This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost. at Facebook—both from 2020.
We’re thrilled to announce the launch of the official Amazon OpenSearch Service YouTube channel —a comprehensive resource for anyone looking to master Amazon OpenSearch Service. Amazon OpenSearch Service is a managed service that makes it straightforward to deploy, operate, and scale OpenSearch domains in AWS.
In the rapidly evolving landscape of AI-powered search, organizations are looking to integrate large language models (LLMs) and embedding models with Amazon OpenSearch Service. improves search results for best matching 25 (BM25), a keyword-based algorithm that performs lexical search, in addition to semantic search.
You can now access the AI search flow builder on OpenSearch 2.19+ domains with Amazon OpenSearch Service and begin innovating AI search applications faster. Through a visual designer, you can configure custom AI search flowsa series of AI-driven data enrichments performed during ingestion and search.
Speaker: Speakers from SafeGraph, Facteus, AWS Data Exchange, SimilarWeb, and AtScale
Data and analytics leaders across industries can benefit from leveraging multiple types of diverse external data for making smarter business decisions. Data and analytics specialists from AWS Data Exchange and AtScale will walk through exactly how to blend and operationalize these diverse data external and internal sources.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Curate the data.
We live in a data-rich, insights-rich, and content-rich world. Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and data science. Plus, AI can also help find key insights encoded in data.
In todays economy, as the saying goes, data is the new gold a valuable asset from a financial standpoint. A similar transformation has occurred with data. More than 20 years ago, data within organizations was like scattered rocks on early Earth.
Once the province of the data warehouse team, data management has increasingly become a C-suite priority, with data quality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor data quality is holding back enterprise AI projects.
Download this guide for practical advice on using a semantic layer to improve data literacy and scale self-service analytics. The guide includes a checklist, an assessment, industry-specific use cases, and a data & analytics maturity model and roadmap.
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
Given that, what would you say is the job of a data scientist (or ML engineer, or any other such title)? Building Models. A common task for a data scientist is to build a predictive model. You know the drill: pull some data, carve it up into features, feed it into one of scikit-learn’s various algorithms.
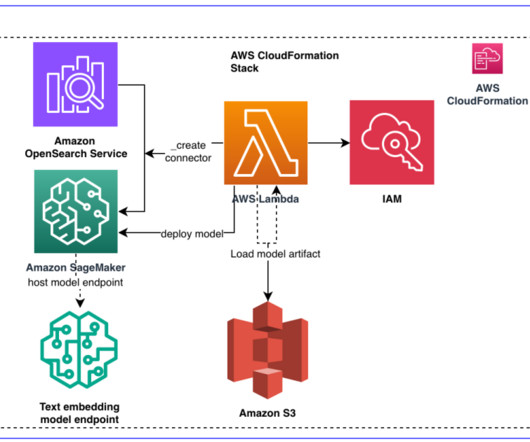
A common adoption pattern is to introduce document search tools to internal teams, especially advanced document searches based on semantic search. The process starts by creating a vector based on the question (embedding) by invoking the embedding model. Then, Lambda replies back to the web interface with the LLM completion (reply).
A look at the landscape of tools for building and deploying robust, production-ready machine learning models. A few factors are contributing to this strong interest in implementing ML in products and services. A collection of tools that focus primarily on aspects of model development, governance, and operations.
While generative AI has been around for several years , the arrival of ChatGPT (a conversational AI tool for all business occasions, built and trained from large language models) has been like a brilliant torch brought into a dark room, illuminating many previously unseen opportunities.
Language understanding benefits from every part of the fast-improving ABC of software: AI (freely available deep learning libraries like PyText and language models like BERT ), big data (Hadoop, Spark, and Spark NLP ), and cloud (GPU's on demand and NLP-as-a-service from all the major cloud providers). IBM Watson NLU.
In an earlier Analyst Perspective , I discussed data democratizations role in creating a data-driven enterprise agenda. Building a foundation of self-servicedata discovery , data-driven organizations provide more workers with the ability to analyze and use data.
AWS recommends Amazon OpenSearch Service as a vector database for Amazon Bedrock as the building blocks to power your solution for these workloads. In this post, youll learn how to use OpenSearch Service and Amazon Bedrock to build AI-powered search and generative AI applications. How do vector databases help prevent AI hallucinations?
Industry analysts who follow the data and analytics industry tell DataKitchen that they are receiving inquiries about “data fabrics” from enterprise clients on a near-daily basis. Gartner included data fabrics in their top ten trends for data and analytics in 2019. What is a Data Fabric?
Large language models (LLMs) such as Anthropic Claude and Amazon Titan have the potential to drive automation across various business processes by processing both structured and unstructured data. RAG uses data sources like Amazon Redshift and Amazon OpenSearch Service to retrieve documents that augment the LLM prompt.
Large language models have allowed BI providers to accelerate the delivery of functionality to convert natural language questions into analytic queries and generate summarizations and recommendations from data and charts. Features that enable natural language query and natural language generation are now ubiquitous.
DeepSeek-R1 is a powerful and cost-effective AI model that excels at complex reasoning tasks. When combined with Amazon OpenSearch Service , it enables robust Retrieval Augmented Generation (RAG) applications. OpenSearch Service provides rich capabilities for RAG use cases, as well as vector embedding-powered semantic search.
Stop wasting time building data access code manually, let the Ontotext Platform auto-generate a fast, flexible, and scalable GraphQL APIs over your RDF knowledge graph. Are you having difficulty joining your knowledge graph APIs with other data sources? This leads to lots of small data fetches to/from GraphDB over the network.
With the launch of the neural search feature for Amazon OpenSearch Service in OpenSearch 2.9, it’s now effortless to integrate with AI/ML models to power semantic search and other use cases. To use neural search, you must set up an ML model. For more information, refer to Introduction to OpenSearch Models.
And yeah, the real-world relationships among the entities represented in the data had to be fudged a bit to fit in the counterintuitive model of tabular data, but, in trade, you get reliability and speed. Ironically, relational databases only imply relationships between data points by whatever row or column they exist in.
Jurgen Mueller, SAP CTO and executive board member, called the innovations, which includes an expanded partnership with data governance specialist Collibra, a “quantum leap” in the company’s ability to help customers drive intelligent business transformation through data. With today’s announcements, SAP is building on that vision.
In this blog post, we will highlight how ZS Associates used multiple AWS services to build a highly scalable, highly performant, clinical document search platform. We use leading-edge analytics, data, and science to help clients make intelligent decisions.
Finding similar columns in a data lake has important applications in data cleaning and annotation, schema matching, data discovery, and analytics across multiple data sources. The solution uses approximate nearest neighbors algorithms available in Amazon OpenSearch Service to search for semantically similar columns.
Despite technological advances, businesses still need help working with data. Data is complex, and companies often need to catch up on what they are trying to achieve. They are also starting to realize – and accept – that data is challenging. What does a sound, intelligent data foundation give you?
Exclusive Bonus Content: Download Data Implementation Tips! It helps managers and employees to keep track of the company’s KPIs and utilizes business intelligence to help companies make data-driven decisions. Organizations can also further utilize the data to define metrics and set goals. Digital age needs digital data.
Partitioning Large Tables Table partitioning has long been an important task in semanticmodel design using SQL Server Analysis Services. Since SSAS Tabular and Power BI models are built on top of the SSAS architecture, the pattern of partitioning remains the same as it has been for twenty years.
In the context of Retrieval-Augmented Generation (RAG), knowledge retrieval plays a crucial role, because the effectiveness of retrieval directly impacts the maximum potential of large language model (LLM) generation. Currently, in RAG retrieval, the most common approach is to use semantic search based on dense vectors.
Amazon OpenSearch Service has long supported both lexical and vector search, since the introduction of its kNN plugin in 2020. OpenSearch Service supports a variety of search and relevance ranking techniques. For the demo, we’re using the Amazon Titan foundation model hosted on Amazon Bedrock for embeddings, with no fine tuning.
Customer relationship management (CRM) software provider Salesforce on Thursday added new capabilities to its Sales Cloud and Service Cloud with updates to its Einstein AI and Data Cloud offerings. It unifies data from all customer meetings to identify cross-company and help enterprises adapt their go-to-market strategy accordingly.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
In many organizations, the focus is on large language models (LLMs), and foundation models (FMs) more broadly. This is just the tip of the iceberg, because what enables you to obtain differential value from generative AI is your data. In essence, you have to enrich the generative AI models with your differentiated data.
Generative AI offers great potential as an interface for enabling users to query your data in unique ways to receive answers honed for their needs. But before using generative AI to answer questions about your data, it’s important to first evaluate the questions being asked. Update as needed as data changes.
The capabilities of these new generative AI tools, most of which are powered by large language models (LLM), forced every company and employee to rethink how they work. Vector Databases To make use of a Large Language Model, you’re going to need to vectorize your data. Enter vector embeddings.
Predicts 2021: Data and Analytics Leaders Are Poised for Success but Risk an Uncertain Future : By 2023, 50% of chief digital officers in enterprises without a chief data officer (CDO) will need to become the de facto CDO to succeed. By 2023, ERP data will be the basis for 30% of AI-generated predictive analyses and forecasts.
SAP and Nvidia announced an expanded partnership today with an eye to deliver the accelerated computing that customers need in order to adopt large language models (LLMs) and generative AI at scale. Herzig notes that SAP has a large ecosystem of partners and various LLM providers, with new LLMs popping up seemingly every day. “At
Over 4,000 attendees saw a lot of demos showing how to effortlessly build a modern data platform with petabytes of data in One Lake, and then ask CoPilot to generate beautiful Power BI reports from semanticmodels that magically appear from data in a Fabric Lakehouse.
Amazon OpenSearch Service is a fully managed service that makes it simple to deploy, scale, and operate OpenSearch in the AWS Cloud. An embedding model, for instance, could encode the semantics of a corpus. A vector database provides efficient vector similarity search by providing specialized indexes like k-NN indexes.
Do this right, and CIOs can help their organizations leapfrog competitors by dramatically improving operations, streamlining marketing, and ratcheting up customer service. CIOs don’t have to panic this month because everyone is just starting out,” said Shaown Nandi, Director of Technology at Amazon Web Services.
There are countless examples of big data transforming many different industries. It can be used for something as visual as reducing traffic jams, to personalizing products and services, to improving the experience in multiplayer video games. We would like to talk about data visualization and its role in the big data movement.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content