This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Next steps The next step to building a solution to analyze transactional data in near-real time on AWS would be to go through the workshop Enable near real-time analytics on data stored in Amazon DynamoDB using Amazon Redshift.
The workshop provides a step-by-step process for using the training capabilities of SageMaker to carry out hierarchical forecasting using synthetic retail data and the scikit-hts package. Next steps The next step to build an inventory management and forecasting solution on AWS would be to go through the Inventory Management workshop.
The scrum guide specifically refers to the Product Owner as “ Responsible for the product backlog, its content, availability and ordering”. There’s no official “Business Analyst” role in the scrum guide however, as scrum identifies only the Product Owner, Scrum Master and the Development Team.
Data poisoning refers to someone systematically changing your training data to manipulate your model’s predictions. Watermarking is a term borrowed from the deep learning security literature that often refers to putting special pixels into an image to trigger a desired outcome from your model. References and further reading.
Employee engagement refers to the level of commitment employees have to their work, their team’s goals, and their company’s mission. Engaged employees understand their purpose and impact on the organization. Work with managers to incorporate career conversations in regular meetings with their teams.
This makes it even more critical to prepare for your digital transformation initiatives by evaluating your proposals, accounting for risks through contingencies, and ensuring you have clear measurements of success that you can reference to hold your vendor accountable. Failure to do so can cost you millions.
Here’s more info about our workshops, which can be held virtually or in-person. Virtual Workshops. In-Person Workshops. We can refer you to our team of hand-picked experts. If done manually, these tasks would require an extra 10-20 hours of a staff member’s time per client workshop. Learn more at [link].
You’ll also convene workshops articulating strategy and build consensus around what organizational readiness will look like. The right partner will provide high-performing infrastructure, adoption frameworks and reference designs, as well as integrations with key ecosystem partners to help you build. What does that vision look like?
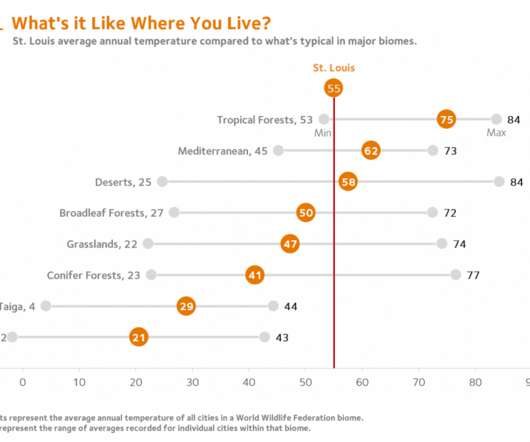
While participating in a workshop he led, a couple of techniques we were using came together. By combining a single point scatter plot and error bars, a reference line can be inserted to mark local conditions. Louis reference line to one appropriate for any student’s home city.
The energy that is saved is referred to as ‘negawatt’, because the electricity for this usage has not had to be produced for these purposes.” Jeremy Roberts, senior workshop director at Info-Tech Research Group, sees potentially significant benefits in the technology.
If you are new to OpenSearch Serverless, refer to Log analytics the easy way with Amazon OpenSearch Serverless to get started. Ingesting the data You can use the load generation scripts shared in the following workshop or you can use your own application or data generator to create load.
After getting familiar with generative AI applications, see the GitHub Text-to-SQL workshop to learn more text-to-SQL techniques. To get started with Amazon Bedrock, we recommend following the quick start in the GitHub repo and familiarizing yourself with building generative AI applications.
Alongside their partner AWS, they participated in AWS Data-Driven Everything (D2E) workshops and a bespoke AWS Immersion Day workshop that catered to their needs to improve their engagement with their customers. Data quality for account and customer data – Altron wanted to enable data quality and data governance best practices.
Business leaders must improve core training programs by installing prompt engineering experts to run workshops that balance theory with practice to help upskill their team members. Online learning platforms such as Coursera, Udacity and edX offer courses taught by experts for organizations who prefer to go that route.
In the next sections, we explore the following topics: The DAG file, in order to understand how to define and then pass the correlation ID in the AWS Glue and EMR tasks The code needed in the Python scripts to output information based on the correlation ID Refer to the GitHub repo for the detailed DAG definition and Spark scripts.
However, with an experienced IT consultant by your side: They can provide training and workshops, easing fears and promoting understanding among team members. Strong References: A good consultant will have a track record of success. Don’t hesitate to ask for references or testimonials.
For an active-active setup, refer to Create an active-active setup using MSK Replicator. For more information, refer to What is Amazon MSK Replicator? For a hands-on experience, try out the Amazon MSK Replicator Workshop. We encourage you to try out this feature and share your feedback with us.
In time series collections, the OCU disk typically contains older shards that are not frequently accessed, referred to as warm shards. Ingest the data You can use the load generation scripts shared in the following workshop , or you can use your own application or data generator to create a load.
LinkedIn partners up for a more diverse IT future Like AllianceBernstein, LinkedIn also partners with job training nonprofit Year Up, but takes the relationship a step further by pairing an employee volunteership program with workshop events for Year Up students.
For a deep-dive into the functionality, refer to the VPA Github repo. Refer to documentation for usage and a walkthrough on how to get started. If not, refer to the Setting up Prometheus and Grafana for monitoring the cluster section of the Running batch workloads on Amazon EKS workshop to get them up and running on your cluster.
BLOOM An open source model developed by the BigScience workshop. There’s a very important difference between these two almost identical sentences: in the first, “it” refers to the cup. In the second, “it” refers to the pitcher. Stable Diffusion An open source model developed by Stability AI for generating images from text.
In Athena, we refer to queries on non-Amazon S3 data sources as federated queries. The term data mesh refers to a data architecture with decentralized data ownership. For instructions, refer to Sharing a data source in Account A with Account B. Note that Account A represents the producer and Account B represents the consumer.
We have collected some of the key talks and solutions on data governance, data mesh, and modern data architecture published and presented in AWS re:Invent 2022, and a few data lake solutions built by customers and AWS Partners for easy reference.
For more information, refer to SaaS Architecture Fundamentals. Refer to the following two-part series for more details on Kafka quotas in Amazon MSK, and an example implementation for IAM authentication. About the Authors Emmanuele Levi is a Solutions Architect in the Enterprise Software and SaaS team, based in London.
For more details, refer to Amazon QuickSight resource type reference. For instructions, refer to Authorizing connections from Amazon QuickSight to Amazon Redshift clusters. For more details, refer to Authorizing connections from Amazon QuickSight to Amazon Redshift clusters. For instructions, see Using a sample dataset.
At the foundation level, you will need to send in a written application that provides your capabilities and competencies, along with a reference from a manager who has “directly observed your behavior in a change management role.” The content of each exam is based on the institute’s Change Manager Competency Model. Exam fee: $4,850.
If you’re new to OpenSearch Serverless, refer to Log analytics the easy way with Amazon OpenSearch Serverless for details on how to set up your collection. For other distros, refer to the artifacts.) You can also refer the Getting started with Amazon OpenSearch Serverless workshop to know more about OpenSearch Serverless.
Cyber resiliency refers to an organization’s ability to prepare for, respond to, and recover from cyber threats while maintaining the continuity of operations. IBM provides a free Cyber Resiliency Assessment, which is conducted through a two-hour virtual workshop with IBM security experts and storage architects.
Refer to Creating and managing Amazon OpenSearch Serverless collections to learn more about creating a collection. Refer to Supported policy permissions and Supported OpenSearch API operations and permissions to set up more granular access for your users. For more information, refer to Add groups and Add users to groups.
Create a VPC endpoint A VPC endpoint enables you to privately access your OpenSearch Serverless collection using AWS PrivateLink (for more information, refer to Access AWS services through AWS PrivateLink ). Refer to Getting Started with Amazon VPC to learn more.
We are pleased to present our work accepted at the NeurIPS 2022 Workshop on Human in the Loop Learning ! For a complete overview of our work, we refer to our paper and the OpenAL GitHub repository.
For instructions, refer to Installing the Elastic Stack. Refer to the full list of services supported by the Elastic/AWS integration for more information. Refer to the following screenshot for the destination settings, and for more details, refer to Choose Elastic for Your Destination.
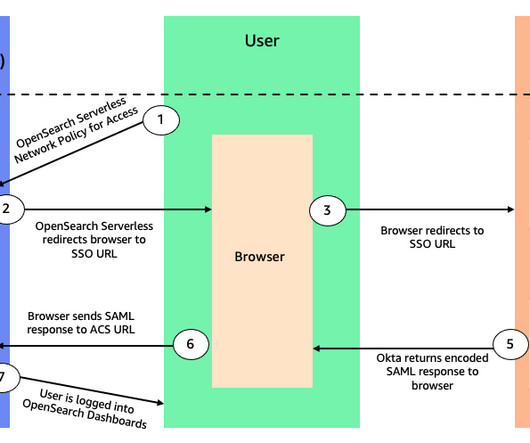
For instructions, refer to Preview: Amazon OpenSearch Serverless – Run Search and Analytics Workloads without Managing Clusters. For more details, refer to SAML authentication for Amazon OpenSearch Serverless. You can also refer to the Getting started with Amazon OpenSearch Serverless workshop to know more about OpenSearch Serverless.
For instructions, refer to Installing or updating the latest version of the AWS CLI. For instructions, refer to Configuration and credential file settings. For instructions on setting up the Spark History Server and exploring the logs, refer to Launching the Spark history server and viewing the Spark UI using Docker.
Prerequisites For instructions to set up your environment for implementing the solution proposed in this post, refer to Deploy the application in the GitHub repo. It passes a reference from vpcstack to dbstack, and a reference from both vpcstack and dbstack to gluestack. modules, respectively.
It provides meaningful references for the team and helps the team generate actionable insights, transforming the acquired information into actions. The dashboard helps to measure teams’ or workshops’ ability through ability indicators such as production process. The dashboard uses real-time data to track the project in real time.
For more information, refer to Building a semantic search engine in OpenSearch to learn how semantic search can deliver a 15% relevance improvement, as measured by normalized discounted cumulative gain (nDCG) metrics compared with keyword search. You can refer to Memory Estimation for more details. This is set to 0.5.
The RPA market may grow to $25 billion in 2025 according to Forrester, and it has the promise of supporting digital transformation through streamlining digital transformation ( Reference ).
It is also possible to generate timely reports and store them for reference. Disaster restoration software helps provide necessary documents, videos, or other resources to either provide DIY training on facilitate live workshops.
Please reference user documentation for installation and configuration of Cloudera Data Platform Private Cloud Base 7.1.9 Please note, you can also leverage Flink and SQL Stream Builder in CSA 1.11 as well for streaming ingestion. We use NiFi to ingest an airport route data set (JSON) and send that data to Kafka and Iceberg.
Refer to Introducing the vector engine for Amazon OpenSearch Serverless, now in preview for more information about the new vector search option with OpenSearch Serverless. To learn more about PIT capabilities, refer to Launch highlight: Paginate with Point in Time. Point in Time Point in Time (PIT) search , released in version 2.4
KPI dashboard contains four types of KPIs, namely: Performance indicators: Performance indicators refer to the quantifiable indicators that inspect the completion of the company’s established goals by various departments and employees within a fixed period of time. The goals set by the enterprise or organization need to be realistic.
In the book Carmen references the 2012 Obama Campaign. Book a Discovery Workshop. What do they want to know more of? Then actually building the systems and processes to bring it altogether to action those insights and provide that experience.
You can encourage feedback through surveys, workshops and open dialog. For example: Data cataloging – Organization’s implementing a data governance framework will benefit from automated metadata harvesting, data mapping, code generation and data lineage with reference data management, lifecycle management and data quality.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content