This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This integration enables our customers to seamlessly explore data with AI in Tableau, build visualizations, and uncover insights hidden in their governed data, all while leveraging Amazon DataZone to catalog, discover, share, and govern data across AWS, on premises, and from third-party sources—enhancing both governance and decision-making.”
With automatic scorecards generated for your table groups, you can visualize data hygiene instantly. Better Metadata Management Add Descriptions and Data Product tags to tables and columns in the Data Catalog for improved governance. This game-changing capability brings more profound insights and greater control over your data health.
Content includes reports, documents, articles, presentations, visualizations, video, and audio representations of the insights and knowledge that have been extracted from data. Datasphere provides full-spectrum data governance: metadata management, data catalogs, data privacy, data quality, and data lineage (provenance) tracking.
way we package information has a lot to do with metadata. The somewhat conventional metaphor about metadata is the one of the library card. This metaphor has it that books are the data and library cards are the metadata helping us find what we need, want to know more about or even what we don’t know we were looking for.
What Is Metadata? Metadata is information about data. A clothing catalog or dictionary are both examples of metadata repositories. Indeed, a popular online catalog, like Amazon, offers rich metadata around products to guide shoppers: ratings, reviews, and product details are all examples of metadata.
In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient. You will learn about an open-source solution that can collect important metrics from the Iceberg metadata layer. This ensures that each change is tracked and reversible, enhancing data governance and auditability.
It can be used for something as visual as reducing traffic jams, to personalizing products and services, to improving the experience in multiplayer video games. We would like to talk about data visualization and its role in the big data movement. Data is useless without the opportunity to visualize what we are looking for.
Steve needed a robust and automated metadata management solution as part of his organization’s data governance strategy. Metadata in data governance. What many enterprises have not yet come to terms with when implementing their data governance strategy and supporting tools, is the criticality of metadata in the process.
We are excited to announce the preview of API-driven, OpenLineage-compatible data lineage in Amazon DataZone to help you capture, store, and visualize lineage of data movement and transformations of data assets on Amazon DataZone. The lineage visualized includes activities inside the Amazon DataZone business data catalog.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. This process is shown in the following figure.
OpenSearch Service stores different types of stored objects, such as dashboards, visualizations, alerts, security roles, index templates, and more, within the domain. As your user base and number of Amazon OpenSearch Service domains grow, tracking activities and changes to those saved objects becomes increasingly difficult.
These include internet-scale web and mobile applications, low-latency metadata stores, high-traffic retail websites, Internet of Things (IoT) and time series data, online gaming, and more. Table metadata, such as column names and data types, is stored using the AWS Glue Data Catalog. You don’t need to write any code. Choose Next.
The Institutional Data & AI platform adopts a federated approach to data while centralizing the metadata to facilitate simpler discovery and sharing of data products. A data portal for consumers to discover data products and access associated metadata. Subscription workflows that simplify access management to the data products.
This ability builds on the deep metadata context that Salesforce has across a variety of tasks. But whats new, according to Amalgam Insights chief analyst Hyoun Park, is Agent Builders ability to suggest agent topics and instructions.
That’s because it’s the best way to visualizemetadata , and metadata is now the heart of enterprise data management and data governance/ intelligence efforts. erwin DM 2020 is an essential source of metadata and a critical enabler of data governance and intelligence efforts. erwin Data Modeler: Where the Magic Happens.
Content management systems: Content editors can search for assets or content using descriptive language without relying on extensive tagging or metadata. This makes it possible to create dynamic, graphical user interfaces that visually represent complex information. and immediately receive relevant answers and visualizations.
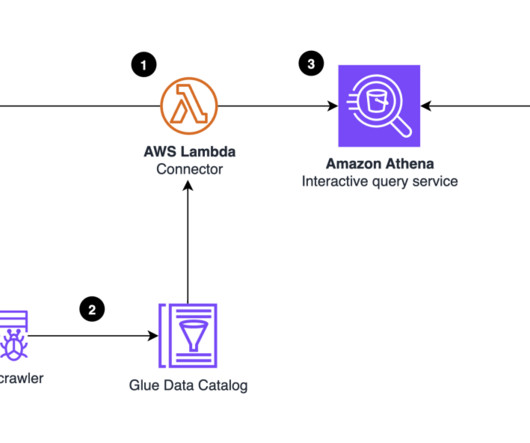
AWS Glue Studio visual editor provides a low-code graphic environment to build, run, and monitor extract, transform, and load (ETL) scripts. Crawlers explore data stores and auto-generate metadata to populate the Data Catalog, registering discovered tables in the Data Catalog. This saves time over manually defining schemas.
Some of the benefits are detailed below: Optimizing metadata for greater reach and branding benefits. One of the most overlooked factors is metadata. Metadata is important for numerous reasons. Search engines crawl metadata of image files, videos and other visual creative when they are indexing websites.
QuickSight makes it straightforward for business users to visualize data in interactive dashboards and reports. An AWS Glue crawler scans data on the S3 bucket and populates table metadata on the AWS Glue Data Catalog. You can deploy the end-to-end solution to visualize and analyze trends of the observability metrics.
They realized that the search results would probably not provide an answer to my question, but the results would simply list websites that included my words on the page or in the metadata tags: “Texas”, “Cows”, “How”, etc.
Choose the table to view the schema and other metadata. Select Visual with a source and target. Conclusion In this post, we showed how to set up an AWS Glue crawler to crawl over a MongoDB Atlas collection, gathering metadata and creating table records in the AWS Glue Data Catalog. Choose Create job.
As data sets become bigger, it becomes harder to visualize information. Data visualization enables you to: Make sense of the distributional characteristics of variables Easily identify data entry issues Choose suitable variables for data analysis Assess the outcome of predictive models Communicate the results to those interested.
In this post, we will explain the definition, connection, and differences between data warehousing and business intelligence , provide a BI architecture diagram that will visually explain the correlation of these terms, and the framework on which they operate. But first, let’s start with basic definitions. click to enlarge**.
Unraveling Data Complexities with Metadata Management. Metadata management will be critical to the process for cataloging data via automated scans. Essentially, metadata management is the administration of data that describes other data, with an emphasis on associations and lineage. Data lineage to support impact analysis.
Active metadata will play a critical role in automating such updates as they arise. His work produced control-flow graphs with nodes and edges as a visual representation of complexity. This approach ensures lineage is easy to visualize. The markup can be extracted and used in a wide array of visual tools.
With the ability to browse metadata, you can understand the structure and schema of the data source, identify relevant tables and fields, and discover useful data assets you may not be aware of. You can navigate to the projects Data page to visually verify the existence of the newly created table. Under Create job , choose Visual ETL.
Look for the Metadata. This metadata (read: data about your data) is key to tracking your data. In other words, kind of like Hansel and Gretel in the forest, your data leaves a trail of breadcrumbs – the metadata – to record where it came from and who it really is. Let’s Get Mapping.
The graph visually represents both non-missing (non-null) values and missing (null) values, allowing you to quickly identify which columns have incomplete data. Column Metadata – Provides information on the dataset’s recency, such as the last update and publication dates.
Amazon SageMaker Unified Studio brings together functionality and tools from the range of standalone studios, query editors, and visual tools available today in Amazon EMR , AWS Glue , Amazon Redshift , Amazon Bedrock , and the existing Amazon SageMaker Studio. With AWS Glue 5.0,
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
Data modeling is a process that enables organizations to discover, design, visualize, standardize and deploy high-quality data assets through an intuitive, graphical interface. Data models provide visualization, create additional metadata and standardize data design across the enterprise. What is Data Modeling? SQL or NoSQL?
And all of them are asking hard questions: “Can you integrate my data, with my particular format?”, “How well can you scale?”, “How many visualizations do you offer?”. You have to take care of data extraction, transformation and loading, and of visualization. Nowadays, data analytics doesn’t exist on its own. Inferring new knowledge.
With all these diverse metadata sources, it is difficult to understand the complicated web they form much less get a simple visual flow of data lineage and impact analysis. The metadata-driven suite automatically finds, models, ingests, catalogs and governs cloud data assets. GDPR, CCPA, HIPAA, SOX, PIC DSS).
Visualizing data from anywhere defined by its context and definition in a central model repository, as well as the rules for governing the use of those data elements, unifies enterprise data management. Provide metadata and schema visualization regardless of where data is stored. Create database designs from visual models.
The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day. The near-real-time insights can then be visualized as a performance dashboard using OpenSearch Dashboards. client("s3") S3_BUCKET = ' ' kinesis_client = boto3.client("kinesis")
It provides data catalog, automated crawlers, and visual job creation to streamline data integration across various data sources and targets. Business analysts enhance the data with business metadata/glossaries and publish the same as data assets or data products. Amazon Athena is used to query, and explore the data.
Solution overview Data and metadata discovery is one of the primary requirements in data analytics, where data consumers explore what data is available and in what format, and then consume or query it for analysis. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable.
This data needs to be ingested into a data lake, transformed, and made available for analytics, machine learning (ML), and visualization. To share the datasets, they needed a way to share access to the data and access to catalog metadata in the form of tables and views. The target accounts read data from the source account S3 buckets.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. We enhanced support for querying Apache Iceberg data and improved the performance of querying Iceberg up to threefold year-over-year.
Metadata is the basis of trust for data forensics as we answer the questions of fact or fiction when it comes to the data we see. Being that AI is comprised of more data than code, it is now more essential than ever to combine data with metadata in near real-time. And lets not forget about the controls.
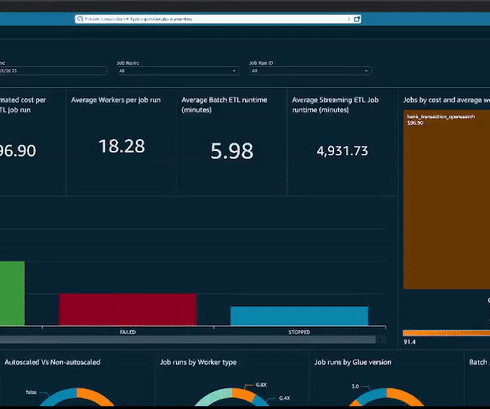
In this post, we explore how to combine AWS Glue usage information and metrics with centralized reporting and visualization using QuickSight. You have metrics available per job run within the AWS Glue console, but they don’t cover all available AWS Glue job metrics, and the visuals aren’t as interactive compared to the QuickSight dashboard.
Most data governance tools today start with the slow, waterfall building of metadata with data stewards and then hope to use that metadata to drive code that runs in production. In reality, the ‘active metadata’ is just a written specification for a data developer to write their code.
Execution of this mission requires the contribution of several groups: data center/IT, data engineering, data science, data visualization, and data governance. Data Visualization, Preparation – Self-service tools sucha as Tableau, Alteryx. Data Visualization, Preparation – Self-service tools sucha as Tableau, Alteryx.
The data architect is responsible for visualizing and designing an organization’s enterprise data management framework. Data architects and data engineers work together to visualize and build the enterprise data management framework. In some ways, the data architect is an advanced data engineer.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content