This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this article, we will learn about model explainability and the different ways to interpret a machine learning model. What is Model Explainability? Model explainability refers to the concept of being able to understand the machine learning model. For example – If a healthcare […].
Introduction Machine learning models have come a long way in the past few decades but still face several challenges, including robustness. Robustness refers to the ability of a model to work well on unseen data, an essential requirement for real-world applications.
ArticleVideo Book Hierarchical Modelling Hierarchical modeling also referred to as a nested model, deals with data with the observations in a certain group. The post Mixed-effect Regression for Hierarchical Modeling (Part 1) appeared first on Analytics Vidhya.
In the last article, we have talked about Building Search Engines using NLP concepts if you haven’t read it, refer to this link. The post X-Ray Classification Using Pretrained-Stacked Model appeared first on Analytics Vidhya.
Introduction Virtual reality refers to a simulation generated by a computer which allows user interaction with the use of special headsets. In simple words, The post Virtual Reality for the Web: A-Frame(Creating 3D models from Images) appeared first on Analytics Vidhya.
AI models have advanced significantly, showcasing their ability to perform extraordinary tasks. However, these intelligent systems are not immune to errors and can occasionally generate incorrect responses, often referred to as “hallucinations.”
Apply fair and private models, white-hat and forensic model debugging, and common sense to protect machine learning models from malicious actors. Like many others, I’ve known for some time that machine learning models themselves could pose security risks. This is like a denial-of-service (DOS) attack on your model itself.
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., at Facebook—both from 2020.
The Evolution of Expectations For years, the AI world was driven by scaling laws : the empirical observation that larger models and bigger datasets led to proportionally better performance. This fueled a belief that simply making models bigger would solve deeper issues like accuracy, understanding, and reasoning.
Introduction Random Forests are always referred to as black-box models. This article was published as a part of the Data Science Blogathon. Let’s try. The post Lets Open the Black Box of Random Forests appeared first on Analytics Vidhya.
Users can upload documents, and the chatbot can answer questions by referring to those documents. The interface will be generated using Streamlit, and the chatbot will use open-source Large Language Model (LLM) models, making […] The post RAG and Streamlit Chatbot: Chat with Documents Using LLM appeared first on Analytics Vidhya.
Small language models and edge computing Most of the attention this year and last has been on the big language models specifically on ChatGPT in its various permutations, as well as competitors like Anthropics Claude and Metas Llama models.
For example, Whisper correctly transcribed a speaker’s reference to “two other girls and one lady” but added “which were Black,” despite no such racial context in the original conversation. Whisper is not the only AI model that generates such errors. This phenomenon, known as hallucination, has been documented across various AI models.
Developing AI When most people think about artificial intelligence, they likely imagine a coder hunched over their workstation developing AI models. With those tools involved, users can build new AI models on relatively low-powered machines, saving heavy-duty units for the compute-intensive process of model training.
classification refers to a predictive modeling problem where a class label is predicted for a given example of […]. Introduction In this article, we are going to solve the Loan Approval Prediction Hackathon hosted by Analytics Vidhya. The post Loan Approval Prediction Machine Learning appeared first on Analytics Vidhya.
To solve the problem, the company turned to gen AI and decided to use both commercial and open source models. With security, many commercial providers use their customers data to train their models, says Ringdahl. Thats one of the catches of proprietary commercial models, he says. Its possible to opt-out, but there are caveats.
The successful ones choose zero trust architecture rather than the network-centric, perimeter-based security models that are unequipped to face the threats of the digital era. Traditional security models: Whats the risk? In addition to these four major weaknesses, network-centric models have other challenges.
Introduction This article concerns building a system based upon LLM (Large language model) with the ChatGPT AI-1. To have an insight into the concepts, one may refer to: [link] This article will adopt a step-by-step approach. It is expected that readers are aware of the basics of Prompt Engineering.
Guan, along with AI leaders from S&P Global and Corning, discussed the gargantuan challenges involved in moving gen AI models from proof of concept to production, as well as the foundation needed to make gen AI models truly valuable for the business. Their main intent is to change perception of the brand.
Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. In this post, we use dbt for data modeling on both Amazon Athena and Amazon Redshift. In this post, we use dbt for data modeling on both Amazon Athena and Amazon Redshift.
Generative AI models are trained on large repositories of information and media. They are then able to take in prompts and produce outputs based on the statistical weights of the pretrained models of those corpora. The newest Answers release is again built with an open source model—in this case, Llama 3.
Large language models that emerge have no set end date, which means employees’ personal data that is captured by enterprise LLMs will remain part of the LLM not only during their employment, but after their employment. CMOs view GenAI as a tool that can launch both new products and business models.
Introduction Hallucination in large language models (LLMs) refers to the generation of information that is factually incorrect, misleading, or fabricated. Despite their impressive capabilities in generating coherent and contextually relevant text, LLMs sometimes produce outputs that diverge from reality.
As a NoSQL solution, DynamoDB is optimized for compute (as opposed to storage) and therefore the data needs to be modeled and served up to the application based on how the application needs it. DynamoDB is a managed NoSQL database solution that acts as a key-value store for transactional data.
In robotics, sim-to-real transfer refers to transferring policies learned in simulation to the real world. Introduction Have you ever thought robots would learn independently with the power of LLMs? It’s happening now! DrEureka is automating sim-to-real design in robotics.
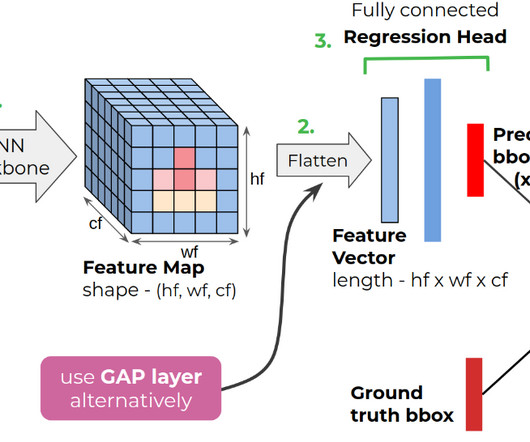
Introduction Object Localization refers to the task of precisely identifying and localizing objects of interest within an image. It plays a crucial role in computer vision applications, enabling tasks like object detection, tracking, and segmentation.
Introduction Bike-sharing demand analysis refers to the study of factors that impact the usage of bike-sharing services and the demand for bikes at different times and locations. The purpose of this analysis is to understand the patterns and trends in bike usage and make predictions about future demand.
Custom context enhances the AI model’s understanding of your specific data model, business logic, and query patterns, allowing it to generate more relevant and accurate SQL recommendations. Your queries, data and database schemas are not used to train a generative AI foundational model (FM).
Responsible AI refers to the sustainable […] The post How to Build a Responsible AI with TensorFlow? With the pace at which AI is developing, ensuring the technology is safe has become increasingly important. This is where responsible AI comes into the picture. appeared first on Analytics Vidhya.
Lakehouse allows you to use preferred analytics engines and AI models of your choice with consistent governance across all your data. SageMaker Lakehouse offers integrated access controls and fine-grained permissions that are consistently applied across all analytics engines and AI models and tools.
It’s important to understand that ChatGPT is not actually a language model. It’s a convenient user interface built around one specific language model, GPT-3.5, is one of a class of language models that are sometimes called “large language models” (LLMs)—though that term isn’t very helpful. with specialized training.
The dominant references everywhere to Observability was just the start of awesome brain food offered at Splunk’s.conf22 event. Reference ) The latest updates to the Splunk platform address the complexities of multi-cloud and hybrid environments, enabling cybersecurity and network big data functions (e.g., is here, now!
TIAA has launched a generative AI implementation, internally referred to as “Research Buddy,” that pulls together relevant facts and insights from publicly available documents for Nuveen, TIAA’s asset management arm, on an as-needed basis. You use a model and then inject the content at the last minute when you need it,” Gualtieri explains.
Pure Storage empowers enterprise AI with advanced data storage technologies and validated reference architectures for emerging generative AI use cases. See additional references and resources at the end of this article. OVX Validated Reference Architecture for AI-ready Infrastructures First question: What is OVX validation?
” I, thankfully, learned this early in my career, at a time when I could still refer to myself as a software developer. Building Models. A common task for a data scientist is to build a predictive model. You might say that the outcome of this exercise is a performant predictive model. That’s sort of true.
Language understanding benefits from every part of the fast-improving ABC of software: AI (freely available deep learning libraries like PyText and language models like BERT ), big data (Hadoop, Spark, and Spark NLP ), and cloud (GPU's on demand and NLP-as-a-service from all the major cloud providers). They don’t have a subject.
Let’s start by considering the job of a non-ML software engineer: writing traditional software deals with well-defined, narrowly-scoped inputs, which the engineer can exhaustively and cleanly model in the code. Not only is data larger, but models—deep learning models in particular—are much larger than before.
However, despite the ease with which individuals can use AI as a result of natural language processing , creating and managing AI models is still a challenge. The process of managing all these parts is referred to as Machine Learning Operations or MLOps. First, there is a shortage of skills.
Large language model (LLM)-based generative AI is a new technology trend for comprehending a large corpora of information and assisting with complex tasks. Generative AI models can translate natural language questions into valid SQL queries, a capability known as text-to-SQL generation. Choose Manage model access.
We are now deciphering rules from patterns in data, embedding business knowledge into ML models, and soon, AI agents will leverage this data to make decisions on behalf of companies. By modern, I refer to an engineering-driven methodology that fully capitalizes on automation and software engineering best practices.
Claude 2 has a maximum context—the upper limit on the amount of text it can consider at one time—of 100,000 tokens 1 ; at this time, all other large language models are significantly smaller. Is a language model up to that? Large language models don’t help with that now, though they might in the future. It certainly does.
Chain-of-thought prompts often include some examples of problems, procedures, and solutions that are done correctly, giving the AI a model to emulate. Is every reference correct and—even more important—does it exist? Most AIs will use that information to train future versions of the model.
And everyone has opinions about how these language models and art generation programs are going to change the nature of work, usher in the singularity, or perhaps even doom the human race. 16% of respondents working with AI are using open source models. A few have even tried out Bard or Claude, or run LLaMA 1 on their laptop.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content