This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
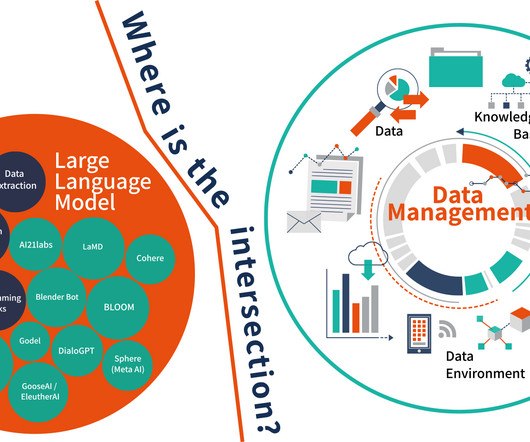
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., at Facebook—both from 2020. What is GraphRAG?
How are we helped when we board the AI hype train? Datasphere empowers data democratization, by providing all business users with self-service data access, including virtual data products that can be stored, re-used, and shared. This is where SAP Datasphere (the next generation of SAP Data Warehouse Cloud) comes in.
In the rapidly evolving landscape of AI-powered search, organizations are looking to integrate large language models (LLMs) and embedding models with Amazon OpenSearch Service. improves search results for best matching 25 (BM25), a keyword-based algorithm that performs lexical search, in addition to semantic search.
For example, when a retail data analyst creates customer segmentation reports, those same datasets are now being used by AI teams to train recommendation engines. Or customer service teams analyzing call logs to track common issues are now using that data to train AI chatbots to handle routine inquiries.
This approach is repeatable, minimizes dependence on manual controls, harnesses technology and AI for data management and integrates seamlessly into the digital product development process. Similarly, there is a case for Snowflake, Cloudera or other platforms, depending on the companys overarching technology strategy.
But that’s exactly the kind of data you want to include when training an AI to give photography tips. Conversely, some of the other inappropriate advice found in Google searches might have been avoided if the origin of content from obviously satirical sites had been retained in the training set.
While generative AI has been around for several years , the arrival of ChatGPT (a conversational AI tool for all business occasions, built and trained from large language models) has been like a brilliant torch brought into a dark room, illuminating many previously unseen opportunities.
A few factors are contributing to this strong interest in implementing ML in products and services. We are also beginning to see researchers share sample code written in popular open source libraries, and some even share pre-trained models. A catalog of validation data sets and the accuracy measurements of stored models.
Predictable: The scikit-learn classifiers share a similar interface, so you can invoke the same train() call on each one while passing in the same training dataset. Or that, just maybe, your training data is no good for the challenge at hand. Yes, this calls for a for() loop. It’s convenient. Damn convenient.
By 2023, organizations with shared ontology, semantics, governance and stewardship processes to enable interenterprise data sharing will outperform those that don’t. Through 2023, title inflation will drive 50% of chief data officer (CDO) appointments, leading to the CDO being an internal service, rather than a strategic business peer.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
“SAP is executing on a roadmap that brings an important semantic layer to enterprise data, and creates the critical foundation for implementing AI-based use cases,” said analyst Robert Parker, SVP of industry, software, and services research at IDC.
Was this new technology a threat to their job or a tool that would amplify their productivity? Second, if you’re selling software and services to other companies, you’re going to find that many have paused spending on new tools while they sort out exactly what their approach should be to the GenAI era.
That quote aptly describes what Dell Technologies and Intel are doing to help our enterprise customers quickly, effectively, and securely deploy generative AI and large language models (LLMs).Many Lesson 1: Don’t start from scratch to train your LLM model Massive amounts of data and computational resources are needed to train an LLM.
As Salesforce’s 2024 Dreamforce conference rolls up the carpet for another year, here’s a look at a few high points as Salesforce pitched a new era for its customers, centered around Agentforce for bringing agentic AI to enterprise sales and service operations. “We Agentforce will be generally available in October.
The technology is very new and not well understood. As the technology matures, I believe some of the more valuable applications will be those related to lineage and provenance like using the LLM to facilitate the development of the connected inventory and enhance digital twin capabilities. Most applications are still exploratory.
No, the apocalyptic visions of the groundbreaking new technology replacing us – even destroying us – aren’t keeping them up at night. Rather, they’re worried about how best to arm their employees as quickly and safely as possible with what could turn out to be the most consequential information technology of the decade.
Under the partnership, SAP is integrating Nvidia’s generative AI foundry service, including the newly announced Nvidia NIM inference microservices, into SAP Datasphere, SAP Business Technology Platform (BTP), RISE with SAP, and SAP’s enterprise applications portfolio. “We
The first tier, according to Batta, consists of its OCI Supercluster service and is targeted at enterprises, such as Cohere or Hugging Face, that are working on developing large language models to further support their customers.
Amazon OpenSearch Service is a fully managed service that makes it simple to deploy, scale, and operate OpenSearch in the AWS Cloud. An embedding model, for instance, could encode the semantics of a corpus. Semantic search is able to retrieve more relevant documents by matching the context and semantics of the query.
Semantic context – Is there any meaningfully relevant data that would help the FMs generate the response? We call this semantic context. The semantic context originates from vector data stores or machine learning (ML) search services. What do you know about user and their request?
This technology has the potential to significantly redefine the mission of the financial planning and analysis group. Rather than being the budget master, FP&A will provide planning services to those in line-of-business roles, becoming a planning center of excellence.
That’s why Rocket Mortgage has been a vigorous implementor of machine learning and AI technologies — and why CIO Brian Woodring emphasizes a “human in the loop” AI strategy that will not be pinned down to any one generative AI model. To succeed in the mortgage industry, efficiency and accuracy are paramount. The rest are on premises.
It enriched their understanding of the full spectrum of knowledge graph business applications and the technology partner ecosystem needed to turn data into a competitive advantage. For example, one of Ontotext’s clients is a global firm providing financial services in over 50 countries, which has over 5000 different IT systems.
As we apply the technology more widely across areas ranging from customer service to HR to code modernization, artificial intelligence (AI) is helping increasing numbers of us work smarter, not harder. TB after pre-processing — to produce 1 trillion tokens, the collection of characters that has semantic meaning for a model.
But by utilizing self-service BI tools, with more intuitive dashboards and UIs, companies can streamline their processes by letting managers and other non-technical staff better wield reports and, therefore, derive increased business value from the data. This enables users to see the value in adopting BI tools, according to Stout.
Beyond the simplistic chat bubble of conversational AI lies a complex blend of technologies, with natural language processing (NLP) taking center stage. DL models can improve over time through further training and exposure to more data. NLG allows conversational AI chatbots to provide relevant, engaging and natural-sounding answers.
And when Ontotext Platform’s Semantic Objects are combined with yours, we shall have an army greater than any in the galaxy. Knowledge Graph Training. Web Annotation GraphQL Service. Find Annotations with Droid tags. Character Similarity GraphQL Service. Character similarity and sub class entity resolution.
Whether it’s text, images, video or, more likely, a combination of multiple models and services, taking advantage of generative AI is a ‘when, not if’ question for organizations. As so often happens with new technologies, the question is whether to build or buy. CIOs want to take advantage of this but on their terms—and their own data.
Foundation models (FMs) are large machine learning (ML) models trained on a broad spectrum of unlabeled and generalized datasets. Large language models (LLMs) are a type of FM and are pre-trained on vast amounts of text data and typically have application uses such as text generation, intelligent chatbots, or summarization.
In Computer Science, we are trained to use the Okham razor – the simplest model of reality that can get the job done is the best one. The larger an organisation, the more complex it will naturally be, needing more people and technologies to serve a growing customer base – PwC, Is your organisation too complex to secure?
This technology enabled strategic and commercial supremacy for hundreds of years until the recipe was lost. There are a multitude of recommendations such as creating internal wikis to record policy and procedures, document templates, exit interviews, job shadowing, digitizing employee training programs, etc.
ML, a subset of AI, involves training models on existing data sets so they can make predictions or decisions without being explicitly programmed to do so. By automating the process of finding and classifying sensitive information across various platforms and services, organizations can ensure that their data is adequately protected.
As a data-driven company, InnoGames GmbH has been exploring the opportunities (but also the legal and ethical issues) that the technology brings with it for some time. KAWAII training data as YAML configuration. QueryMind training is based on information about the table structure, sample queries and documentation.
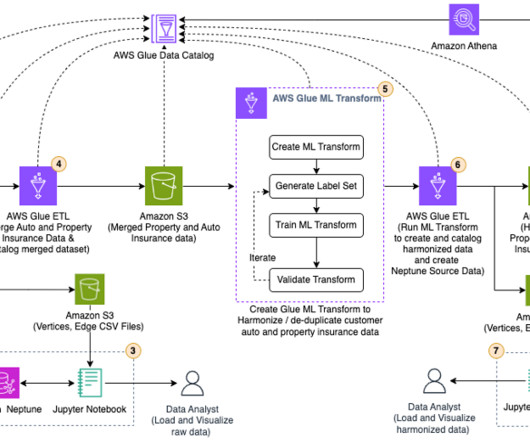
There are customer records in this data that are semantic duplicates, that is, they represent the same user entity, but have different labels or values. The data is stored in an Amazon Simple Storage Service (Amazon S3) bucket, labeled as Raw Property and Auto Insurance data in the following architecture diagram.
Today, Constellation Research , a leading technology research and advisory firm based in Silicon Valley, announced that Birst, an Infor company, for the fourth consecutive time, has been named to the Constellation ShortList for Cloud-Based Business Intelligence and Analytics Platforms. Mobile reporting, visualization, analysis.
Graph technologies are essential for managing and enriching data and content in modern enterprises. The collaboration between Semantic Web Company (SWC) and Ontotext has deepened over the years and by complementing our strengths, we deliver greater value for our customers.
Visualize all the services you use Power BI has hundreds of content packs, templates, and integrations for hundreds of data services, apps, and services — and not just Microsoft ones such as Dynamics 365 and SQL Server. Here’s how to get more insights from the information you already have, in more areas than you might expect.
Every company is looking to experiment, qualify and eventually release LLM based services to improve their internal operations and to level up their interactions with their users and customers. Best of all, the AMP was built with 100% open source technology. However, enterprises have much more specific needs. V100, A100, T4 GPUs).
My day usually involves: Azure Machine Learning Studio Azure Cosmos DB (for really large noSQL datasets) Azure Databricks (for data processing and merging) What is one topic in technology that is consuming an abnormal amount of your brain power right now? These days, generative AI with pre trained transformers. Got any paper links?
They empower organizations to deliver personalized, efficient, and secure support services while ultimately driving customer satisfaction, cost savings, data privacy compliance, and revenue growth. With 1,536 dimensions, the embeddings model captures semantic nuances in meaning and relationships. Kenneth Walsh is a New York-based Sr.
They are expected to understand the entire data landscape and generate business-moving insights while facing the voracious needs of different teams and the constraints of technology architecture and compliance. It also enables leaders to make decisions not based on the limitations of their technology, but on what data can do.
Practical applications of linear regression: Predicting sales of a product based on pricing, performance, risk, market performance, and other parameters Real-time server load prediction for cloud computing services Market research studies and customer survey analysis Determining the ROI of a new policy, initiative, or campaign.
Gartner predicts that graph technologies will be used in 80% of data and analytics innovations by 2025, up from 10% in 2021. Graphs boost knowledge discovery and efficient data-driven analytics to understand a company’s relationship with customers and personalize marketing, products, and services. We get this question regularly.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content