This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we use the term vanilla Parquet to refer to Parquet files stored directly in Amazon S3 and accessed through standard query engines like Apache Spark, without the additional features provided by table formats such as Iceberg. When a user requests a time travel query, the typical workflow involves querying a specific snapshot.
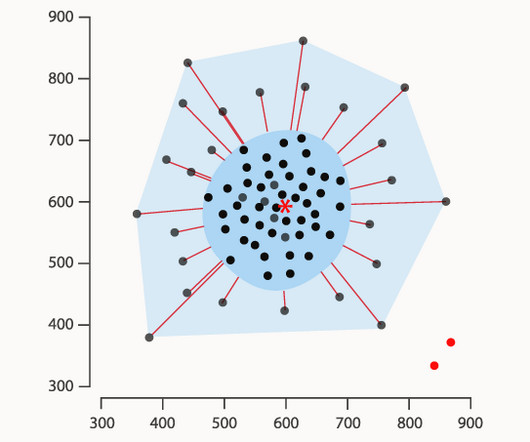
A Bagplot is a visualisation method used in robust statistics primarily designed for analysing two- or three-dimensional datasets. The key purpose of a Bagplot is to provide a comprehensive understanding of various statistical properties of the dataset, including its location, spread, skewness, and identification of outliers.
The company is looking for an efficient, scalable, and cost-effective solution to collecting and ingesting data from ServiceNow, ensuring continuous near real-time replication, automated availability of new data attributes, robust monitoring capabilities to track data load statistics, and reliable data lake foundation supporting data versioning.
Data poisoning refers to someone systematically changing your training data to manipulate your model’s predictions. Watermarking is a term borrowed from the deep learning security literature that often refers to putting special pixels into an image to trigger a desired outcome from your model. Data poisoning attacks. Watermark attacks.
We liken this methodology to the statistical process controls advocated by management guru Dr. Edward Deming. In addition to statistical process controls, we recommend location and historical balance tests. Statistical Process Control. These are called Time Balance tests or, more commonly, statistical process control (SPC).
Major market indexes, such as S&P 500, are subject to periodic inclusions and exclusions for reasons beyond the scope of this post (for an example, refer to CoStar Group, Invitation Homes Set to Join S&P 500; Others to Join S&P 100, S&P MidCap 400, and S&P SmallCap 600 ). Load the dataset into Amazon S3.
Snowflake integrates with AWS Glue Data Catalog to retrieve the snapshot location. In the event of a query, Snowflake uses the snapshot location from AWS Glue Data Catalog to read Iceberg table data in Amazon S3. Snowflake can query across Iceberg and Snowflake table formats.
The term business intelligence often also refers to a range of tools that provide quick, easy-to-digest access to insights about an organization’s current state, based on available data. BI aims to deliver straightforward snapshots of the current state of affairs to business managers.
Refer to Working with other AWS services in the Lake Formation documentation for an overview of table format support when using Lake Formation with other AWS services. Offers different query types , allowing to prioritize data freshness (Snapshot Query) or read performance (Read Optimized Query).
The third cost component is durable application backups, or snapshots. This is entirely optional and its impact on the overall cost is small, unless you retain a very large number of snapshots. The cost of durable application backup (snapshots) is $0.023 per GB per month. per hour, and attached application storage costs $0.10
In this method, you prepare the data for migration, and then set up the replication plugin to use a snapshot to migrate your data. HBase replication policies also provide an option called Perform Initial Snapshot. Simultaneously creates a snapshot at T1 and copies it to the target cluster. . Deletes the snapshot. .
If the answer is so easy why the worrying statistics? Cybersecurity refers to a company’s ability to protect its systems, network, and data from cybercrimes. Systematic pentesting might help identify some gaps in your cyber resilience program but ultimately, it’s just a snapshot of what is happening.
For a more in-depth description of these phases please refer to Impala: A Modern, Open-Source SQL Engine for Hadoop. Exhaustive cost-based query planning depends on having up to date and reliable statistics which are expensive to generate and even harder to maintain, making their existence unrealistic in real workloads.
Fortunately, we live in a digital age rife with statistics, data, and insights that give us the power to spot potential issues and inefficiencies within the business. This procurement report offers a panoramic snapshot of all valuable cost-based information. Despite this, these savings are nonetheless invaluable.
We refer to the user-submitted query as the parent query and the rewritten query as the child query in this post. These metrics are accumulated statistics across all runs of the query. Summary of ingestion SYS_LOAD_HISTORY provides details into the statistics of COPY commands.
For comprehensive instructions, refer to Running Spark jobs with the Spark operator. For official guidance, refer to Create a VPC. Refer to create-db-subnet-group for more details. Refer to create-db-subnet-group for more details. Refer to create-db-cluster for more details. SubnetId" | jq -c '.') mysql_aurora.3.06.1
AWS has invested in native service integration with Apache Hudi and published technical contents to enable you to use Apache Hudi with AWS Glue (for example, refer to Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 1: Getting Started ).
For complete getting started guides, refer to Working with Aurora zero-ETL integrations with Amazon Redshift and Working with zero-ETL integrations. Refer to Connect to an Aurora PostgreSQL DB cluster for the options to connect to the PostgreSQL cluster. The following diagram illustrates the architecture implemented in this post.
This is typically for application (e.g.jar,py files) and reference files, and not the data that the job run will operate on. For further analysis, stage level summary statistics show the number of parallel tasks and I/O distribution. The admin overview page provides a snapshot of all the workloads across multi-cloud environments.
Refer to Using Apache Flink connectors to stay updated on any future changes regarding connector versions and compatibility. Extending checkpoint intervals allows Apache Flink to prioritize processing throughput over frequent state snapshots, thereby improving efficiency and performance. SQL Apache Flink 1.19 With runtime 1.18
For more details, refer to the What’s New Post. For the complete list of public preview considerations, please refer to the feature AWS documentation. For complete getting started guides, refer to the following documentation links for Aurora and Amazon Redshift. The following diagram illustrates the high-level architecture.
Refer to Zero-ETL integration costs (Preview) for further details. For the complete getting started guides, refer to Working with Amazon RDS zero-ETL integrations with Amazon Redshift (preview) and Working with zero-ETL integrations. Configure the RDS for MySQL source with a custom DB parameter group.
A range of Iceberg table analysis such as listing table’s data file, selecting table snapshot, partition filtering, and predicate filtering can be delegated through Iceberg Java API instead, obviating the need for each query engine to implement it themself. However, Iceberg Java API calls are not always cheap.
By analyzing the historical report snapshot, you can identify areas for improvement, implement changes, and measure the effectiveness of those changes. For instructions, refer to Amazon DataZone quickstart with AWS Glue data. To learn more about Amazon DataZone, refer to the Amazon DataZone User Guide. option("header", "true").option("inferSchema",
To create it, refer to Tutorial: Get started with Amazon EC2 Windows instances. To download and install AWS SCT on the EC2 instance that you created, refer to Installing, verifying, and updating AWS SCT. For more information about bucket names, refer to Bucket naming rules. Deselect Create final snapshot.
For an example, refer to How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprise data platform. Column-level validation – Validate individual columns by comparing column-level statistics (min, max, count, sum, average) for each column between the source and target databases.
This key financial metric gives a snapshot of the financial health of your company by measuring the amount of cash generated by normal business operations. This financial KPI gives you a quick snapshot of a business’ financial health. It should be the first thing you look for on the cash flow statement.
How ItWorks Automated schema profiling compares real-time schema snapshots against historical ones to identify deviations. If certain transformations consistently fail or produce unexpected results, the system may pinpoint an incompatible data format or an out-of-date reference table. typos in addressfields).
Data testing can be done through various methods, such as data profiling, Statistical Process Control, and quality checks. Data lineage vs. the run time operations on data Runtime operations, such as those captured and monitored by DataOps Observability solutions, refer to the actions performed on data while it is being processed.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content