Quality when creating a new Amazon DataZone data source, and enable data quality for an existing data asset. If the asset has AWS Glue Data Quality enabled, you can now quickly visualize the data quality score directly in the catalog search pane.
Today, PyCaret still utilizes many modules that will be familiar to Pythonistas: Pandas and Numpy for data wrangling, Matplotlib, Plotly and Seaborn for visualization, scikit-learn and XGBoost for modeling, Gensim, Spacy and NLTK for natural language processing, among others. Image from pycaret.org. Building a Pipeline. interpret_model(best).
Parquet also stores type metadata which makes reading back and processing the files later slightly easier. In the `First_Exploration.ipynb` we also leverage `cuXfilter`, a RAPIDS-accelerated cross filtering visualization library for some of the charts. This notebook goes through loading just the train and test datasets.
metaphacts extended the visual exploration capabilities metaphactory – it’s Path Finder facility uses GraphDB’s Graph Path Search. You will learn more about statement level metadata , the pros and cons of RDF-star, how SPARQ-star works and how different RDF engines implement RDF-star. release.
Are you an aspiring data scientist , or just want to understand the benefits of integrating data catalogs with visualization tools? By combining the power of two solutions — data catalogs and data visualization tools — you can get a deeper understanding of your information landscape and create meaningful insights faster.
They value NiFi’s visual, no-code, drag-and-drop UI, the 450+ out-of-the-box processors and connectors, as well as the ability to interactively explore data by starting individual processors in the flow and immediately seeing the impact as data streams through the flow. . Enabling self-service for developers.
Additionally, it incorporates BMW Group’s internal system to integrate essential metadata, offering a comprehensive view of the data across various dimensions, such as group, department, product, and applications. Once released, consumers use datasets from different providers for analysis, machine learning (ML) workloads, and visualization.
Combining these analytics with AIOps health analytics, cybersecurity assessments, and system metadata, gives you insights to make the best sustainability decisions about workload consolidation to reduce your IT footprint and lower emissions and energy costs. Her career began in the semiconductor test industry.
Recently, Chhavi Yadav (NYU) and Leon Bottou (Facebook AI Research and NYU) indicated in their paper, “ Cold Case: The Lost MNIST Digits ”, how they reconstructed the MNIST (Modified National Institute of Standards and Technology) dataset and added 50,000 samples to the test set for a total of 60,000 samples. Did they overfit the test set?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content