This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here, we want to talk about our flagship productGraphDB – an enterprise-ready RDF database optimized for the development and operations of knowledge graphs. Now, thanks to some of our latest releases, GraphDB allows those who need to work in SQL to access the power of their organization’s knowledge with SQL. Mapping UI.
ONTOTEXT ANSWER: You’ve probably seen our news on the topic and are getting confused between our products. There is Ontotext’s GraphDB and then there is Ontotext Platform. Ontotext Platform, which is built on top of Ontotext’s GraphDB, offers object-level RBAC security, with ABAC attribute filtering rules on it.
Are you an existing GraphDB user who is planning to build an API layer over GraphDB? This leads to lots of small data fetches to/from GraphDB over the network. Perhaps you now decide to manage the SKOS and FIBO vocabulary in GraphDB, but also want to provide a controlled, consistent, simple to use API across the data.
ONTOTEXT ANSWER: Logging in GraphDB is complex, leading to some confusion about how to best address it. The transaction log is the main component of the GraphDB cluster. By default, it’s located inside the conf directory, together with the GraphDB properties file. Get a quick answer using the graphdb tag on stack overflow.
Perhaps you are replicating a development or staging environment in production. GraphDB backs up the cluster at a “data” level. Now for the restore, assume that GraphDB is operational already. Still, it is good to know that GraphDB can restore the cluster even in such a situation. That’s for the backup.
In our previous blog posts of the series, we talked about how to ingest data from different sources into GraphDB , validate it and infer new knowledge from the extant facts as well as how to adapt and scale our basic solution. What GraphDB brings to the table are two extra features: internal federation and FedX. Relational data.
Suffice it to say, GraphDB supports the latter model. When querying data, the GraphDB master assigns the most up-to-date worker to give you the answer. The post GraphDB Users Ask: How to size the GraphDB cluster? We’ll perhaps go in greater detail about the benefits and drawbacks of these two approaches at a later date.
This will improve the productivity and quality of the design and construction processes and support a sustainable built environment. ACCORD uses GraphDB to perform automated compliance checks as RDF ( Resource Description Framework ) knowledge graphs are compliant with W3C standards. So stay tuned!
It’s a dangerous business, putting your product to market. Picture this – you start with the perfect use case for your data analytics product. Our main weapons when beating that beast will be GraphDB , Ontotext Platform , Kafka , Elasticsearch , Kibana and Jupyter. Fortunately, GraphDB has something better.
More and more companies are using them to improve a variety of tasks from product range specification and risk analysis to supporting self-driving cars. But we are also happy to report that some of the biggest car manufacturers leverage Ontotext’s RDF database for knowledge graphs GraphDB in their technology. And that’s not all.
Much awaited and long overdue, the only fully benchmarked graph database on the market, GraphDB , is now available on AWS Marketplace ready for enterprise adoption. Why GraphDB on AWS? GraphDB robust cloud-based solution, coupled with the underlying IaaS, provides better service RPO/RTO over on-premise solutions.
As you might guess from its name, GraphDB stores data in a graph data structure, which is much more flexible than the rigid table structures used by relational database managers. For the GraphDB user, the returned results look like they were delivered by a SPARQL engine and can play the same role in your applications.
We envisioned harnessing the power of our products to elevate our entire content publishing process, thereby facilitating in-depth knowledge exploration. The project involves different departments and leverages our products and capabilities by combining them with our marketing team’s expertise.
We have already explained how to deploy GraphDB in a generic environment and on Azure. This post will guide you through deploying GraphDB in your AWS account using our Terraform scripts. The scripts deploy the cluster using pre-built AMIs with the latest GraphDB version. And the cloud gives you flexibility at a reasonable price.
Our blog post GraphDB Cluster Deployment Strategies explained how to deploy a high-availability GraphDB cluster. Ontotext collaborates with major cloud providers, Azure and AWS, to offer the GraphDB high-availability cluster either as a managed service in Ontotext’s account or in the customer’s account.
We offer a seamless integration of the PoolParty Semantic Suite and GraphDB , called the PowerPack bundles. Our two products work exceptionally well together as GraphDB is a development tool, whereas PoolParty is an out-of-the-box product delivering optimal results with minimal configuration.
However, when it comes to queries that involve large and highly interconnected master data, the performance is solidly in favour of graph databases like GraphDB. Ontotext’s GraphDB. Relational databases benefit from decades of tweaks and optimizations to deliver performance. It can be queried. Give it a try today!
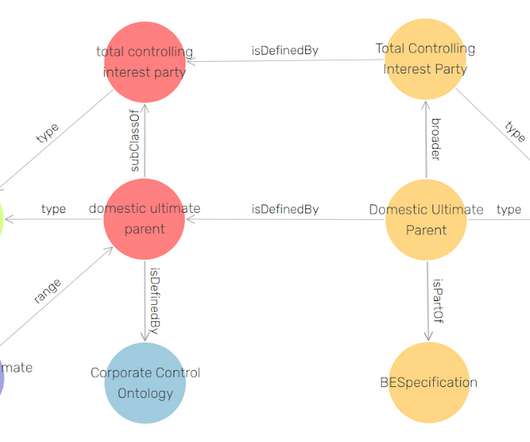
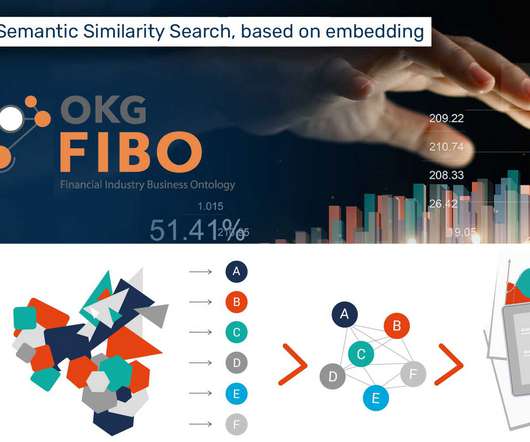
In this article we will discuss some of the features of GraphDB that support such an alignment. In the version used for this article (2020 Q2 Production), it contains: 122 namespaces, which represent the module structure; 1,542 classes; 1,328 concepts; 535 predicates. Loading FIBO in GraphDB. FIBO Overview. it supports RDF 1.1,
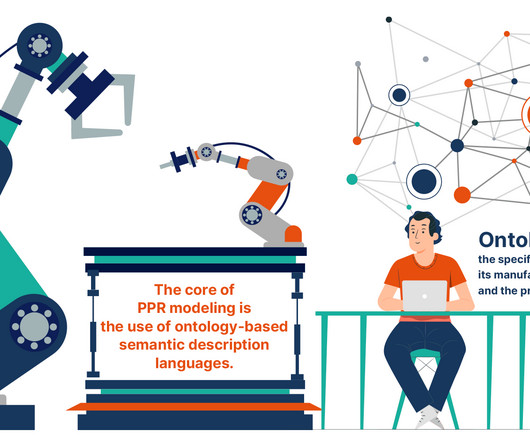
The PPR (Product, Process, Resources) modeling paradigm offers a robust framework to address this need, leveraging ontology-based semantic description languages to encode knowledge across various aspects of automation tasks [1]. Process : Information on the sequence of operations or steps required to produce or assemble the product.
This blog post will present a NLQ integration for Ontotext GraphDB in LangChain: a framework designed to simplify the creation of applications using LLMs. The diagram above offers a high-level overview of how NLQ for GraphDB works in LangChain. If the generated query is a valid SPARQL query, then it is executed against GraphDB.
SeeNews : Your flagship product is GraphDB. Atanas Kyriakov : Yes, this is our most popular product and I can share two use cases. One of the biggest retail banks in the USA collects monitoring information from its critical IT systems internally and then integrates it using GraphDB for better root-cause analysis.
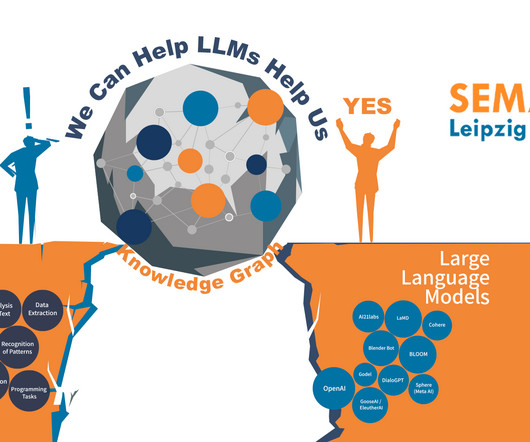
In this article, we argue that a knowledge graph built with semantic technology (the type of Ontotext’s GraphDB) improves the way enterprises operate in an interconnected world. This is where a well-built knowledge graph can help break the productivity barriers and transform scattered raw data into structured knowledge.
However, with GraphDB using forward-chaining – i.e., emitting inferred statements at ingestion time – it’s actually rather easy to debug and profile your inference. GraphDB evaluates the rules with the least amount of unbound variables first, but then follows your ordering. Avoid recursion and duplications.
The GraphDB SHACL engine works on materialized data. However, we strongly believe that most SHACL constraints that are relevant for a production-grade environment can be expressed with the default constraints. As GraphDB SHACL is tied to the data update and depends on a customized syntax tree, you need to insert your data.
In 2020, we continued to develop our leading database engine for management of knowledge graphs, GraphDB , and expanded it with a lot of new functionalities. GraphDB Empowers Scientific Projects to Fight COVID-19 and Publish Knowledge Graphs. Check out our 5 releases for this year – 9.1 , 9.2 , 9.3 , 9.4
For example, offering more of the same product or content instead of complementary items Analytics tools that don’t really support decision making Chatbots that fail the Alan Turing test You name it! This blog gives an overview of a product bundling that relies on two industry leaders that help you do this.
The first 18 years: Develop vision and products and deliver to innovation leaders. 9 years of research, prototyping and experimentation went into developing enterprise ready Semantic Technology products. Over the next 3 years Ontotext transformed itself into a product focused company with over 30% revenue growth.
The first 18 years: Develop vision and products and deliver to innovation leaders. 9 years of research, prototyping and experimentation went into developing enterprise ready Semantic Technology products. Over the next 3 years Ontotext transformed itself into a product focused company with over 30% revenue growth.
GraphDB & metaphactory Working Hand in Hand. At the heart of our solution are Ontotext’s GraphDB and metaphacts’ metaphactory. GraphDB is a leading RDF database that allows diverse data linking, indexing data for semantic search and enriching it via a text analysis plugin to build big knowledge graphs. To Sum It Up.
GraphQL Federation over GraphDB, MongoDB and a Semantic Vector Space. Schema Definition Language Query. Federated Annotation and Character Similarity. Federated Annotation, Character Similarity and Universe. With the remainder building out a GraphQL similarity service using GraphDB’s semantic vector space.
Often, it’s a by-product of business growth. We at Ontotext have dedicated 20 years to developing GraphDB so that it meets all these requirements. GraphDB can handle both with excellence, which positions it as the most versatile graph database engine. This task is something that LLMs don’t do well.
to identifying concepts and entities such as people, organisations, place names, chemical compounds and products as well as relationships between them. Inevitably, new people, companies, products appear in content, and these are most likely currently of most interest. Ontotext’s GraphDB. nouns, verbs, adjectives, etc.)
Since then the focus has been on the data domain as described in the EDMC’s current description of the product. GraphDB offers such a tool with its Similarity Indexes implemented as a plugin. This table, and the worksheet from which it is drawn, are not directly produced from GraphDB. Ontotext’s GraphDB.
of Ontotext’s GraphDB has lots of new bells and whistles that will ensure that it remains the market leader for semantic databases. GraphDB has always been compliant with W3C standards and an active member of the semantic web community. What does it mean for GraphDB clients? Version 9.0 Why going Open Source? The Plugins.
So far we have covered the capabilities and business applications of knowledge graphs as well as some of the major benefits of our RDF database – GraphDB. Analyzing Unstructured Data with GraphDB 9.8. You only lose the plugins that are part of GraphDB such as Graph path search.
In our previous post, we covered the basics of how the Ontotext and metaphacts joint solution based on GraphDB and metaphactory helps customers accelerate their knowledge graph journey and generate value from it in a matter of days. LinkedLifeData Inventory Pre-loaded In GraphDB. Semantic Data Integration With GraphDB.
Ontopic Studio Creating transformation rules can be done in different ways and the productivity and robustness of these approaches vary widely. The core component is GraphDB and our virtualization technology enables virtual access to data lakehouses. You can also easily create rules to move data into GraphDB.
It was based on the dynamics of Roofshots (Deliver incrementally and make production impacts) and Moonshots (Strive to apply and invent the state-of-the-art). Quality Production – quality, End-to-End Minimum Viable Product (E2E MVP) experiences. Scalability – a significant cost reduction for scale-ups.
So, even if it solves a problem for a while, the rapidly increasing needs of product and business teams lead to the proliferation of such applications. These models are as important to companies as their frontline products and determine how data is managed, consumed, combined, joined, and analyzed.
And, as more and more Building Automation providers are turning to knowledge graphs, two of the leading ones – Johnson Controls and Schneider Electric – have chosen Ontotext’s GraphDB. They are using GraphDB with BrickSchema to leverage semantic technologies in their building automation solutions.
We can address many of their challenges with our products – GraphDB and Ontotext Platform. Atanas also examines how Ontotext GraphDB and Ontotext Platform address these capabilities and provides an overview of Ontotext’s partner ecosystem. As a result, we know a lot about what our customers’ needs and pain points are.
You can also use it as a service to integrate in your own products or we can feature it as part of a broader custom solution we build for you. Directly through GraphDB , it can be called via the text mining plug-in and the output can be serialized in whatever form you prefer.
It’s a huge productivity loss.” This is the power of Zenia Graph’s services and solution powered by Ontotext GraphDB. Click here to learn more about Zenia Graph and its portfolio of GraphDB-based solutions ! Unleashing the Power of Data Connections Zenia Graph isn’t just another data solution company.
But the industry as we know it today actually emerged in the second half of the 19th century when the world’s first factory for the sole production of medicines was found. By the late 19th and early 20th century, some chemical companies had already begun using research labs to explore the medical applications for their products.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content