This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
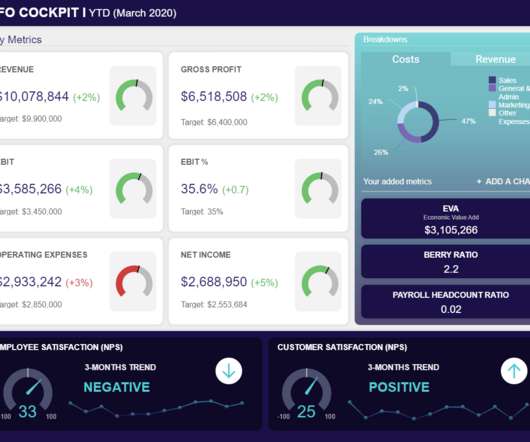
CFO reports provide a mix of visual KPIs geared towards helping financial officers make confident, informed decisions based on a variety of core financial activities. Operating profit margin: Also referred to as earnings before interests and tax, this CFO KPI demonstrates what’s left from the revenue after paying all operational costs.
Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. Referring to the data dictionary and screenshots, its evident that the complete data lineage information is highly dispersed, spread across 29 lineage diagrams. where(outV().as('a')),
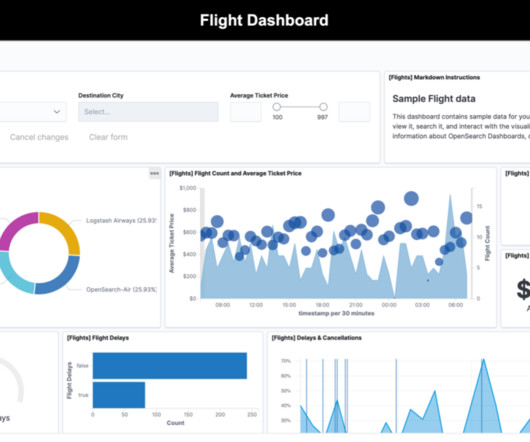
in Amazon OpenSearch Service , we introduced Snapshot Management , which automates the process of taking snapshots of your domain. Snapshot Management helps you create point-in-time backups of your domain using OpenSearch Dashboards, including both data and configuration settings (for visualizations and dashboards).
It provides a visual delineation of the main body of the data, illustrating its shape and arrangement within the dataset. This depth median signifies the point with the highest Tukey depth, providing a central reference point for the data distribution.
Visualizing the data and interacting on a single screen is no longer a luxury but a business necessity. They enable you to easily visualize your data, filter on-demand, and slice and dice your data to dig deeper. Maps are important data visualizations and at datapine, we love utilizing them in our dashboards.
By selecting the right KPIs for various areas of the business, it’s possible to use them to arrange as well as visualize large datasets. Communication: KPI reports and trackers are visual and interactive, which means that they are incredibly inclusive. To track KPIs is to gain greater business intelligence.
Progressive Bar Charts sometimes include an additional bar representing the total of all individual segments, providing viewers with a clear reference point for the overall value.
I want to try out writing a series of post that briefly explore a type of visualisation that’s not in the 60 chart reference pages listed on the main part of the website. I already have a long list of charts I want to research and write about, but at the moment it’s too ambitious to go into the depth I would like to go for all of them.
Our monthly reports are on top illustrated with beautiful data visualizations that provide a better understanding of the metrics tracked. These reports offer detailed visual insights into the following areas: Cash management: A comprehensive overview of your organization’s liquidity and existing cash flow situation.
Refer to Introducing the vector engine for Amazon OpenSearch Serverless, now in preview for more information about the new vector search option with OpenSearch Serverless. To learn more about PIT capabilities, refer to Launch highlight: Paginate with Point in Time. Point in Time Point in Time (PIT) search , released in version 2.4
The term business intelligence often also refers to a range of tools that provide quick, easy-to-digest access to insights about an organization’s current state, based on available data. BI aims to deliver straightforward snapshots of the current state of affairs to business managers.
Customers across diverse industries rely on Amazon OpenSearch Service for interactive log analytics, real-time application monitoring, website search, vector database, deriving meaningful insights from data, and visualizing these insights using OpenSearch Dashboards. Under Generate the link as , select Snapshot and choose Copy iFrame code.
Among all reports, the dashboard report is the most typical application that uses various visual elements. So it is often used as a visual representation of the company’s key performance indicators (KPI). If you want to know in more details, you can refer to: Reporting vs Analytics: Why Different & Which is More Needed?
A procurement report allows an organization to demonstrate how its procurement activities deliver value for money, contribute to the realization of its broader goals and objectives, and provide a panoramic snapshot of the effectiveness of its procurement strategy. c) Increase the efficiency of crucial KPIs. Clean your data.
A static report offers a snapshot of trends, data, and information over a predetermined period to provide insight and serve as a decision-making guide. Digestibility: Every robust dynamic reporting tool offers a multitude of stimulating visuals based on clearcut key performance indicators. What Is Static Reporting? Budget Variance.
Refer to Amazon Kinesis Data Streams integrations for additional details. With Kinesis Data Streams, customers can continuously capture terabytes of time series data from thousands of sources for cleaning, enrichment, storage, analysis, and visualization. The raw data can be streamed to Amazon S3 for archiving.
AWS Glue is a serverless data integration service that allows you to visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your data lakes in Iceberg format. Snowflake integrates with AWS Glue Data Catalog to retrieve the snapshot location.
Frequent materialized view refreshes on top of constantly changing base tables due to streamed data can lead to snapshot isolation errors. The near-real-time insights can then be visualized as a performance dashboard using OpenSearch Dashboards. Visualize KPIs of call center performance in near-real time through OpenSearch Dashboards.
To learn more, refer to Exploring new ETL and ELT capabilities for Amazon Redshift from the AWS Glue Studio visual editor. You can also learn more in Visualize over 200 years of global climate data using Amazon Athena and Amazon QuickSight. For instructions, refer to Set up IAM permissions for AWS Glue Studio.
Dashboard reporting refers to putting the relevant business metrics and KPIs in one interface, presenting them visually, dynamic, and in real-time, in the dashboard formats. Instead, data is drawn from a centralized source and displayed as an easy to interpret visual overview. FineReport. Geckoboard. From Google.
Centered on leveraging consumer insights to improve your strategies and communications by using a highly data-driven process can also be referred to as Customer Intelligence (CI). The ability to visualize real-time market changes. Visualize your data. 90% of the information transmitted to our brains is visual.
For Filter by resource type , you can filter by Workgroup , Namespace , Snapshot , and Recovery Point. For more details on tagging, refer to Tagging resources overview. In Cost Explorer, you can visualize daily, monthly, and forecasted spend by combining an array of available filters. Choose Save changes.
A robust process checks source data and work-in-progress at each processing step along the way to polished visualizations, charts, and graphs. These labor-intensive evaluations of data quality can only be performed periodically, so at best they provide a snapshot of quality at a particular time. Writing Tests in Your Tool of Choice.
The third cost component is durable application backups, or snapshots. This is entirely optional and its impact on the overall cost is small, unless you retain a very large number of snapshots. The cost of durable application backup (snapshots) is $0.023 per GB per month. per hour, and attached application storage costs $0.10
We have found that a great starting point is a do-it-yourself visual style guide – which can be developed with very few resources. We have found that developing a style guide for different projects or organizations we work with has been a handy reference tool to help maintain this consistency and a polished look and feel.
By creating visual representations of data flows, organizations can gain a clear understanding of the lifecycle of personal data and identify potential vulnerabilities or compliance gaps. Redshift resources, such as namespaces, workgroups, snapshots, and clusters can be tagged. Tags provide metadata about resources at a glance.
After you create a connection once, you can choose to use the same connection across various AWS Glue components including Glue ETL, Glue Visual ETL and zero-ETL. Step 3: Verify the initial SEED load The SEED load refers to the initial loading of the tables that you want to ingest into an Amazon SageMaker Lakehouse using zero-ETL integration.
Namespaces group together all of the resources you use in Redshift Serverless, such as schemas, tables, users, datashares, and snapshots. To create your namespace and workgroup, refer to Creating a data warehouse with Amazon Redshift Serverless. The SRID defines the spatial reference system to be used when evaluating the geometry data.
To put our definition into a real-world perspective, here’s a hypothetical incremental sales example we’ve created for reference: A green clothing retailer typically sells $14,000 worth of ethical sweaters per month without investing in advertising.
To learn more about how to implement your AWS Glue job scripts locally, refer to Develop and test AWS Glue version 3.0 To learn more about how to achieve unit testing locally, refer to Develop and test AWS Glue version 3.0 jobs locally using a Docker container. Test In the testing phase, you check the implementation for bugs.
For more information, refer to Granting access to monitor queries. This gives a visual representation of peaks and lows in your consumption over your chosen period of time. For a complete list of system views and their uses, refer to Monitoring views. For more information, refer to WLM query monitoring rules.
Data visualisation is the representation of information or data in a visual or graphical form. In fact, 3M did some research and found that humans interpret visuals 60,000 times faster than text or data. In fact, 3M did some research and found that humans interpret visuals 60,000 times faster than text or data.
Data Vault overview For a brief review of the core Data Vault premise and concepts, refer to the first post in this series. For more information, refer to Amazon Redshift database encryption. Automated snapshots retain all of the data required to restore a data warehouse from a snapshot. model in Amazon Redshift.
We discuss how to visualize data quality scores in Amazon DataZone, enable AWS Glue Data Quality when creating a new Amazon DataZone data source, and enable data quality for an existing data asset. If the asset has AWS Glue Data Quality enabled, you can now quickly visualize the data quality score directly in the catalog search pane.
For modern data engineers using Apache Spark, DE offers an all-inclusive toolset that enables data pipeline orchestration, automation, advanced monitoring, visual troubleshooting, and a comprehensive management toolset for streamlining ETL processes and making complex data actionable across your analytic teams.
Additionally, region split/merge operations and snapshot restore/clone operations create links or references to store files, which in the context of store file tracking require the same handling as store files. Snapshot cloning. New store files are also created by compactions and bulk loading.
The result is made available to the application by querying the latest snapshot. The snapshot constantly updates through stream processing; therefore, the up-to-date data is provided in the context of a user prompt to the model. For more information, refer to Notions of Time: Event Time and Processing Time.
Once you’ve identified the information that will help you enhance your CS offerings the most, you will be able to set up a visual data dashboard customized to your needs, goals, and objectives. Essentially, it determines how likely someone is to refer you to their peers.
During the upgrade process, Amazon MWAA captures a snapshot of your environment metadata; upgrades the workers, schedulers, and web server to the new Airflow version; and finally restores the metadata database using the snapshot, backing it with an automated rollback mechanism. The following screenshot shows an example of the UI.
Referring URL's. But remember I have twenty six thousand keywords referring traffic to this blog. The one brand term dominates their referring search keywords. Zach and the team at Juice Analytics have created two powerful visualizations : Referrer Flow and Keyword Tree. It does not matter which report you look at.
Compare replay performance Redshift Test Drive also provides the ability to compare the replay runs visually using a self-hosted UI tool. Take a snapshot of the source Redshift data warehouse. If you’re upgrading from DC2 to RA3 node types, refer to Upgrading to RA3 node types for recommendations.
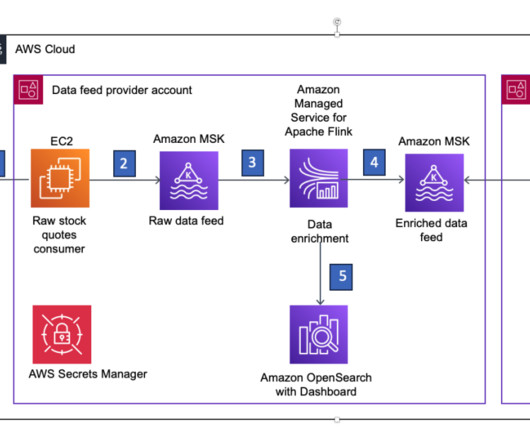
Apache Flink is an opensource distributed processing engine, offering powerful programming interfaces for both stream and batch processing, with first-class support for stateful processing, event time semantics, checkpointing, snapshots and rollback. We refer to this as the producer account.
With Amazon Redshift, you can build lake house architectures and perform any kind of analytics, such as interactive analytics , operational analytics , big data processing , visual data preparation , predictive analytics, machine learning , and more. To create it, refer to Tutorial: Get started with Amazon EC2 Windows instances.
But what’s the business value of highly visualized data if it’s not accurate or if it doesn’t connect you to your actual business strategy? On one hand, BI analytic tools can provide a quick, easy-to-understand visualsnapshot of what appears to be the bottom line. And executives love visuals. Who doesn’t?)
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content