This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post How to Create a Test Set to Approximate Business Metrics Offline appeared first on Analytics Vidhya. Introduction Most Kaggle-like machine learning hackathons miss a core aspect of a machine learning workflow – preparing an offline evaluation environment while building an.
This article was published as a part of the Data Science Blogathon Introduction With ignite, you can write loops to train the network in just a few lines, add standard metrics calculation out of the box, save the model, etc. The post Training and Testing Neural Networks on PyTorch using Ignite appeared first on Analytics Vidhya.
The Model development process undergoes multiple iterations and finally, a model which has acceptable performance metrics on test data is taken to the production […]. The post Deploying ML Models Using Kubernetes appeared first on Analytics Vidhya.
A look at the landscape of tools for building and deploying robust, production-ready machine learning models. We are also beginning to see researchers share sample code written in popular open source libraries, and some even share pre-trained models. Model development. Model governance. Source: Ben Lorica.
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. What breaks your app in production isnt always what you tested for in dev! The way out?
Data Observability and Data Quality Testing Certification Series We are excited to invite you to a free four-part webinar series that will elevate your understanding and skills in Data Observation and Data Quality Testing. Register for free today and take the first step towards mastering data observability and quality testing!
Recall the following key attributes of a machine learning project: Unlike traditional software where the goal is to meet a functional specification , in ML the goal is to optimize a metric. We are still in the early days for tools supporting teams developing machine learning models. Model governance. there aren’t enough of them.
Introduction Evaluation of models and medical tests is significant in both data science and medicine. However, these two domains use different metrics, which is confusing. When it comes to the relationship between these metrics, they differ.
Understanding and tracking the right software delivery metrics is essential to inform strategic decisions that drive continuous improvement. They achieve this through models, patterns, and peer review taking complex challenges and breaking them down into understandable components that stakeholders can grasp and discuss.
The world changed on November 30, 2022 as surely as it did on August 12, 1908 when the first Model T left the Ford assembly line. If we want prosocial outcomes, we need to design and report on the metrics that explicitly aim for those outcomes and measure the extent to which they have been achieved.
6) Data Quality Metrics Examples. Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. These needs are then quantified into data models for acquisition and delivery. Table of Contents. 1) What Is Data Quality Management?
Testing and Data Observability. DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. Testing and Data Observability.
Solution overview The MSK clusters in Hydro are configured with a PER_TOPIC_PER_BROKER level of monitoring, which provides metrics at the broker and topic levels. These metrics help us determine the attributes of the cluster usage effectively. We then match these attributes to the relevant MSK metrics available.
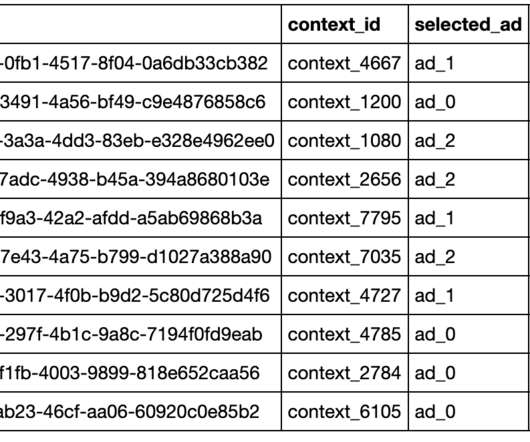
From obscurity to ubiquity, the rise of large language models (LLMs) is a testament to rapid technological advancement. Just a few short years ago, models like GPT-1 (2018) and GPT-2 (2019) barely registered a blip on anyone’s tech radar. In our real-world case study, we needed a system that would create test data.
While there is a lot of effort and content that is now available, it tends to be at a higher level which will require work to be done to create a governance model specifically for your organization. Governance is action and there are many actions an organization can take to create and implement an effective AI governance model.
Using the companys data in LLMs, AI agents, or other generative AI models creates more risk. What CIOs can do: Avoid and reduce data debt by incorporating data governance and analytics responsibilities in agile data teams , implementing data observability , and developing data quality metrics.
Similarly, in “ Building Machine Learning Powered Applications: Going from Idea to Product ,” Emmanuel Ameisen states: “Indeed, exposing a model to users in production comes with a set of challenges that mirrors the ones that come with debugging a model.”. Debugging AI Products.
The best way to ensure error-free execution of data production is through automated testing and monitoring. The DataKitchen Platform enables data teams to integrate testing and observability into data pipeline orchestrations. Automated tests work 24×7 to ensure that the results of each processing stage are accurate and correct.
The company’s business analysts want to generate metrics to identify ticket movement over time, success rates for sellers, and the best-selling events, venues, and seasons. After the data is in Amazon Redshift, dbt models are used to transform the raw data into key metrics such as ticket trends, seller performance, and event popularity.
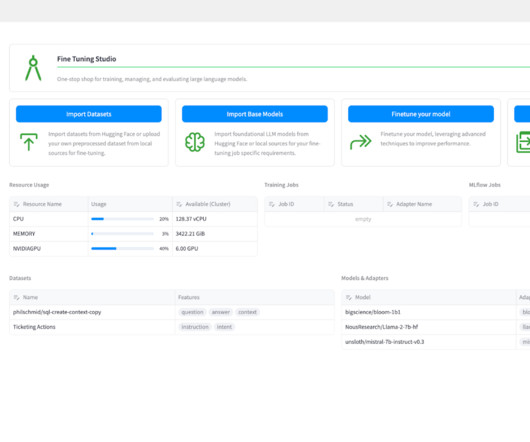
Large Language Models (LLMs) will be at the core of many groundbreaking AI solutions for enterprise organizations. These enable customer service representatives to focus their time and attention on more high-value interactions, leading to a more cost-efficient service model. The Need for Fine Tuning Fine tuning solves these issues.
1) What Are Product Metrics? 2) Types Of Product Metrics. 3) Product Metrics Examples You Can Use. 4) Product Metrics Framework. The right product performance metrics will give you invaluable insights into its health, strength and weaknesses, potential issues or bottlenecks, and let you improve it greatly.
Experimentation: It’s just not possible to create a product by building, evaluating, and deploying a single model. In reality, many candidate models (frequently hundreds or even thousands) are created during the development process. Modelling: The model is often misconstrued as the most important component of an AI product.
In many cases, companies should opt for closed, proprietary AI models that arent connected to the internet, ensuring that critical data remains secure within the enterprise. Soby recommends testing the enterprises current risk management program against real-world incidents.
When considering the performance of any forecasting model, the prediction values it produces must be evaluated. This is done by calculating suitable error metrics. An error metric is a way to quantify the performance of a model and provides a way for the forecaster to quantitatively compare different models 1.
Key AI companies have told the UK government to speed up its safety testing for their systems, raising questions about future government initiatives that too may hinge on technology providers opening up generative AI models to tests before new releases hit the public.
It’s often stated that nothing changes inside an enterprise because you’ve built a model. In some cases, data science does generate models directly to revenue, such as a contextual deal engine that targets people with offers that they can instantly redeem. But what about good decisions?
Even for experienced developers and data scientists, the process of developing a model could involve stringing together many steps from many packages, in ways that might not be as elegant or efficient as one might like. the experience is still rooted in the same goal: simple efficiency for the whole model development lifecycle.
Instead of writing code with hard-coded algorithms and rules that always behave in a predictable manner, ML engineers collect a large number of examples of input and output pairs and use them as training data for their models. This has serious implications for software testing, versioning, deployment, and other core development processes.
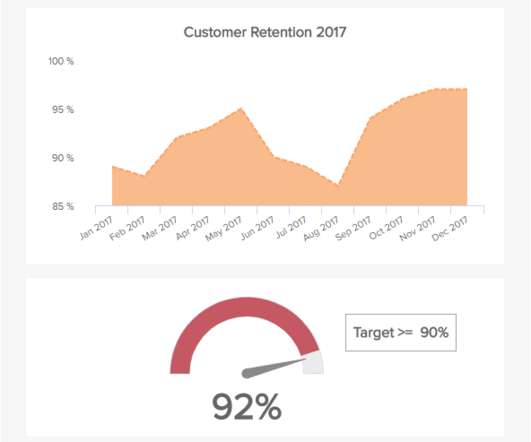
Analytics data can be very useful for companies trying to create profitable online business models. Pay attention to the following metrics in your analytics dashboard to help you achieve greater success with your store. This metric is the average number you have to put in to get new customers. Audience Information.
Model developers will test for AI bias as part of their pre-deployment testing. Quality test suites will enforce “equity,” like any other performance metric. Continuous testing, monitoring and observability will prevent biased models from deploying or continuing to operate. Companies Commit to Remote.
But wait, she asks you for your team metrics. Where is your metrics report? What are the metrics that matter? Gartner attempted to list every metric under the sun in their recent report , “T oolkit: Delivery Metrics for DataOps, Self-Service Analytics, ModelOps, and MLOps, ” published February 7, 2023.
Centralizing analytics helps the organization standardize enterprise-wide measurements and metrics. With a standard metric supported by a centralized technical team, the organization maintains consistency in analytics. Develop/execute regression testing . Test data management and other functions provided ‘as a service’ .
A high-quality testing platform easily integrates with all the data analytics and optimization solutions that QA teams use in their work and simplifies testing process, collects all reporting and analytics in one place, can significantly improve team productivity, and speeds up the release. This is not entirely true. Data reporting.
Key Success Metrics, Benefits, and Results for Data Observability Using DataKitchen Software Lowering Serious Production Errors Key Benefit Errors in production can come from many sources – poor data, problems in the production process, being late, or infrastructure problems. Tests assess important questions, such as “Is the data correct?”
GSK had been pursuing DataOps capabilities such as automation, containerization, automated testing and monitoring, and reusability, for several years. Furthermore, the introduction of AI and ML models hastened the need to be more efficient and effective in deploying new technologies. Multiple Metrics for Success.
These organizations often maintain multiple AWS accounts for development, testing, and production stages, leading to increased complexity and cost. Additionally, customers adopting a federated deployment model find it challenging to provide isolated environments for different teams or departments, and at the same time optimize cost.
Data quality for AI needs to cover bias detection, infringement prevention, skew detection in data for model features, and noise detection. Not all columns are equal, so you need to prioritize cleaning data features that matter to your model, and your business outcomes. asks Friedman.
Building Models. A common task for a data scientist is to build a predictive model. You’ll try this with a few other algorithms, and their respective tuning parameters–maybe even break out TensorFlow to build a custom neural net along the way–and the winning model will be the one that heads to production.
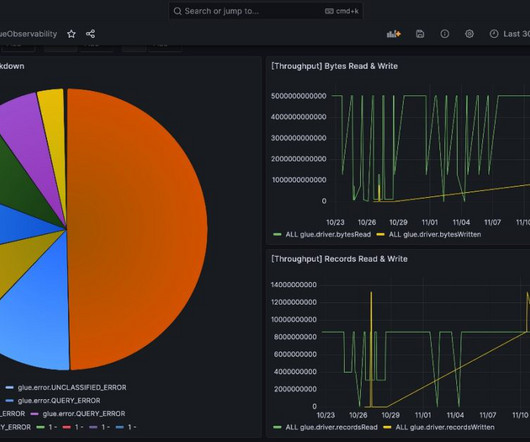
AWS Glue has made this more straightforward with the launch of AWS Glue job observability metrics , which provide valuable insights into your data integration pipelines built on AWS Glue. This post, walks through how to integrate AWS Glue job observability metrics with Grafana using Amazon Managed Grafana. Choose Save & test.
The data scientists need to find the right data as inputs for their models — they also need a place to write-back the outputs of their models to the data repository for other users to access. The semantic layer bridges the gaps between the data cloud, the decision-makers, and the data science modelers.
To unlock the full potential of AI, however, businesses need to deploy models and AI applications at scale, in real-time, and with low latency and high throughput. The Cloudera AI Inference service is a highly scalable, secure, and high-performance deployment environment for serving production AI models and related applications.
Even if all the code runs and the model seems to be spitting out reasonable answers, it’s possible for a model to encode fundamental data science mistakes that invalidate its results. These errors might seem small, but the effects can be disastrous when the model is used to make decisions in the real world.
One is going through the big areas where we have operational services and look at every process to be optimized using artificial intelligence and large language models. But a substantial 23% of respondents say the AI has underperformed expectations as models can prove to be unreliable and projects fail to scale.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content