This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. Machine learning adds uncertainty. Underneath this uncertainty lies further uncertainty in the development process itself.
Gen AI has the potential to magnify existing risks around data privacy laws that govern how sensitive data is collected, used, shared, and stored. We’re getting bombarded with questions and inquiries from clients and potential clients about the risks of AI.” The risk is too high.” Not without warning signs, however.
In addition, they can use statistical methods, algorithms and machine learning to more easily establish correlations and patterns, and thus make predictions about future developments and scenarios. Most use master data to make daily processes more efficient and to optimize the use of existing resources.
This classification is based on the purpose, horizon, update frequency and uncertainty of the forecast. With those stakes and the long forecast horizon, we do not rely on a single statistical model based on historical trends. A single model may also not shed light on the uncertainty range we actually face.
After Banjo CEO Damien Patton was exposed as a member of the Ku Klux Klan, including involvement in an anti-Semitic drive-by shooting, the state put the contract on hold and called in the state auditor to check for algorithmic bias and privacy risks in the software. The good news was the software posed less risk to privacy than suspected.
This was not a scientific or statistically robust survey, so the results are not necessarily reliable, but they are interesting and provocative. These may not be high risk. The results showed that (among those surveyed) approximately 90% of enterprise analytics applications are being built on tabular data.
Surely there are ways to comb through the data to minimise the risks from spiralling out of control. Systems should be designed with bias, causality and uncertainty in mind. Uncertainty is a measure of our confidence in the predictions made by a system. We need to get to the root of the problem. System Design.
4 Additionally, while 63% have guardrails in place to use AI safely, these organizations worry about its role in misinformation, ethical bias and job loss among other risks, Wavestone found. Even as organizations plan to boost spending on genAI in 2024. The playbook marries organizational readiness with governance and iterative development.
The objectives were lofty: integrated, scalable, and replicable enterprise management; streamlined business processes; and visualized risk control, among other aims, all fully integrating finance, logistics, production, and sales.
Most commonly, we think of data as numbers that show information such as sales figures, marketing data, payroll totals, financial statistics, and other data that can be counted and measured objectively. All descriptive statistics can be calculated using quantitative data. Digging into quantitative data. This is quantitative data.
This overall lack of engagement leads to a sense of detachment, increasing the risk that many in your department may quit or completely check-out in their role. Women disproportionately affected by burnout For women, the statistics around burnout are even worse.
Cybersecurity risks This one is no surprise, given the scary statistics on the growing number of cyberattacks, the rate of successful attacks, and the increasingly high consequences of being breached. They’re wondering how AI technologies, such as ChatGPT and generative AI in general, will increase risks.
These circumstances have induced uncertainty across our entire business value chain,” says Venkat Gopalan, chief digital, data and technology officer, Belcorp. “As Finally, our goal is to diminish consumer risk evaluation periods by 80% without compromising the safety of our products.” This allowed us to derive insights more easily.”
But importance sampling in statistics is a variance reduction technique to improve the inference of the rate of rare events, and it seems natural to apply it to our prevalence estimation problem. High Risk 10% 5% 33.3% Statistical Science. Statistics in Biopharmaceutical Research, 2010. [4] How Many Strata?
This process is designed to help mitigate risks so that model outputs can be deployed responsibly with the assistance of watsonx.data and watsonx.governance (coming soon). For many businesses and organizations, this can introduce uncertainties that slow adoption of generative AI, particularly in highly regulated industries.
One reason to do ramp-up is to mitigate the risk of never before seen arms. For example, imagine a fantasy football site is considering displaying advanced player statistics. A ramp-up strategy may mitigate the risk of upsetting the site’s loyal users who perhaps have strong preferences for the current statistics that are shown.
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. Crucially, it takes into account the uncertainty inherent in our experiments.
By connecting solutions across the insightsoftware portfolio, organizations can now choose the capabilities they need for effective reporting, controllership, and budgeting and planning, while improving productivity, user experience, and reducing implementation risk. Good things happen when you’re well connected.
Markets and competition today are highly dynamic and complex, and the future is characterized by uncertainty – not least because of COVID-19. This uncertainty is currently at the forefront of everyone‘s minds. Simulations are the basis for the well-founded analysis and evaluation of alternative actions, opportunities and risks.
Markets and competition today are highly dynamic and complex, and the future is characterized by uncertainty – not least because of COVID-19. This uncertainty is currently at the forefront of everyone‘s minds. Simulations are the basis for the well-founded analysis and evaluation of alternative actions, opportunities and risks.
Quantification of forecast uncertainty via simulation-based prediction intervals. Such a model risks conflating important aspects, notably the growth trend, with other less critical aspects. In other words, there is an asymmetry of risk-reward when there exists the possibility of misspecifying the weights in $X_C$.
LLMs like ChatGPT are trained on massive amounts of text data, allowing them to recognize patterns and statistical relationships within language. The AGI would need to handle uncertainty and make decisions with incomplete information. NLP techniques help them parse the nuances of human language, including grammar, syntax and context.
For example, applying machine learning to wind forecasting is expected to reduce uncertainty in wind energy production by more than 45% and will allow utilities to integrate wind more easily with traditional forms of power supply. Identify those most at risk or most affected by a problem more accurately by using predictive analytics.
Integrity of statistical estimates based on Data. Having spent 18 years working in various parts of the Insurance industry, statistical estimates being part of the standard set of metrics is pretty familiar to me [7]. The thing with statistical estimates is that they are never a single figure but a range. million ± £0.5
Of course it can be argued that you can use statistics (and Google Trends in particular) to prove anything [1] , but I found the above figures striking. King was a wise King, but now he was gripped with uncertainty. For example in 20 Risks that Beset Data Programmes. . [7]. And a more competent Chief Risk Officer. .
Statistical power is traditionally given in terms of a probability function, but often a more intuitive way of describing power is by stating the expected precision of our estimates. This is a quantity that is easily interpretable and summarizes nicely the statistical power of the experiment. In the U.S.,
All you need to know, for now, is that machine learning is a field of artificial intelligence that uses statistical techniques to give computer systems the ability to learn based on data by being trained on past examples. I assume a good number of people here have a fair amount of background there.
Because of this trifecta of errors, we need dynamic models that quantify the uncertainty inherent in our financial estimates and predictions. Practitioners in all social sciences, especially financial economics, use confidence intervals to quantify the uncertainty in their estimates and predictions.
Researchers, of course, try to use sophisticated statistical techniques to get around these problems, and have attempted to provide their best estimates for outbreaks around the world. A more flexible way of attacking uncertainty is to look beyond specific models and instead benchmark against “other people like us.”
Using variability in machine learning predictions as a proxy for risk can help studio executives and producers decide whether or not to green light a film project Photo by Kyle Smith on Unsplash Originally posted on Toward Data Science. and even set their risk tolerance. and even set their risk tolerance.
He was saying this doesn’t belong just in statistics. It involved a lot of work with applied math, some depth in statistics and visualization, and also a lot of communication skills. You see these drivers involving risk and cost, but also opportunity. They’re being told they have to embrace uncertainty.
Unlike experimentation in some other areas, LSOS experiments present a surprising challenge to statisticians — even though we operate in the realm of “big data”, the statisticaluncertainty in our experiments can be substantial. We must therefore maintain statistical rigor in quantifying experimental uncertainty.
Although COVID-19 tracking data is highly complex and is subject to many data quality issues, it is still better to release good-enough data to inform decision making, rather than to take the risk of losing more lives without using any data. In the case of the pandemic, the purpose of COVID-19 data is to inform and support better decisions.
1) What Is A Misleading Statistic? 2) Are Statistics Reliable? 3) Misleading Statistics Examples In Real Life. 4) How Can Statistics Be Misleading. 5) How To Avoid & Identify The Misuse Of Statistics? If all this is true, what is the problem with statistics? What Is A Misleading Statistic?
Factory shutdowns, shipping bottlenecks, and shortages of raw materials have led to substantial uncertainty for businesses seeking to address the vicissitudes of supply-side availability. Statistical demand forecasting may use complex formulas and algorithms to extrapolate future demand based on past history.
We know, statistically, that doubling down on an 11 is a good (and common) strategy in blackjack. But when making a decision under uncertainty about the future, two things dictate the outcome: (1) the quality of the decision and (2) chance. Consider risk not only in terms of likelihood but also in terms of the impact of your decisions.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















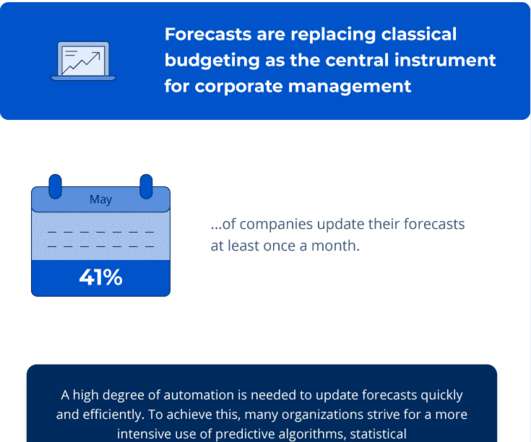






















Let's personalize your content