This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Get Off The Blocks Fast: Data Quality In The Bronze Layer Effective Production QA techniques begin with rigorous automated testing at the Bronze layer , where raw data enters the lakehouse environment. Data Drift Checks (does it make sense): Is there a shift in the overall data quality?
To counter such statistics, CIOs say they and their C-suite colleagues are devising more thoughtful strategies. Its typical for organizations to test out an AI use case, launching a proof of concept and pilot to determine whether theyre placing a good bet. As part of that, theyre asking tough questions about their plans.
Unexpected outcomes, security, safety, fairness and bias, and privacy are the biggest risks for which adopters are testing. We’re not encouraging skepticism or fear, but companies should start AI products with a clear understanding of the risks, especially those risks that are specific to AI.
The risk of data breaches will not decrease in 2021. Data breaches and security risks happen all the time. One bad breach and you are potentially risking your business in the hands of hackers. In this blog post, we discuss the key statistics and prevention measures that can help you better protect your business in 2021.
From search engines to navigation systems, data is used to fuel products, manage risk, inform business strategy, create competitive analysis reports, provide direct marketing services, and much more. This playbook contains: Exclusive statistics, research, and insights into how the pandemic has affected businesses over the last 18 months.
— Thank you to Ann Emery, Depict Data Studio, and her Simple Spreadsheets class for inviting us to talk to them about the use of statistics in nonprofit program evaluation! But then we realized that much of the time, statistics just don’t have much of a role in nonprofit work. Why Nonprofits Shouldn’t Use Statistics.
John Myles White , data scientist and engineering manager at Facebook, wrote: “The biggest risk I see with data science projects is that analyzing data per se is generally a bad thing. So when you’re missing data or have “low-quality data,” you use assumptions, statistics, and inference to repair your data.
“The flashpoint moment is that rather than being based on rules, statistics, and thresholds, now these systems are being imbued with the power of deep learning and deep reinforcement learning brought about by neural networks,” Mattmann says. Adding smarter AI also adds risk, of course. “At We do lose sleep on this,” he says.
1] This includes C-suite executives, front-line data scientists, and risk, legal, and compliance personnel. These recommendations are based on our experience, both as a data scientist and as a lawyer, focused on managing the risks of deploying ML. 6] Debugging may focus on a variety of failure modes (i.e., Sensitivity analysis.
This simplifies data modification processes, which is crucial for ingesting and updating large volumes of market and trade data, quickly iterating on backtesting and reprocessing workflows, and maintaining detailed audit trails for risk and compliance requirements. At petabyte scale, Icebergs advantages become clear.
This provides a great amount of benefit, but it also exposes institutions to greater risk and consequent exposure to operational losses. The stakes in managing model risk are at an all-time high, but luckily automated machine learning provides an effective way to reduce these risks.
In recent posts, we described requisite foundational technologies needed to sustain machine learning practices within organizations, and specialized tools for model development, model governance, and model operations/testing/monitoring. Note that the emphasis of SR 11-7 is on risk management.). Sources of model risk.
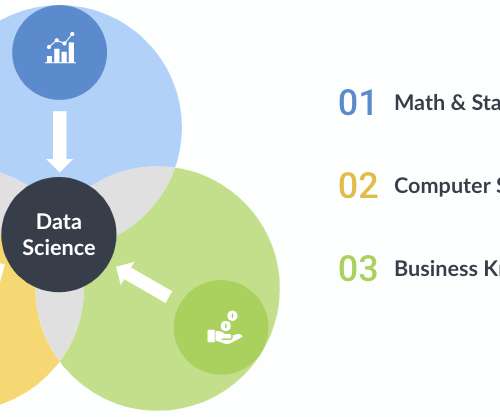
A data scientist must be skilled in many arts: math and statistics, computer science, and domain knowledge. Statistics and programming go hand in hand. Mastering statistical techniques and knowing how to implement them via a programming language are essential building blocks for advanced analytics. Linear regression.
You’ll want to be mindful of the level of measurement for your different variables, as this will affect the statistical techniques you will be able to apply in your analysis. There are basically 4 types of scales: *Statistics Level Measurement Table*. 5) Which statistical analysis techniques do you want to apply?
This widespread cloud transformation set the stage for great innovation and growth, but it has also significantly increased the associated risks and complexity of data security, especially the protection of sensitive data. If a business operates in the cloud, especially the public cloud, it will be subject to cloud data security risk.
A catalog or a database that lists models, including when they were tested, trained, and deployed. The technologies I’ve alluded to above—data governance, data lineage, model governance—are all going to be useful for helping manage these risks. There are real, not just theoretical, risks and considerations.
They are then able to take in prompts and produce outputs based on the statistical weights of the pretrained models of those corpora. And when a question goes beyond the limits of possible citations, the tool will simply reply “I don’t know” rather than risk hallucinating.
What is it, how does it work, what can it do, and what are the risks of using it? It’s by far the most convincing example of a conversation with a machine; it has certainly passed the Turing test. And it can look up an author and make statistical observations about their interests. But it is an amazing analytic engine.”
It’s ironic that, in this article, we didn’t reproduce the images from Marcus’ article because we didn’t want to risk violating copyright—a risk that Midjourney apparently ignores and perhaps a risk that even IEEE and the authors took on!) To see this, let’s consider another example, that of MegaFace. joined Flickr.
More often than not, it involves the use of statistical modeling such as standard deviation, mean and median. Let’s quickly review the most common statistical terms: Mean: a mean represents a numerical average for a set of responses. Standard deviation: this is another statistical term commonly appearing in quantitative analysis.
The chief aim of data analytics is to apply statistical analysis and technologies on data to find trends and solve problems. Data analytics draws from a range of disciplines — including computer programming, mathematics, and statistics — to perform analysis on data in an effort to describe, predict, and improve performance.
Predictive analytics encompasses techniques like data mining, machine learning (ML) and predictive modeling techniques like time series forecasting, classification, association, correlation, clustering, hypothesis testing and descriptive statistics to analyze current and historical data and predict future events, results and business direction.
This is one of the major trends chosen by Gartner in their 2020 Strategic Technology Trends report , combining AI with autonomous things and hyperautomation, and concentrating on the level of security in which AI risks of developing vulnerable points of attacks. Industries harness predictive analytics in different ways.
Bad data reaches the customer because companies haven’t invested enough, or at all, in testing, automation, and monitoring. A survey of data engineers conducted by DataKitchen in 2022 revealed some shocking statistics. ” When the fix is fully tested and deployed to the production pipeline, Jason has time to reflect.
We kept adding tests over time; it has been several years since we’ve had any major glitches. Our vision was to create a flexible, state-of-the-art data infrastructure that would allow our analysts to transform the data rapidly with a very low risk of error. Data errors can cause compliance risks. That was amazing for the team.”
In addition, they can use statistical methods, algorithms and machine learning to more easily establish correlations and patterns, and thus make predictions about future developments and scenarios. If a database already exists, the available data must be tested and corrected. Subsequently, the reporting should be set up properly.
As he thinks through the various journeys that data take in his company, Jason sees that his dashboard idea would require extracting or testing for events along the way. Data and tool tests. DataOps Observability must also store run data over time for root cause diagnosis and statistical process control analysis.
Modern machine learning and back-testing; how quant hedge funds use it. Similarly, hedge funds often use modern machine learning and back-testing to analyze their quant models. Here, the models get tested using historical data to evaluate their profitability. And their risks before the organizations invest real money.
Large banking firms are quietly testing AI tools under code names such as as Socrates that could one day make the need to hire thousands of college graduates at these firms obsolete, according to the report. But that’s just the tip of the iceberg for a future of AI organizational disruptions that remain to be seen, according to the firm.
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. This has serious implications for software testing, versioning, deployment, and other core development processes. Machine learning adds uncertainty.
In this post, well see the fundamental procedures, tools, and techniques that data engineers, data scientists, and QA/testing teams use to ensure high-quality data as soon as its deployed. First, we look at how unit and integration tests uncover transformation errors at an early stage. Key Tools & Processes Testing frameworks (e.g.,
Charles Dickens’ Tale of Two Cities contrasts London’s order and safety with the chaos and risk of Paris. The CIO so-what test Given Apple’s status as company with the world’s second-highest market capitalization and second-highest overall profitability it’s hard to be too critical. And therein lies a cautionary tale for all CIOs.
Through a marriage of traditional statistics with fast-paced, code-first computer science doctrine and business acumen, data science teams can solve problems with more accuracy and precision than ever before, especially when combined with soft skills in creativity and communication. Math and Statistics Expertise.
Starting today, the Athena SQL engine uses a cost-based optimizer (CBO), a new feature that uses table and column statistics stored in the AWS Glue Data Catalog as part of the table’s metadata. By using these statistics, CBO improves query run plans and boosts the performance of queries run in Athena.
It is an interdisciplinary field, combining computer science, statistics , mathematics, and business intelligence. Data Analysis The cleaned data is then analyzed using various statistical techniques and algorithms. This could involve identifying patterns and trends, testing hypotheses, or making predictions.
Managing tests of complex data transformations when automated data testing tools lack important features? While numerous commercial and open-source tools facilitate standard data quality checks, they often fall short when addressing advanced or specialized testing requirements. High domain specificity: Many advanced checks (e.g.,
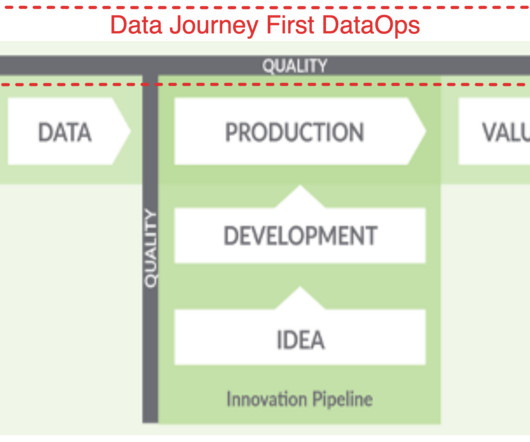
This innovative approach merges the agility of Agile Development, the stability of DevOps, and the meticulousness of Statistical Process Controls, orchestrating a dynamic, enriched, and nimble data ecosystem that is truly remarkable. They need help creating data tests and observing the entire Data Journey for success.
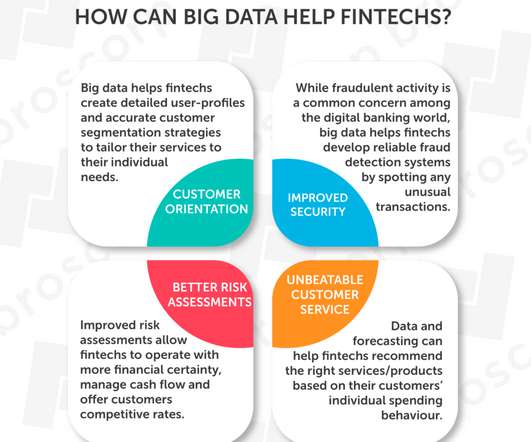
Statistics show that 93% of customers will offer repeat business when they encounter a positive customer experience. They can also anticipate industry trends, assess risks, and make strategic steps to elevate the customer experience. Improving Risk Assessment. Better UI/UX based on A/B testing. Improving Security.
As a result of the resolution of risks and the creation of hypotheses, data analysis assists businesses in generating sound business choices. The most significant benefit of statistical analysis is that it is completely impartial. Statistics allows an organisation to make choices based on the data that are available to them.
This is an example of Simpon’s paradox , a statistical phenomenon in which a trend that is present when data is put into groups reverses or disappears when the data is combined. It’s time to introduce a new statistical term. A new drug promising to reduce the risk of heart attack was tested with two groups.
One of the biggest benefits is testing processes for optimal effectiveness. The main purpose of machine learning is to partially or completely replace manual testing. One example is using machine learning tools like Selenium to test web development processes. There are a number of great applications of machine learning.
With those stakes and the long forecast horizon, we do not rely on a single statistical model based on historical trends. For example, we may prefer one model to generate a range, but use a second scenario-based model to “stress test” the range. A single model may also not shed light on the uncertainty range we actually face.
Synthetic data can be generated to reflect the same statistical characteristics as real data, but without revealing personally identifiable information, thereby complying with privacy-by – design regulations and other sensitive details. An example is Alpha Fold, widely used in structural biology and bioinformatics,” he says.
To start with, SR 11-7 lays out the criticality of model validation in an effective model risk management practice: Model validation is the set of processes and activities intended to verify that models are performing as expected, in line with their design objectives and business uses.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content