This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Snapshots are crucial for data backup and disaster recovery in Amazon OpenSearch Service. These snapshots allow you to generate backups of your domain indexes and cluster state at specific moments and save them in a reliable storage location such as Amazon Simple Storage Service (Amazon S3). Snapshots are not instantaneous.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs time travel capability is driven by a concept called snapshots , which are recorded in metadata files.
The applications must be integrated to the surrounding business systems so ideas can be tested and validated in the real world in a controlled manner. To manage the dynamism, we can resort to taking snapshots that represent immutable points in time: of models, of data, of code, and of internal state. Why did something break?
Systems of this nature generate a huge number of small objects and need attention to compact them to a more optimal size for faster reading, such as 128 MB, 256 MB, or 512 MB. As of this writing, only the optimize-data optimization is supported. For our testing, we generated about 58,176 small objects with total size of 2 GB.
With a powerful dashboard maker , each point of your customer relations can be optimized to maximize your performance while bringing various additional benefits to the picture. Whether you’re looking at consumer management dashboards and reports, every CRM dashboard template you use should be optimal in terms of design.
With the launch of Amazon Redshift Serverless and the various provisioned instance deployment options , customers are looking for tools that help them determine the most optimal data warehouse configuration to support their Amazon Redshift workloads. Launch the producer warehouse by restoring the snapshot to a 32 RPU serverless namespace.
You can use big data analytics in logistics, for instance, to optimize routing, improve factory processes, and create razor-sharp efficiency across the entire supply chain. Your Chance: Want to test a professional logistics analytics software? A testament to the rising role of optimization in logistics.
Impala Optimizations for Small Queries. We’ll discuss the various phases Impala takes a query through and how small query optimizations are incorporated into the design of each phase. Query optimization in databases is a long standing area of research, with much emphasis on finding near optimal query plans.
Amazon OpenSearch Service introduced the OpenSearch Optimized Instances (OR1) , deliver price-performance improvement over existing instances. For more details about OR1 instances, refer to Amazon OpenSearch Service Under the Hood: OpenSearch Optimized Instances (OR1). OR1 instances use a local and a remote store.
We’ve already discussed how checkpoints, when triggered by the job manager, signal all source operators to snapshot their state, which is then broadcasted as a special record called a checkpoint barrier. When barriers from all upstream partitions have arrived, the sub-task takes a snapshot of its state.
Internally, Apache Flink uses clever mechanisms to maintain exactly-once state consistency, while also optimizing for throughput and reduced latency. Each of the distributed components of an application asynchronously snapshots its state to an external persistent datastore. The default behavior works well for most use cases.
Some will argue that observability is nothing more than testing and monitoring applications using tests, metrics, logs, and other artifacts. Below we will explain how to virtually eliminate data errors using DataOps automation and the simple building blocks of data and analytics testing and monitoring. . Tie tests to alerts.
Your Chance: Want to test a market research reporting software? While there are numerous types of dashboards that you can choose from to adjust and optimize your results, we have selected the top 3 that will tell you more about the story behind them. Your Chance: Want to test a market research reporting software?
The next recommended step is to test your application locally with the newly upgraded Apache Flink runtime. After you have sufficiently tested your application with the new runtime version, you can begin the upgrade process. Refer to General best practices and recommendations for more details on how to test the upgrade process itself.
Cloudinary is a cloud-based media management platform that provides a comprehensive set of tools and services for managing, optimizing, and delivering images, videos, and other media assets on websites and mobile applications.
With the launch of Amazon Redshift Serverless and the various deployment options Amazon Redshift provides (such as instance types and cluster sizes), customers are looking for tools that help them determine the most optimal data warehouse configuration to support their Redshift workload.
It also applies general software engineering principles like integrating with git repositories, setting up DRYer code, adding functional test cases, and including external libraries. In this post, we look into an optimal and cost-effective way of incorporating dbt within Amazon Redshift. For more information, refer SQL models.
This means that cost-optimization exercises can happen at any time—they no longer need to happen in the planning phase. These scalable properties of Apache Flink can be key to optimizing your cost in the cloud. The third cost component is durable application backups, or snapshots. per GB per month.
Whenever there is an update to the Iceberg table, a new snapshot of the table is created, and the metadata pointer points to the current table metadata file. At the top of the hierarchy is the metadata file, which stores information about the table’s schema, partition information, and snapshots.
This helps traders determine the potential profitability of a strategy and identify any risks associated with it, enabling them to optimize it for better performance. To avoid look-ahead bias in backtesting, it’s essential to create snapshots of the data at different points in time.
When you build your transactional data lake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 data lake to optimize the production environment. Update your-iceberg-storage-blog in the following configuration with the bucket that you created to test this example.
By optimizing the various CDP Data Services, including CDW, CDE, and Cloudera Machine Learning (CML) with Iceberg, Cloudera customers can define and manipulate datasets with SQL commands, build complex data pipelines using features like Time Travel operations, and deploy machine learning models built from Iceberg tables. What’s Next.
Your Chance: Want to test accounting reporting software for free? Usually, these reports are considered to be financial statements which include: a balance sheet: is a snapshot of a business at a specific time and shows the ending assets, liability, and equity balances as of the balance sheet date. What Are Accounting Reports?
Your Chance: Want to test professional business reporting software? Your Chance: Want to test professional business reporting software? Your Chance: Want to test professional business reporting software? Your Chance: Want to test professional business reporting software? Let’s get started. SaaS management dashboard.
Athena also supports the ability to create views and perform VACUUM (snapshot expiration) on Apache Iceberg tables to optimize storage and performance. Data transformation processes can be complex requiring more coding, more testing and are also error prone. However, this requires knowledge of a table’s current snapshots.
Armed with powerful visualizations and real-time data, modern weekly summary reports enable businesses to closely monitor their performance and the progress of their strategies to extract relevant insights and optimize their processes to ensure constant growth. Your Chance: Want to build great weekly status reports on your own?
One of the most effective Twitter KPIs , the ‘top 5 Tweets’ metric offers a clear, concise, and digestible visual snapshot of your most engaging Tweets over a specific period of time. A priceless resource for SEO content writers, the Flesch reading test will help you evaluate the quality, complexity, and duplicity of your copy.
Your Chance: Want to test modern reporting software for free? Extracting business insights based on factual data and not just simple intuition will lead companies to optimize several processes and ensure sustainable development. Your Chance: Want to test modern reporting software for free? Let’s get started!
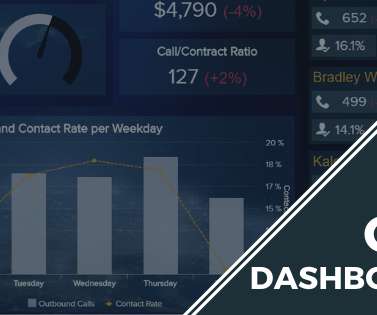
A call center dashboard is an intuitive visual reporting tool that displays a range of relevant call center metrics and KPIs that allow customer service managers and teams to monitor and optimize performance and spot emerging trends in a central location. Your Chance: Want to test a call center dashboard software for free?
Building a starter version of anything can often be straightforward, but building something with enterprise-grade scale, security, resiliency, and performance typically requires knowledge and adherence to battle-tested best practices, and using the right tools and features in the right scenario. String-optimized compression The Data Vault 2.0
Despite these capabilities, data lakes are not databases, and object storage does not provide support for ACID processing semantics, which you may require to effectively optimize and manage your data at scale across hundreds or thousands of users using a multitude of different technologies.
Test environment In order to be confident with the performance of the RA3 nodes, we decided to stress test them in a controlled environment before making the decision to migrate. To assess the nodes and find an optimal RA3 cluster configuration, we collaborated with AllCloud , the AWS premier consulting partner.
AWS offers Redshift Test Drive to validate whether the configuration chosen for Amazon Redshift is ideal for your workload before migrating the production environment. We carried out the migration as follows: We created a new cluster with eight ra3.4xlarge nodes from the snapshot of our four-node dc2.8xlarge cluster. TB of data.
Example: Recrawl Logic within Google search Google search works because our software has previously crawled many billions of web pages, that is, scraped and snapshotted each one. These snapshots comprise what we refer to as our search index. Whenever a snapshot’s contents match its real-world counterpart, we call that snapshot ‘fresh.’
Queries containing joins, filters, projections, group-by, or aggregations without group-by can be transparently rewritten by the Hive optimizer to use one or more eligible materialized views. Subsequently, these snapshot IDs are used to determine the delta changes that should be applied to the materialized view rows.
Cloudera Contributors: Ayush Saxena, Tamas Mate, Simhadri Govindappa Since we announced the general availability of Apache Iceberg in Cloudera Data Platform (CDP), we are excited to see customers testing their analytic workloads on Iceberg. Iceberg basics Iceberg is an open table format designed for large analytic workloads.
KPIs make sure you can track and audit optimal implementation, achieve consumer satisfaction and trust, and minimize disruptions during the final transition. Thorough testing and performance optimization will facilitate a smooth transition with minimal disruption to end-users, fostering exceptional user experiences and satisfaction.
Answer : Along with standard RDS features, Amazon RDS for Db2 supports key Db2 features, such as row and column organized tables for mixed and analytic workloads, the Adaptive Workload Optimizer to for better resource management, and rules-based access controls for advanced data protection. Backup and restore 11.
We had to identify the “optimal path” for customers without any information from the customer. Create a snapshot . Export the snapshot to the destination in the Cloud. Import the snapshot into the database. If you are interested in trying out CDP Public Cloud and the Operational Database, try out our Test Drive.
In working with thousands of customers deploying Spark applications, we saw significant challenges with managing Spark as well as automating, delivering, and optimizing secure data pipelines. Test Drive CDP Pubic Cloud. The post Cloudera Data Engineering 2021 Year End Review appeared first on Cloudera Blog.
Dell’s updated PowerStore offering aims to deliver up to a 50% mixed-workload performance boost and up to 66% greater capacity, based on internal tests conducted in March 2022. . To create a productive, cost-effective analytics strategy that gets results, you need high performance hardware that’s optimized to work with the software you use.
To further optimize and improve the developer velocity for our data consumers, we added Amazon DynamoDB as a metadata store for different data sources landing in the data lake. S3 bucket as landing zone We used an S3 bucket as the immediate landing zone of the extracted data, which is further processed and optimized.
Your applications can seamlessly read from and write to your Amazon Redshift data warehouse while maintaining optimal performance and transactional consistency. Additionally, you’ll benefit from performance improvements through pushdown optimizations, further enhancing the efficiency of your operations.
They also provide a “ snapshot” procedure that creates an Iceberg table with a different name with the same underlying data. You could first create a snapshot table, run sanity checks on the snapshot table, and ensure that everything is in order. As of this writing, the “__BACKUP__” suffix is hardcoded.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content