This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
decomposes a complex task into a graph of subtasks, then uses LLMs to answer the subtasks while optimizing for costs across the graph. Then connect the graph nodes and relations extracted from unstructureddata sources, reusing the results of entity resolution to disambiguate terms within the domain context.
Train, Export, Optimize (TensorRT), Infer (Jetson Nano) appeared first on Analytics Vidhya. Part 1 — Detailed steps from training a detector on a custom dataset to inferencing on jetson nano board or cloud using TensorFlow 1.15. The post TensorFlow Object Detection — 1.0 & 2.0:
They promise to revolutionize how we interact with data, generating human-quality text, understanding natural language and transforming data in ways we never thought possible. From automating tedious tasks to unlocking insights from unstructureddata, the potential seems limitless. Ive seen this firsthand.
When I think about unstructureddata, I see my colleague Rob Gerbrandt (an information governance genius) walking into a customer’s conference room where tubes of core samples line three walls. While most of us would see dirt and rock, Rob sees unstructureddata. have encouraged the creation of unstructureddata.
Here we mostly focus on structured vs unstructureddata. In terms of representation, data can be broadly classified into two types: structured and unstructured. Structured data can be defined as data that can be stored in relational databases, and unstructureddata as everything else.
Choreographing data, AI, and enterprise workflows While vertical AI solves for the accuracy, speed, and cost-related challenges associated with large-scale GenAI implementation, it still does not solve for building an end-to-end workflow on its own. to autonomously address lost card calls.
Some challenges include data infrastructure that allows scaling and optimizing for AI; data management to inform AI workflows where data lives and how it can be used; and associated data services that help data scientists protect AI workflows and keep their models clean. Through relentless innovation.
This brief explains how data virtualization, an advanced data integration and data management approach, enables unprecedented control over security and governance. In addition, data virtualization enables companies to access data in real time while optimizing costs and ROI.
For example, process and task mining can uncover inefficiencies and identify opportunities for optimization, while RPA and low/no-code platforms can empower teams to automate repetitive tasks and develop solutions rapidly.
Instead of overhauling entire systems, insurers can assess their API infrastructure to ensure efficient data flow, identify critical data types, and define clear schemas for structured and unstructureddata. Incorporating custom knowledge graphs, enriched with domain expertise, further optimizesdata consolidation.
One example of Pure Storage’s advantage in meeting AI’s data infrastructure requirements is demonstrated in their DirectFlash® Modules (DFMs), with an estimated lifespan of 10 years and with super-fast flash storage capacity of 75 terabytes (TB) now, to be followed up with a roadmap that is planning for capacities of 150TB, 300TB, and beyond.
The key is to make data actionable for AI by implementing a comprehensive data management strategy. That’s because data is often siloed across on-premises, multiple clouds, and at the edge. Getting the right and optimal responses out of GenAI models requires fine-tuning with industry and company-specific data.
Different types of information are more suited to being stored in a structured or unstructured format. Read on to explore more about structured vs unstructureddata, why the difference between structured and unstructureddata matters, and how cloud data warehouses deal with them both. Unstructureddata.
Adopting hybrid and multi-cloud models provides enterprises with flexibility, cost optimization, and a way to avoid vendor lock-in. A prominent public health organization integrated data from multiple regional health entities within a hybrid multi-cloud environment (AWS, Azure, and on-premise). Why Hybrid and Multi-Cloud?
Two big things: They bring the messiness of the real world into your system through unstructureddata. Slow response/high cost : Optimize model usage or retrieval efficiency. Business value : Align outputs with business metrics and optimize workflows to achieve measurable ROI. What makes LLM applications so different?
Salesforce is updating its Data Cloud with vector database and Einstein Copilot Search capabilities in an effort to help enterprises use unstructureddata for analysis. The Einstein Trust Layer is based on a large language model (LLM) built into the platform to ensure data security and privacy.
There, I met with IT leaders across multiple lines of business and agencies in the US Federal government focused on optimizing the value of AI in the public sector. AI can optimize citizen-centric service delivery by predicting demand and customizing service delivery, resulting in reduced costs and improved outcomes. Trust your data.
At Vanguard, “data and analytics enable us to fulfill on our mission to provide investors with the best chance for investment success by enabling us to glean actionable insights to drive personalized client experiences, scale advice, optimize investment and business operations, and reduce risk,” Swann says.
Monte Carlo Data — Data reliability delivered. Data breaks. Observe, optimize, and scale enterprise data pipelines. . Validio — Automated real-time data validation and quality monitoring. . DataMo – Datmo tools help you seamlessly deploy and manage models in a scalable, reliable, and cost-optimized way.
The application presents a massive volume of unstructureddata through a graphical or programming interface using the analytical abilities of business intelligence technology to provide instant insight. Interactive analytics applications present vast volumes of unstructureddata at scale to provide instant insights.
What is a data scientist? Data scientists are analytical data experts who use data science to discover insights from massive amounts of structured and unstructureddata to help shape or meet specific business needs and goals. Semi-structured data falls between the two.
The timing for these advancements is optimal as the industry grapples with skilled labor shortages, supply chain challenges, and a highly competitive global marketplace. Process optimization In manufacturing, process optimization that maximizes quality, efficiency, and cost-savings is an ever-present goal.
Many people are confused about these two, but the only similarity between them is the high-level principle of data storing. It is vital to know the difference between the two as they serve different principles and need diverse sets of eyes to be adequately optimized. This is a vital disparity between data warehouses and data lakes.
Optimizing GenAI with data management More than ever, businesses need to mitigate these risks while discovering the best approach to data management. Look for a holistic, end-to-end approach that will allow enterprises to easily adopt and deploy GenAI, from the endpoint to the data center, by building a powerful data operation.
Without the existence of dashboards and dashboard reporting practices, businesses would need to sift through colossal stacks of unstructureddata, which is both inefficient and time-consuming. With such dashboards, users can also customize settings, functionality, and KPIs to optimize their dashboards to suit their specific needs.
As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Newer data lakes are highly scalable and can ingest structured and semi-structured data along with unstructureddata like text, images, video, and audio.
Cost optimization. Speaking of global fintech trends, one cannot fail to mention Big Data. Big Data in finance refers to huge arrays of structured and unstructureddata that can be used by banks and financial institutions to predict consumer behavior and develop strategies. Unstructureddata.
Enterprises can harness the power of continuous information flow by lessening the gap between traditional architecture and dynamic data streams. Unstructureddata formatting issues Increasing data volume gets more challenging because it has large volumes of unstructureddata. CIO, Data Integration
By leveraging an organization’s proprietary data, GenAI models can produce highly relevant and customized outputs that align with the business’s specific needs and objectives. Structured data is highly organized and formatted in a way that makes it easily searchable in databases and data warehouses.
While data scientists were no longer handling Hadoop-sized workloads, they were trying to build predictive models on a different kind of “large” dataset: so-called “unstructureddata.” Both situations benefit from a technique that optimizes the search through a large and daunting solution space.
This capability has become increasingly more critical as organizations incorporate more unstructureddata into their data warehouses. As a subset of artificial intelligence, ML uses algorithms trained on large datasets to recognize trends and identify patterns without explicit programming.
Are you struggling to manage the ever-increasing volume and variety of data in today’s constantly evolving landscape of modern data architectures? Apache Ozone is compatible with Amazon S3 and Hadoop FileSystem protocols and provides bucket layouts that are optimized for both Object Store and File system semantics.
S3 Tables are specifically optimized for analytics workloads, resulting in up to 3 times faster query throughput and up to 10 times higher transactions per second compared to self-managed tables. These metadata tables are stored in S3 Tables, the new S3 storage offering optimized for tabular data.
To date, however, enterprises’ vast troves of unstructureddata – photo, video, text, and more – have remained mostly untapped. At DataRobot, we are acutely aware of the ability of diverse data to create vast improvements to our customers’ business. Today, managing unstructureddata is an arduous task. Jared Bowns.
They also face increasing regulatory pressure because of global data regulations , such as the European Union’s General Data Protection Regulation (GDPR) and the new California Consumer Privacy Act (CCPA), that went into effect last week on Jan. erwin Data Modeler: Where the Magic Happens. CCPA vs. GDPR: Key Differences.
Improving search capabilities and addressing unstructureddata processing challenges are key gaps for CIOs who want to deliver generative AI capabilities. But 99% also report technical challenges, listing integration (68%), data volume and cleansing (59%), and managing unstructureddata (55% ) as the top three.
Today’s data volumes have long since exceeded the capacities of straightforward human analysis, and so-called “unstructured” data, not stored in simple tables and columns, has required new tools and techniques. In this way, you can turn dark data into insights and help drive business improvements. Dark variables.
There is no disputing the fact that the collection and analysis of massive amounts of unstructureddata has been a huge breakthrough. We would like to talk about data visualization and its role in the big data movement. How is Data Virtualization performance optimized? In improving operational processes.
In other words, generative AI can optimize learning by architecting personalized learning journeys for individual students. Today, many institutions are gridlocked because AI and generative AI have very different data and IT needs than traditional technology. This keeps students appropriately challenged and engaged.
Text mining and text analysis are relatively recent additions to the data science world, but they already have an incredible impact on the corporate world. As businesses collect increasing amounts of often unstructureddata, these techniques enable them to efficiently turn the information they store into relevant, actionable resources.
Clean and prep your data for private LLMs Generative AI capabilities will increase the importance and value of an enterprise’s unstructureddata, including documents, videos, and content stored in learning management systems.
In the era of data, organizations are increasingly using data lakes to store and analyze vast amounts of structured and unstructureddata. Data lakes provide a centralized repository for data from various sources, enabling organizations to unlock valuable insights and drive data-driven decision-making.
Data is becoming increasingly important for understanding markets and customer behaviors, optimizing operations, deriving foresights, and gaining a competitive advantage. Over the last decade, the explosion of structured and unstructureddata as well as digital technologies in general, has enabled.
In an era where data is both a critical asset and a growing challenge, he shared insights into how his organization helps businesses optimize their data landscapes, overcome common pitfalls, and prepare for the future. I recently had the opportunity to interview Robert Reuben, Managing Director of Proceed Group.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






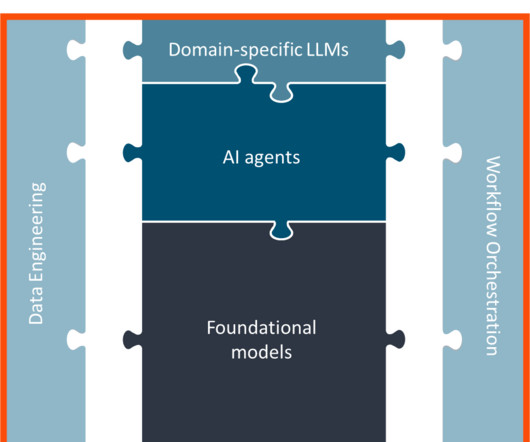


















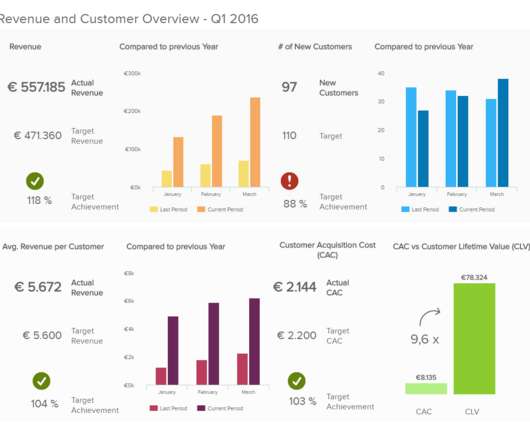



























Let's personalize your content