This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Snapshots are crucial for data backup and disaster recovery in Amazon OpenSearch Service. These snapshots allow you to generate backups of your domain indexes and cluster state at specific moments and save them in a reliable storage location such as Amazon Simple Storage Service (Amazon S3). Snapshots are not instantaneous.
In this post, we will introduce a new mechanism called Reindexing-from-Snapshot (RFS), and explain how it can address your concerns and simplify migrating to OpenSearch. Documents are parsed from the snapshot and then reindexed to the target cluster, so that performance impact to the source clusters is minimized during migration.
We will also cover the pattern with automatic compaction through AWS Glue Data Catalog table optimization. Consider a streaming pipeline ingesting real-time event data while a scheduled compaction job runs to optimize file sizes. Transaction 1 successfully updates the tables latest snapshot in the Iceberg catalog from 0 to 1.
The adoption of open table formats is a crucial consideration for organizations looking to optimize their data management practices and extract maximum value from their data. Branching Branches are independent lineage of snapshot history that point to the head of each lineage. In earlier posts, we discussed AWS Glue 5.0
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs time travel capability is driven by a concept called snapshots , which are recorded in metadata files.
The AWS Glue Data Catalog now enhances managed table optimization of Apache Iceberg tables by automatically removing data files that are no longer needed. Along with the Glue Data Catalog’s automated compaction feature, these storage optimizations can help you reduce metadata overhead, control storage costs, and improve query performance.
Amazon OpenSearch Service recently introduced the OpenSearch Optimized Instance family (OR1), which delivers up to 30% price-performance improvement over existing memory optimized instances in internal benchmarks, and uses Amazon Simple Storage Service (Amazon S3) to provide 11 9s of durability.
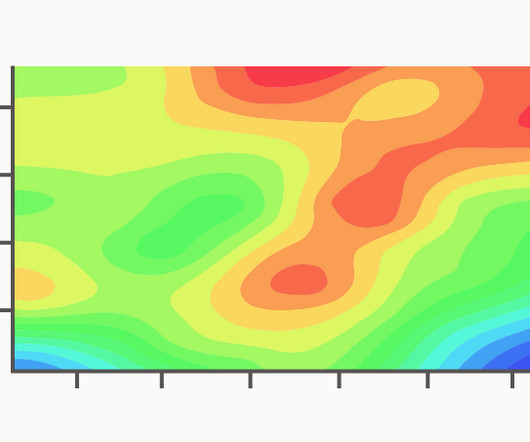
Contour Plots allow for the easy identification of maxima, minima, and optimal combinations of X and Y variables that produce desired Z values. Contour plots — Stata The post Chart Snapshot: Contour Plots appeared first on The Data Visualisation Catalogue Blog.
Systems of this nature generate a huge number of small objects and need attention to compact them to a more optimal size for faster reading, such as 128 MB, 256 MB, or 512 MB. As of this writing, only the optimize-data optimization is supported. Note the last four newly added configurations in the following statement.
Impala Optimizations for Small Queries. We’ll discuss the various phases Impala takes a query through and how small query optimizations are incorporated into the design of each phase. Query optimization in databases is a long standing area of research, with much emphasis on finding near optimal query plans.
With a powerful dashboard maker , each point of your customer relations can be optimized to maximize your performance while bringing various additional benefits to the picture. Whether you’re looking at consumer management dashboards and reports, every CRM dashboard template you use should be optimal in terms of design.
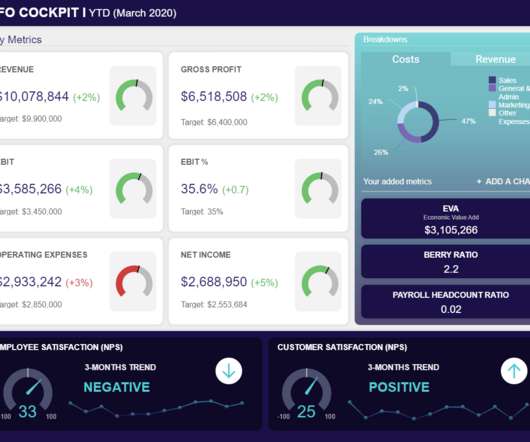
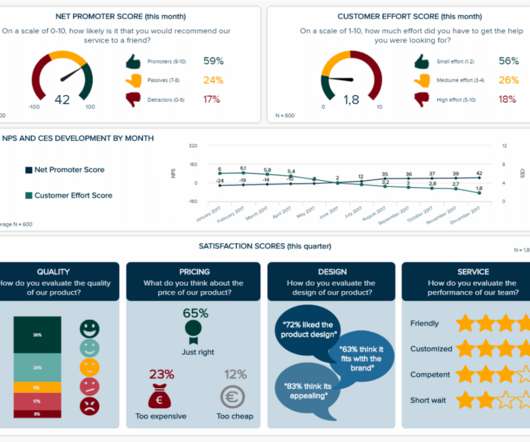
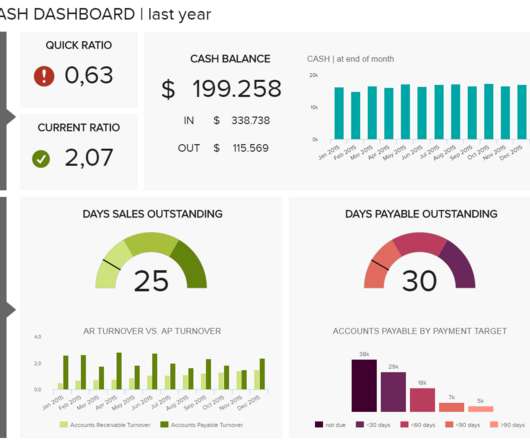
By including this cohesive mix of visual information, every CFO, regardless of sector, can gain a clear snapshot of the company’s fiscal performance within the first quarter of the year. Once you have set your aims, goals, and outcomes, you will be able to select CFO dashboard KPIs that will help you optimize your efforts.
Some challenges include data infrastructure that allows scaling and optimizing for AI; data management to inform AI workflows where data lives and how it can be used; and associated data services that help data scientists protect AI workflows and keep their models clean.
Amazon Redshift , optimized for complex queries, provides high-performance columnar storage and massively parallel processing (MPP) architecture, supporting large-scale data processing and advanced SQL capabilities. The solutions flexible and scalable architecture effectively optimizes operational costs and improves business responsiveness.
Amazon OpenSearch Service introduced the OpenSearch Optimized Instances (OR1) , deliver price-performance improvement over existing instances. For more details about OR1 instances, refer to Amazon OpenSearch Service Under the Hood: OpenSearch Optimized Instances (OR1). OR1 instances use a local and a remote store.
Despite their advantages, traditional data lake architectures often grapple with challenges such as understanding deviations from the most optimal state of the table over time, identifying issues in data pipelines, and monitoring a large number of tables. It is essential for optimizing read and write performance.
Internally, Apache Flink uses clever mechanisms to maintain exactly-once state consistency, while also optimizing for throughput and reduced latency. Each of the distributed components of an application asynchronously snapshots its state to an external persistent datastore. The default behavior works well for most use cases.
We’ve already discussed how checkpoints, when triggered by the job manager, signal all source operators to snapshot their state, which is then broadcasted as a special record called a checkpoint barrier. When barriers from all upstream partitions have arrived, the sub-task takes a snapshot of its state.
You can use big data analytics in logistics, for instance, to optimize routing, improve factory processes, and create razor-sharp efficiency across the entire supply chain. This isn’t just valuable for the customer – it allows logistics companies to see patterns at play that can be used to optimize their delivery strategies.
Metazoa is the company behind the Salesforce ecosystem’s top software toolset for org management, Metazoa Snapshot. Created in 2006, Snapshot was the first CRM management solution designed specifically for Salesforce and was one of the first Apps to be offered on the Salesforce AppExchange. Inactive users.
To manage the dynamism, we can resort to taking snapshots that represent immutable points in time: of models, of data, of code, and of internal state. However, none of these layers help with modeling and optimization. We cannot expect data scientists to write modeling frameworks like PyTorch or optimizers like Adam from scratch!
Cloudinary is a cloud-based media management platform that provides a comprehensive set of tools and services for managing, optimizing, and delivering images, videos, and other media assets on websites and mobile applications.
Inventory management benefits from historical data for analyzing sales patterns and optimizing stock levels. Implementing such a system can be complex, requiring careful consideration of data storage, retrieval mechanisms, and query optimization. You can obtain the table snapshots by querying for db.table.snapshots.
This blog discusses a few problems that you might encounter with Iceberg tables and offers strategies on how to optimize them in each of those scenarios. Problem with too many snapshots Everytime a write operation occurs on an Iceberg table, a new snapshot is created. See Write properties.
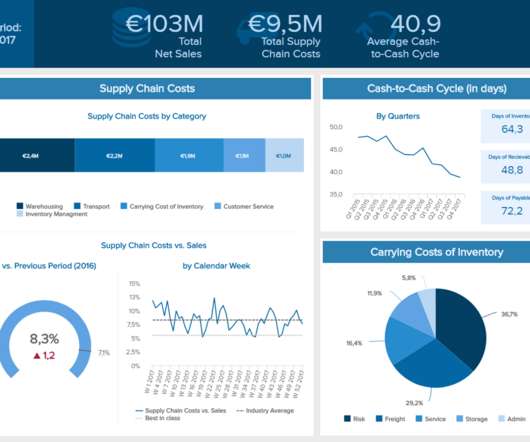
That’s why it’s critical to monitor and optimize relevant supply chain metrics. While there are numerous KPI examples you can select for your assessment and optimization, we have focused on a list that will enable you to identify potential bottlenecks and ensure sustainable development. Delivery Time.
These formats enable ACID (atomicity, consistency, isolation, durability) transactions, upserts, and deletes, and advanced features such as time travel and snapshots that were previously only available in data warehouses. It will never remove files that are still required by a non-expired snapshot.
Some of the benefits are detailed below: Optimizing metadata for greater reach and branding benefits. Traditional analytics interfaces can provide a rough snapshot of engagement, but ones that use Hadoop are more effective. Hadoop tools can find data on more variables that helps optimize engagement much better.
Some things to keep in mind: Stateful downgrades are not compatible and will not be accepted due to snapshot incompatibility. Validation of the state snapshot compatibility happens when the application attempts to start in the new runtime version. This helps prevent duplicate data entering the stream processing application.
While there are numerous types of dashboards that you can choose from to adjust and optimize your results, we have selected the top 3 that will tell you more about the story behind them. Such dashboards are extremely convenient to share the most important information in a snapshot. Let’s take a closer look.
By optimizing the various CDP Data Services, including CDW, CDE, and Cloudera Machine Learning (CML) with Iceberg, Cloudera customers can define and manipulate datasets with SQL commands, build complex data pipelines using features like Time Travel operations, and deploy machine learning models built from Iceberg tables. Ready to try? .
Operational optimization and forecasting. Cost optimization. Another important factor to consider is cost optimization. Our procurement dashboard above is not only visually balanced but also offers a clear-cut snapshot of every vital metric you need to improve your procurement processes at a glance. Cost optimization.
When you build your transactional data lake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 data lake to optimize the production environment. This property is set to true by default. AIMD is supported for Amazon EMR releases 6.4.0 cluster with installed applications Hadoop 3.3.3,
This means that cost-optimization exercises can happen at any time—they no longer need to happen in the planning phase. These scalable properties of Apache Flink can be key to optimizing your cost in the cloud. The third cost component is durable application backups, or snapshots. per GB per month.
In this post, we look into an optimal and cost-effective way of incorporating dbt within Amazon Redshift. In an optimal environment, we store the credentials in AWS Secrets Manager and retrieve them. Snapshots – These implements type-2 slowly changing dimensions (SCDs) over mutable source tables.
You can use this solution regularly as part of your cost-optimization efforts to safely remove unused EIPs to reduce your costs. To gather EIP usage reporting, this solution compares snapshots of the current EIPs, focusing on their most recent attachment within a customizable 3-month period.
Engagement: By obtaining access to a panoramic snapshot of your business’s entire customer service and support processes, you’ll be able to make vital improvements to your service levels, consumer touchpoints, content, and communications.
Example: Recrawl Logic within Google search Google search works because our software has previously crawled many billions of web pages, that is, scraped and snapshotted each one. These snapshots comprise what we refer to as our search index. Whenever a snapshot’s contents match its real-world counterpart, we call that snapshot ‘fresh.’
Whenever there is an update to the Iceberg table, a new snapshot of the table is created, and the metadata pointer points to the current table metadata file. At the top of the hierarchy is the metadata file, which stores information about the table’s schema, partition information, and snapshots.
Despite these capabilities, data lakes are not databases, and object storage does not provide support for ACID processing semantics, which you may require to effectively optimize and manage your data at scale across hundreds or thousands of users using a multitude of different technologies.
It provides a brief snapshot of the entire business. I humbly believe the challenge is that in a world of too much data, with lots more on the way, there is a deep desire amongst executives to get "summarize data," to get "just a snapshot," or to get the "top-line view." digital performance. Standstill.
Queries containing joins, filters, projections, group-by, or aggregations without group-by can be transparently rewritten by the Hive optimizer to use one or more eligible materialized views. Subsequently, these snapshot IDs are used to determine the delta changes that should be applied to the materialized view rows.
And this snapshot aligns with a far bigger trend we’re noticing across industries—business leaders need expert partners (both from within their IT teams and from vendors like HPE Aruba Networking) to help them leverage their network to produce innovative business outcomes, aligned to their specific, strategic digital transformation goals.
Usually, these reports are considered to be financial statements which include: a balance sheet: is a snapshot of a business at a specific time and shows the ending assets, liability, and equity balances as of the balance sheet date. The balance sheet is a snapshot of your business finances at a moment in time, showing assets and liabilities.
Sending a snapshot of a visualization to a colleague to initiate a discussion. For certain operational activities, the goal should be to drive direct action based on data with scoring or optimization models. Creating an action item for your team based on the results of an analysis.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content