This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
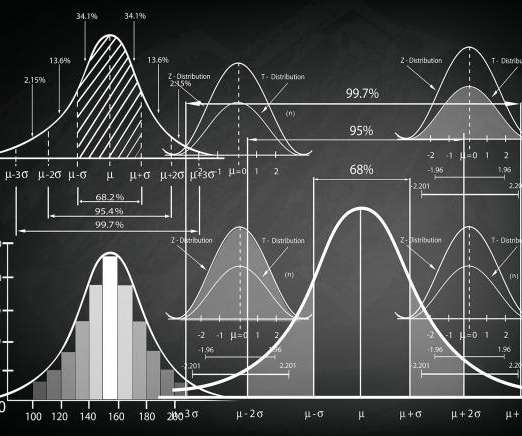
This article was published as a part of the Data Science Blogathon Introduction to StatisticsStatistics is a type of mathematical analysis that employs quantified models and representations to analyse a set of experimental data or real-world studies. Data processing is […].
What is a StatisticalModel? “Modeling is an art, as well as. The post All about StatisticalModeling appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Logistic Regression, a statisticalmodel is a very popular and. The post 20+ Questions to Test your Skills on Logistic Regression appeared first on Analytics Vidhya.
Table of contents Introduction Multilevel Models Advantages of Multilevel models When do we use Multilevel Models Types of Multilevel Model Random intercept model Random coefficient model Hypothesis testing: Likelihood Ratio Testing End-Note Introduction Suppose, you have a dataset of faculty salaries of a university […].
Introduction Let me take you into the universe of chi-square tests and how we can involve them in Python with the scipy library. We’ll be going over the chi-square integrity of the fit test.
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
Introduction Cross-validation is a machine learning technique that evaluates a model’s performance on a new dataset. It involves dividing a training dataset into multiple subsets and testing it on a new set. This prevents overfitting by encouraging the model to learn underlying trends associated with the data.
Introduction In order to build machine learning models that are highly generalizable to a wide range of test conditions, training models with high-quality data is essential. Unfortunately, a large part of the data collected is not readily ideal for training machine learning models, this increases […].
That’s what beta tests are for. Large language models like ChatGPT and Google’s LaMDA aren’t designed to give correct results. Remember that these tools aren’t doing math, they’re just doing statistics on a huge body of text. So it’s not surprising that things are wrong.
The hype around large language models (LLMs) is undeniable. Think about it: LLMs like GPT-3 are incredibly complex deep learning models trained on massive datasets. Even basic predictive modeling can be done with lightweight machine learning in Python or R. In life sciences, simple statistical software can analyze patient data.
And everyone has opinions about how these language models and art generation programs are going to change the nature of work, usher in the singularity, or perhaps even doom the human race. 16% of respondents working with AI are using open source models. A few have even tried out Bard or Claude, or run LLaMA 1 on their laptop.
If the output of a model can’t be owned by a human, who (or what) is responsible if that output infringes existing copyright? In an article in The New Yorker , Jaron Lanier introduces the idea of data dignity, which implicitly distinguishes between training a model and generating output using a model.
Product Managers are responsible for the successful development, testing, release, and adoption of a product, and for leading the team that implements those milestones. You must detect when the model has become stale, and retrain it as necessary. The Core Responsibilities of the AI Product Manager. The AI Product Development Process.
A data scientist must be skilled in many arts: math and statistics, computer science, and domain knowledge. Statistics and programming go hand in hand. Mastering statistical techniques and knowing how to implement them via a programming language are essential building blocks for advanced analytics. Linear regression.
Under school district policy, each of Audrey’s eleven- and twelve-year old students is tested at least three times a year to determine his or her Lexile, a number between 200 and 1,700 that reflects how well the student can read. They test each student’s grasp of a particular sentence or paragraph—but not of a whole story.
A high-quality testing platform easily integrates with all the data analytics and optimization solutions that QA teams use in their work and simplifies testing process, collects all reporting and analytics in one place, can significantly improve team productivity, and speeds up the release. This is not entirely true. Data reporting.
Last month, TheNew York Times claimed that tech giants OpenAI and Google have waded into a copyright gray area by transcribing the vast volume of YouTube videos and using that text as additional training data for their AI models despite terms of service that prohibit such efforts and copyright law that the Times argues places them in dispute.
This capability can be useful while performing tasks like backtesting, model validation, and understanding data lineage. You can refer to this metadata layer to create a mental model of how Icebergs time travel capability works. Also, the time travel feature can further mitigate any risks of lookahead bias.
DeepMind’s Gato is an AI model that can be taught to carry out many different kinds of tasks based on a single transformer neural network. The achievement of note is that it’s underpinned by a single model trained across all tasks rather than different models for different tasks and modalities. billion parameters.
Some will argue that observability is nothing more than testing and monitoring applications using tests, metrics, logs, and other artifacts. Since 2008, teams working for our founding team and our customers have delivered 100s of millions of data sets, dashboards, and models with almost no errors. Tie tests to alerts.
It’s important to understand that ChatGPT is not actually a language model. It’s a convenient user interface built around one specific language model, GPT-3.5, is one of a class of language models that are sometimes called “large language models” (LLMs)—though that term isn’t very helpful. with specialized training.
For a model-driven enterprise, having access to the appropriate tools can mean the difference between operating at a loss with a string of late projects lingering ahead of you or exceeding productivity and profitability forecasts. What Are Modeling Tools? Importance of Modeling Tools. Types of Modeling Tools.
Generative AI models are trained on large repositories of information and media. They are then able to take in prompts and produce outputs based on the statistical weights of the pretrained models of those corpora. The newest Answers release is again built with an open source model—in this case, Llama 3.
Additionally, incorporating a decision support system software can save a lot of company’s time – combining information from raw data, documents, personal knowledge, and business models will provide a solid foundation for solving business problems. There are basically 4 types of scales: *Statistics Level Measurement Table*.
In internal tests, AI-driven scaling and optimizations showcased up to 10 times price-performance improvements for variable workloads. Lakehouse allows you to use preferred analytics engines and AI models of your choice with consistent governance across all your data.
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. This has serious implications for software testing, versioning, deployment, and other core development processes. Machine learning adds uncertainty.
TL;DR LLMs and other GenAI models can reproduce significant chunks of training data. Researchers are finding more and more ways to extract training data from ChatGPT and other models. And the space is moving quickly: SORA , OpenAI’s text-to-video model, is yet to be released and has already taken the world by storm.
These AI applications are essentially deep machine learning models that are trained on hundreds of gigabytes of text and that can provide detailed, grammatically correct, and “mostly accurate” text responses to user inputs (questions, requests, or queries, which are called prompts). Guess what? It isn’t.
Business analytics is the practical application of statistical analysis and technologies on business data to identify and anticipate trends and predict business outcomes. Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, data transformation, data modeling, and more.
Key statistics highlight the severity of the issue: 57% of respondents in a 2024 dbt Labs survey rated data quality as one of the three most challenging aspects of data preparation (up from 41% in 2023). Automating Data Quality Tests : Automation is essential for scaling data quality efforts.
Statistical methods for analyzing this two-dimensional data exist. MANOVA, for example, can test if the heights and weights in boys and girls is different. This statisticaltest is correct because the data are (presumably) bivariate normal. The accuracy of any predictive model approaches 100%. Data Has Properties.
Recall from my previous blog post that all financial models are at the mercy of the Trinity of Errors , namely: errors in model specifications, errors in model parameter estimates, and errors resulting from the failure of a model to adapt to structural changes in its environment.
In recent posts, we described requisite foundational technologies needed to sustain machine learning practices within organizations, and specialized tools for model development, model governance, and model operations/testing/monitoring. Sources of model risk. Model risk management. Image by Ben Lorica.
The chief aim of data analytics is to apply statistical analysis and technologies on data to find trends and solve problems. Data analytics draws from a range of disciplines — including computer programming, mathematics, and statistics — to perform analysis on data in an effort to describe, predict, and improve performance.
Large language model (LLM)-based generative AI is a new technology trend for comprehending a large corpora of information and assisting with complex tasks. Generative AI models can translate natural language questions into valid SQL queries, a capability known as text-to-SQL generation. Choose Manage model access.
With the big data revolution of recent years, predictive models are being rapidly integrated into more and more business processes. When business decisions are made based on bad models, the consequences can be severe. As machine learning advances globally, we can only expect the focus on model risk to continue to increase.
After developing a machine learning model, you need a place to run your model and serve predictions. If your company is in the early stage of its AI journey or has budget constraints, you may struggle to find a deployment system for your model. Also, a column in the dataset indicates if each flight had arrived on time or late.
Given a student’s performance using big organizations and institutions, it can be difficult to come up with a Student performance analysis and prediction system that is accurate across all models. […] The post Student Performance Analysis and Prediction appeared first on Analytics Vidhya.
Classical statistics, developed in the 20 th century for small datasets, do not work for data where the number of variables is much larger than the number of samples (Large P Small N, Curse of Dimensionality, or P >> N data). Predictive models fit to noise approach 100% accuracy. IL-17F, IL-17A, IL-21, IL-22, IL-23, IL-12p40.
Modern machine learning and back-testing; how quant hedge funds use it. Similarly, hedge funds often use modern machine learning and back-testing to analyze their quant models. Here, the models get tested using historical data to evaluate their profitability. Mathematical Model-based Strategies.
More often than not, it involves the use of statisticalmodeling such as standard deviation, mean and median. Let’s quickly review the most common statistical terms: Mean: a mean represents a numerical average for a set of responses. To cut costs and reduce test time, Intel implemented predictive data analyses.
A DSS leverages a combination of raw data, documents, personal knowledge, and/or business models to help users make decisions. According to Gartner, the goal is to design, model, align, execute, monitor, and tune decision models and processes. Model-driven DSS. They emphasize access to and manipulation of a model.
There are no automated tests , so errors frequently pass through the pipeline. There is no process to spin up an isolated dev environment to quickly add a feature, test it with actual data and deploy it to production. The pipeline has automated tests at each step, making sure that each step completes successfully.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content