This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Snapshots are crucial for data backup and disaster recovery in Amazon OpenSearch Service. These snapshots allow you to generate backups of your domain indexes and cluster state at specific moments and save them in a reliable storage location such as Amazon Simple Storage Service (Amazon S3). Snapshots are not instantaneous.
We will also cover the pattern with automatic compaction through AWS Glue Data Catalog table optimization. Consider a streaming pipeline ingesting real-time event data while a scheduled compaction job runs to optimize file sizes. Transaction 1 successfully updates the tables latest snapshot in the Iceberg catalog from 0 to 1.
The adoption of open table formats is a crucial consideration for organizations looking to optimize their data management practices and extract maximum value from their data. For more details, refer to Iceberg Release 1.6.1. Branching Branches are independent lineage of snapshot history that point to the head of each lineage.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. You can refer to this metadata layer to create a mental model of how Icebergs time travel capability works.
The AWS Glue Data Catalog now enhances managed table optimization of Apache Iceberg tables by automatically removing data files that are no longer needed. Along with the Glue Data Catalog’s automated compaction feature, these storage optimizations can help you reduce metadata overhead, control storage costs, and improve query performance.
Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. Referring to the data dictionary and screenshots, its evident that the complete data lineage information is highly dispersed, spread across 29 lineage diagrams. where(outV().as('a')),
Systems of this nature generate a huge number of small objects and need attention to compact them to a more optimal size for faster reading, such as 128 MB, 256 MB, or 512 MB. For more information on streaming applications on AWS, refer to Real-time Data Streaming and Analytics. We use the Hive catalog for Iceberg tables.
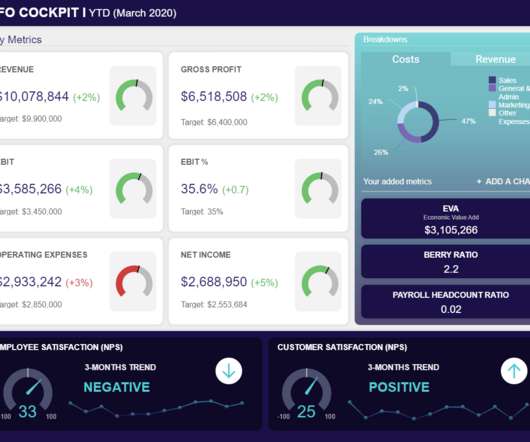
By including this cohesive mix of visual information, every CFO, regardless of sector, can gain a clear snapshot of the company’s fiscal performance within the first quarter of the year. Once you have set your aims, goals, and outcomes, you will be able to select CFO dashboard KPIs that will help you optimize your efforts.
Impala Optimizations for Small Queries. We’ll discuss the various phases Impala takes a query through and how small query optimizations are incorporated into the design of each phase. For a more in-depth description of these phases please refer to Impala: A Modern, Open-Source SQL Engine for Hadoop. Query Planner Design.
Amazon OpenSearch Service introduced the OpenSearch Optimized Instances (OR1) , deliver price-performance improvement over existing instances. For more details about OR1 instances, refer to Amazon OpenSearch Service Under the Hood: OpenSearch Optimized Instances (OR1). OR1 instances use a local and a remote store.
We’ve already discussed how checkpoints, when triggered by the job manager, signal all source operators to snapshot their state, which is then broadcasted as a special record called a checkpoint barrier. When barriers from all upstream partitions have arrived, the sub-task takes a snapshot of its state.
but to reference concrete tooling used today in order to ground what could otherwise be a somewhat abstract exercise. To manage the dynamism, we can resort to taking snapshots that represent immutable points in time: of models, of data, of code, and of internal state. However, none of these layers help with modeling and optimization.
These formats enable ACID (atomicity, consistency, isolation, durability) transactions, upserts, and deletes, and advanced features such as time travel and snapshots that were previously only available in data warehouses. For more information, refer to Amazon S3: Allows read and write access to objects in an S3 Bucket.
In this post, we look into an optimal and cost-effective way of incorporating dbt within Amazon Redshift. In an optimal environment, we store the credentials in AWS Secrets Manager and retrieve them. For more information, refer SQL models. For more information, refer to Redshift set up.
Refer to Upgrading Applications and Flink Versions for more information about how to avoid any unexpected inconsistencies. Refer to General best practices and recommendations for more details on how to test the upgrade process itself. If you’re using Gradle, refer to How to use Gradle to configure your project.
This blog discusses a few problems that you might encounter with Iceberg tables and offers strategies on how to optimize them in each of those scenarios. Problem with too many snapshots Everytime a write operation occurs on an Iceberg table, a new snapshot is created. See Write properties.
When you build your transactional data lake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 data lake to optimize the production environment. For more information, refer to Retry Amazon S3 requests with EMRFS. This property is set to true by default.
This means that cost-optimization exercises can happen at any time—they no longer need to happen in the planning phase. These scalable properties of Apache Flink can be key to optimizing your cost in the cloud. The third cost component is durable application backups, or snapshots. per GB per month.
You can use this solution regularly as part of your cost-optimization efforts to safely remove unused EIPs to reduce your costs. To gather EIP usage reporting, this solution compares snapshots of the current EIPs, focusing on their most recent attachment within a customizable 3-month period.
OpenSearch Serverless optimizes resource use depending on the type you set. Refer to Introducing the vector engine for Amazon OpenSearch Serverless, now in preview for more information about the new vector search option with OpenSearch Serverless. When you create a serverless collection, you set a collection type.
This helps traders determine the potential profitability of a strategy and identify any risks associated with it, enabling them to optimize it for better performance. To avoid look-ahead bias in backtesting, it’s essential to create snapshots of the data at different points in time. Load the dataset into Amazon S3.
With the launch of Amazon Redshift Serverless and the various provisioned instance deployment options , customers are looking for tools that help them determine the most optimal data warehouse configuration to support their Amazon Redshift workloads. Launch the producer warehouse by restoring the snapshot to a 32 RPU serverless namespace.
Example: Recrawl Logic within Google search Google search works because our software has previously crawled many billions of web pages, that is, scraped and snapshotted each one. These snapshots comprise what we refer to as our search index. This results in a poor user experience.
Whenever there is an update to the Iceberg table, a new snapshot of the table is created, and the metadata pointer points to the current table metadata file. At the top of the hierarchy is the metadata file, which stores information about the table’s schema, partition information, and snapshots.
Despite these capabilities, data lakes are not databases, and object storage does not provide support for ACID processing semantics, which you may require to effectively optimize and manage your data at scale across hundreds or thousands of users using a multitude of different technologies.
Athena also supports the ability to create views and perform VACUUM (snapshot expiration) on Apache Iceberg tables to optimize storage and performance. This was a challenge because data lakes are based on files and have been optimized for appending data. However, this requires knowledge of a table’s current snapshots.
To put our definition into a real-world perspective, here’s a hypothetical incremental sales example we’ve created for reference: A green clothing retailer typically sells $14,000 worth of ethical sweaters per month without investing in advertising.
Data Vault overview For a brief review of the core Data Vault premise and concepts, refer to the first post in this series. For more information, refer to Amazon Redshift database encryption. String-optimized compression The Data Vault 2.0 If you use AWS KMS, you can either use an AWS managed key or customer managed key.
Refer to Amazon Kinesis Data Streams integrations for additional details. Stream Processing – An application created with Amazon Managed Service for Apache Flink can read the records from the data stream to detect and clean any errors in the time series data and enrich the data with specific metadata to optimize operational analytics.
We had to identify the “optimal path” for customers without any information from the customer. We also couldn’t reference the underlying infrastructure as it would break our abstraction as an “autonomous database.”. Create a snapshot . Export the snapshot to the destination in the Cloud. Enable replication.
Answer : Along with standard RDS features, Amazon RDS for Db2 supports key Db2 features, such as row and column organized tables for mixed and analytic workloads, the Adaptive Workload Optimizer to for better resource management, and rules-based access controls for advanced data protection. Backup and restore 11.
A procurement report allows an organization to demonstrate how its procurement activities deliver value for money, contribute to the realization of its broader goals and objectives, and provide a panoramic snapshot of the effectiveness of its procurement strategy. Manage your spend data. click to enlarge**.
Use case Consider a large company that relies heavily on data-driven insights to optimize its customer support processes. Step 3: Verify the initial SEED load The SEED load refers to the initial loading of the tables that you want to ingest into an Amazon SageMaker Lakehouse using zero-ETL integration.
Your applications can seamlessly read from and write to your Amazon Redshift data warehouse while maintaining optimal performance and transactional consistency. Additionally, you’ll benefit from performance improvements through pushdown optimizations, further enhancing the efficiency of your operations.
Architecturally, we chose a serverless model, and the data lake architecture action line refers to all the architectural gaps and challenging features we determined were part of the improvements. For more details, refer to Connection Types and Options for ETL in AWS Glue. We also used AWS Lambda for data processing.
To help make it quick and easy for IT leaders to get a reliable snapshot of the enterprise storage trends, we put together this “trends update” for the second half of 2022. To download a PDF of these market trends for your quick and easy reference, click here. Data Management
To assess the nodes and find an optimal RA3 cluster configuration, we collaborated with AllCloud , the AWS premier consulting partner. To do this, we required the following: A reference cluster snapshot – This ensures that we can replay any tests starting from the same state. Take snapshot from 6 x RA3.4xlarge.
Cybersecurity refers to a company’s ability to protect its systems, network, and data from cybercrimes. Systematic pentesting might help identify some gaps in your cyber resilience program but ultimately, it’s just a snapshot of what is happening. Cybersecurity vs cyber resilience: how they differ. You should rely on it completely.
These labor-intensive evaluations of data quality can only be performed periodically, so at best they provide a snapshot of quality at a particular time. Tacking testing and monitoring on as an afterthought is not an optimal way to reduce errors. In governance, people sometimes perform manual data quality assessments.
You can see the time each task spends idling while waiting for the Redshift cluster to be created, snapshotted, and paused. Refer to the Configuration reference in the User Guide for detailed configuration values. To learn more about Setup and Teardown tasks, refer to the Apache Airflow documentation.
The connectors were only able to reference hostnames in the connector configuration or plugin that are publicly resolvable and couldn’t resolve private hostnames defined in either a private hosted zone or use DNS servers in another customer network. For instructions, refer to create key-pair here. For instructions, refer to here.
Customers across industries are becoming more data driven and looking to increase revenue, reduce cost, and optimize their business operations by implementing near real time analytics on transactional data, thereby enhancing agility. In the Instance configuration section , select Memory optimized classes.
For comprehensive instructions, refer to Running Spark jobs with the Spark operator. For official guidance, refer to Create a VPC. Refer to create-db-subnet-group for more details. Refer to create-db-subnet-group for more details. Refer to create-db-cluster for more details. SubnetId" | jq -c '.') mysql_aurora.3.06.1
Refer to Using Apache Flink connectors to stay updated on any future changes regarding connector versions and compatibility. This flexibility optimizes job performance by reducing checkpoint frequency during backlog phases, enhancing overall throughput. It’s recommended to use connectors for the runtime version you are using.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content