This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, we are excited to announce an enhancement to the Amazon MWAA integration with the Airflow REST API. This improvement streamlines the ability to access and manage your Airflow environments and their integration with external systems, and allows you to interact with your workflows programmatically.
Amazon AppFlow is a fully managed integration service that you can use to securely transfer data from software as a service (SaaS) applications, such as Google BigQuery, Salesforce, SAP, HubSpot, and ServiceNow, to Amazon Web Services (AWS) services such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, in just a few clicks.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. This approach also reduces expensive ListObjects API calls typically needed when directly accessing Parquet files in Amazon S3.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). Modern data architectures use APIs to make it easy to expose and share data. Data integrity. Flexibility.
From generating test cases and Cypress code to AI-powered code reviews and detailed defect reports, our platform streamlines QA processes, saving time and resources. Accelerate API testing with Pytest-based cases and boost accuracy while reducing human error.
In the first part of this series , we demonstrated how to implement an engine that uses the capabilities of AWS Lake Formation to integrate third-party applications. With its libraries, CLI, and services, you can connect your frontend to the cloud for authentication, storage, APIs, and more.
The Amazon Redshift Data API simplifies access to your Amazon Redshift data warehouse by removing the need to manage database drivers, connections, network configurations, data buffering, and more. The Redshift Data API is the recommended method to connect with Amazon Redshift for web applications.
Snapshots play a critical role in providing the availability, integrity and ability to recover data in OpenSearch Service domains. This guide is designed to help you maintain data integrity and continuity while navigating complex multi-Region and multi-account environments in OpenSearch Service. Add a bucket policy.
Flexibility in payment models, where they only pay for the resource usage they need, for instance, is attractive for many organizations in today’s competitive world. The growing need for API connections. 3) The Growing Need For API Connections. At first, SaaS providers didn’t come with a complete integration solution.
By integrating and refining data through these modern solutions, insurers can enhance the accuracy of risk assessments, reduce claims payout time by over 50%, and boost operational efficiency by more than 30%. Integrating advanced technologies like genAI often requires extensively reengineering existing systems.
The product manager for the research phase understands that AI Research products are first and foremost products, and therefore develops all of the necessary tools, structure, relationships, and resources needed to be successful. Finally, integrating AI products into business tech stacks (especially in enterprises) is nontrivial.
Although the integration with AWS IAM Identity Center is the recommended approach, this post focuses on setups where IAM Identity Center might not be applicable due to compliance constraints, such as organizations requiring FedRAMP Moderate compliance, which IAM Identity Center doesnt yet meet. Choose Create a resource.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machine learning services to streamline the user journey from data to insight. It comprises distinct AWS account types, each serving a specific purpose.
The need to integrate diverse data sources has grown exponentially, but there are several common challenges when integrating and analyzing data from multiple sources, services, and applications. First, you need to create and maintain independent connections to the same data source for different services.
What began with chatbots and simple automation tools is developing into something far more powerful AI systems that are deeply integrated into software architectures and influence everything from backend processes to user interfaces. An important aspect of this democratization is the availability of LLMs via easy-to-use APIs.
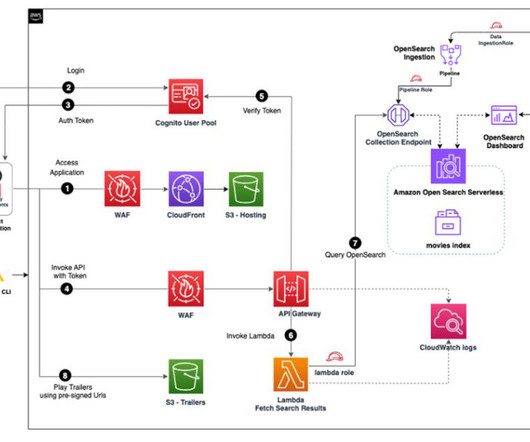
For each user query, an API is invoked on Amazon API Gateway to process the request. The API is integrated with AWS Lambda , which processes the user query and generates the answers based on available documents and user access using retrieval augmented generation (RAG).
Many of the new open source models are much smaller and not as resource intensive but still deliver good results (especially when trained for a specific application). We suspect that many API services are being offered as loss leaders—that the major providers have intentionally set prices low to buy market share.
SAP Datasphere has arrived to address those pain points, by enabling discovery, access, and integration of the heterogeneous data distributed across the enterprise. Datasphere manages and integrates structured, semi-structured, and unstructured data types. Datasphere is not just for data managers.
In the rapidly evolving landscape of AI-powered search, organizations are looking to integrate large language models (LLMs) and embedding models with Amazon OpenSearch Service. Now through a single Rerank API call in Amazon Bedrock, you can integrate Rerank into existing systems at scale. How to integrate Cohere Rerank 3.5
Zero-ETL integration with Amazon Redshift reduces the need for custom pipelines, preserves resources for your transactional systems, and gives you access to powerful analytics. In this post, we explore how to use Aurora MySQL-Compatible Edition Zero-ETL integration with Amazon Redshift and dbt Cloud to enable near real-time analytics.
It is a powerful deployment environment that enables you to integrate and deploy generative AI (GenAI) and predictive models into your production environments, incorporating Cloudera’s enterprise-grade security, privacy, and data governance. This is where the Cloudera AI Inference service comes in. We also outlined many of its capabilities.
Spark Upgrades addresses four key areas of changes: Spark SQL API methods and functions Spark DataFrame API methods and operations Python language updates (including module deprecations and syntax changes) Spark SQL and Core configuration settings The complexity of these upgrades becomes evident when you consider migrating from Spark 2.4.3
This allows your teams to flexibly scale write workloads such as extract, transform, and load (ETL) and data processing by adding compute resources of different types and sizes based on individual workloads price-performance requirements, as well as securely collaborate with other teams on live data for use cases such as customer 360.
Flows can be programmatically exported, deployed, and scaled on any OpenSearch 2.19+ cluster through OpenSearchs existing ingest, index, workflow and search APIs. You can use the flow builder through APIs or a visual designer. Flows are a pipeline of processor resources. Each project contains at least one ingest or search flow.
It provides data catalog, automated crawlers, and visual job creation to streamline data integration across various data sources and targets. It is a data marketplace featuring over 300 providers offering thousands of datasets accessible through files, Amazon Redshift tables, and APIs. AWS Glue is used for this integration.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. However, this task is complicated by the unique characteristics of modern systems, such as differing API protocols, implementations, and rate limits.
Automating routine office tasks is an important and worthwhile project–and redesigning routine tasks so that they can be integrated into a larger workflow that can be automated more effectively is even more important. So from the start, we have a data integration problem compounded with a compliance problem.
The following diagram illustrates solution architecture, which manages stored objects using a continuous integration and delivery (CI/CD) pipeline. Jenkins runs an OpenSearch Service API to deploy changes. A new commit invokes a build job in Jenkins. Jenkins retrieves JSON files from the GitHub repository and performs validation.
Second, doing something new (especially something “big” and disruptive) must align with your business objectives – otherwise, you may be steering your business into deep uncharted waters that you haven’t the resources and talent to navigate. Remember to Keep it Simple and Smart (the “KISS” principle ).
That’s great to have because you can use that storage platform to build a data fabric that extends from your on-premises systems into multiple cloud systems to get access to data at a performance level and with an API that you want. Most of the work so far in Kubernetes involves the use of file system APIs.
Serverless can also bring cost reductions, as users only pay for the resources used. Each worker node has an agent called kubelet that connects it to the Kubernetes API. Kubectl also uses PodSpecs to manage the underlying pods whenever a kubelet is running on a server and connected to K8s API. Kubernetes without Nodes?
Invoke a Lambda function as the target for the EventBridge rule and pass the event payload to it: The Lambda function does 2 things: Fetches the asset details, including the Amazon Resource Name (ARN) of the S3 published asset and the IAM role ARN from the subscription target.
This encompasses tasks such as integrating diverse data from various sources with distinct formats and structures, optimizing the user experience for performance and security, providing multilingual support, and optimizing for cost, operations, and reliability. API Gateway forwards all requests to the Lambda function to serve up the requests.
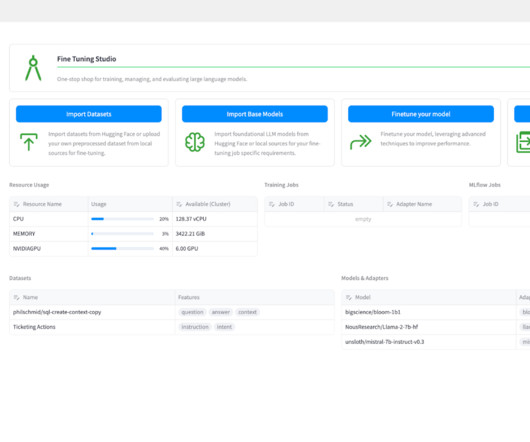
Several LLMs are publicly available through APIs from OpenAI , Anthropic , AWS , and others, which give developers instant access to industry-leading models that are capable of performing most generalized tasks. The training jobs use Cloudera’s Workbench compute resources, and users can track the performance of a training job within the UI.
You can use this approach for a variety of use cases, from real-time log analytics to integrating application messaging data for real-time search. OpenSearch Ingestion integrates with many AWS services, and provides ready-made blueprints to accelerate ingesting data for a variety of analytics use cases into OpenSearch Service domains.
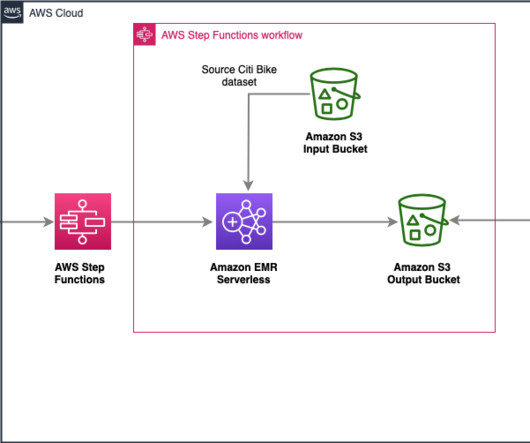
You can run analytics workloads at any scale with automatic scaling that resizes resources in seconds to meet changing data volumes and processing requirements. EMR Serverless automatically scales resources up and down to provide just the right amount of capacity for your application, and you only pay for what you use.
Further complicating matters, Microsoft suspects that DeepSeek AI misused OpenAI APIs to harvest substantial amounts of data, potentially infringing on intellectual property rights. The reported incident revealed that DeepSeek AI had left its ClickHouse database accessible to the public, exposing over one million lines of log entry data.
Data volume can increase significantly over time, and it often requires concurrent consumption of large compute resources. Data integration workloads can become increasingly concurrent as more and more applications demand access to data at the same time. It simplifies your daily operation and reduces latency for the retries.
Kinesis Data Streams not only offers the flexibility to use many out-of-box integrations to process the data published to the streams, but also provides the capability to build custom stream processing applications that can be deployed on your compute fleet. This allows you to process the same data with fewer compute resources.
In this two-part series, we show how to integrate custom applications or data processing engines with Lake Formation using the third-party services integration feature. In this post, we dive deep into the required Lake Formation and AWS Glue APIs. We discuss in later sections how these tags are used.
However, digital infrastructures are highly dependent on application programming interfaces — or APIs — to facilitate data transfers between software applications and between applications and end users. As the backend framework for most web and mobile apps, APIs are internet-facing and therefore vulnerable to attacks.
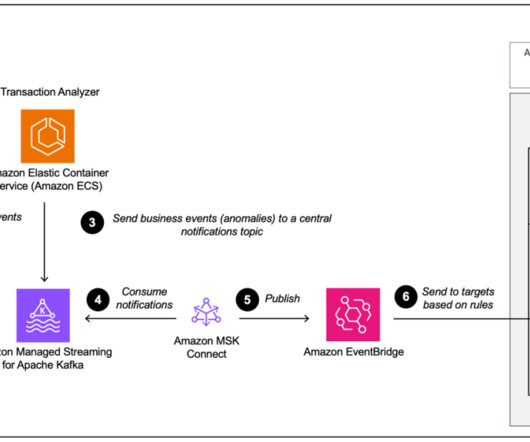
MSK Connect now supports the ability to delete MSK Connect worker configurations, tag resources, and manage worker configurations and custom plugins using AWS CloudFormation. Together, these new capabilities make it straightforward to manage your MSK Connect resources and automate deployments through CI/CD pipelines.
If the use case is well defined and directly maps to one event bus, such as event streaming and analytics with streaming events (Kafka) or application integration with simplified and consistent event filtering, transformation, and routing on discrete events (EventBridge), the decision for a particular broker technology is straightforward.
Cost-effective Use resources in an efficient, cost-effective way. Aim to minimize situations where resources are running idly while waiting for other processes to be completed. As a result, we simplified the way we defined the resources we wanted to deploy while using our preferred coding language for development.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content