This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Disaster recovery is vital for organizations, offering a proactive strategy to mitigate the impact of unforeseen events like system failures, natural disasters, or cyberattacks. In Disaster Recovery (DR) Architecture on AWS, Part I: Strategies for Recovery in the Cloud , we introduced four major strategies for disaster recovery (DR) on AWS.
Snapshots are crucial for data backup and disaster recovery in Amazon OpenSearch Service. These snapshots allow you to generate backups of your domain indexes and cluster state at specific moments and save them in a reliable storage location such as Amazon Simple Storage Service (Amazon S3). Snapshots are not instantaneous.
In this post, we will introduce a new mechanism called Reindexing-from-Snapshot (RFS), and explain how it can address your concerns and simplify migrating to OpenSearch. Documents are parsed from the snapshot and then reindexed to the target cluster, so that performance impact to the source clusters is minimized during migration.
Metadata layer Contains metadata files that track table history, schema evolution, and snapshot information. In many operations (like OVERWRITE, MERGE, and DELETE), the query engine needs to know which files or rows are relevant, so it reads the current table snapshot. This is optional for operations like INSERT.
In our previous post Backtesting index rebalancing arbitrage with Amazon EMR and Apache Iceberg , we showed how to use Apache Iceberg in the context of strategy backtesting. Iceberg provides time travel and snapshotting capabilities out of the box to manage lookahead bias that could be embedded in the data (such as delayed data delivery).
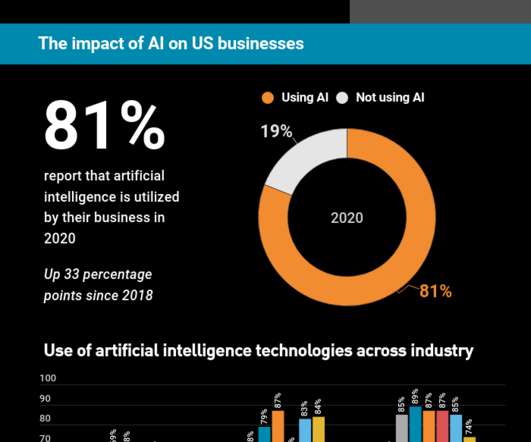
While there has been accelerating interest in implementing AI as a technology, there has been concurrent growth in interest in implementing successful AI strategies. But it was not just a snapshot on the state of AI in 2020. In the recent 2020 RELX Emerging Tech Study , results were presented from a survey of over 1000 U.S.
As organizations grapple with exponential data growth and increasingly complex analytical requirements, these formats are transitioning from optional enhancements to essential components of competitive data strategies. Branching Branches are independent lineage of snapshot history that point to the head of each lineage.
in Amazon OpenSearch Service , we introduced Snapshot Management , which automates the process of taking snapshots of your domain. Snapshot Management helps you create point-in-time backups of your domain using OpenSearch Dashboards, including both data and configuration settings (for visualizations and dashboards).
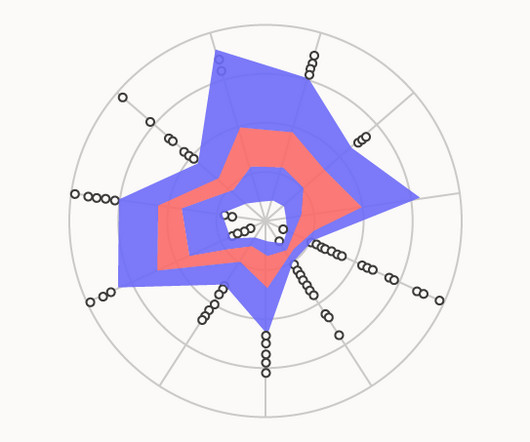
Analysing a Radar Box Plot can allow for predicting any classification confusion that may arise among classes and help in identifying strategies for improvement. This visualisation is most effective when dealing with tasks involving more than four relevant variables, as it can represent higher-dimensional data in a way that is still legible.
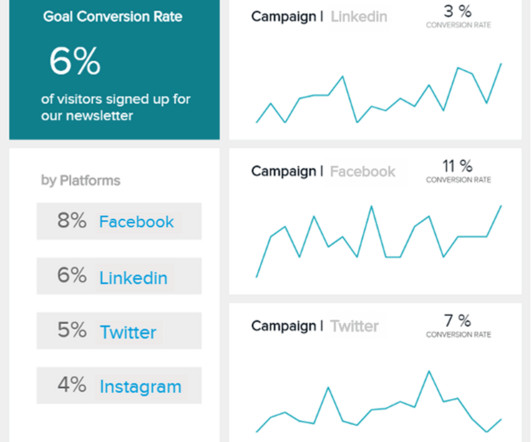
By tracking and analyzing the right social media metrics, alongside marketing KPIs for your overall promotional strategy, you will be able to answer these questions with confidence, thereby enjoying long term success in a competitive digital environment. c) Bonus Metrics For A Complete SM Strategy. Social Media KPIs You Should Track.
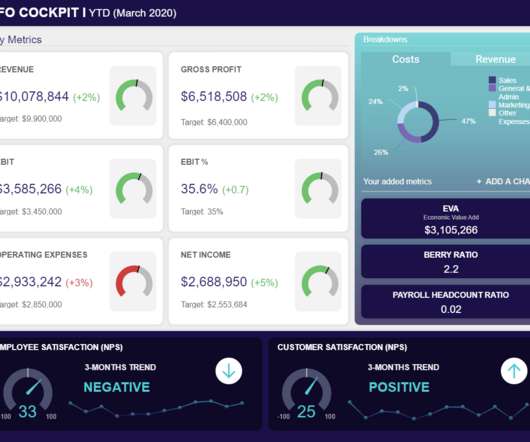
Not only are you responsible for the ongoing financial strategy of your organization, but you’re probably expected to provide timely, accurate reports to a variety of stakeholders. Visual, dynamic KPIs that will help you form long-term strategies and make decisions at a glance. Let’s see this through an example.
VMware Live Recovery support for Google Cloud empowers customers with more choices for their cyber and disaster recovery strategies, said Manoj Sharma, Director of Product Management, Google Cloud. Product Line Marketing Manager for VMwares Data Protection as a Service portfolio, in charge of VMware Cloud Disaster Recovery.
Moreover, most enterprise cloud strategies involve a variety of cloud vendors, including point-solution SaaS vendors operating in the cloud. it’s critical to remember that it is only a snapshot at that moment of evaluation. Interrelations between these various partners further complicate the risk equation.
And the right approach to adopting cloud computing and preventing these threads is in building cyber security and cyber resilience strategies which we discuss later and making them work together. Systematic pentesting might help identify some gaps in your cyber resilience program but ultimately, it’s just a snapshot of what is happening.
A CRM dashboard is a centralized hub of information that presents customer relationship management data in a way that is dynamic, interactive, and offers access to a wealth of insights that can improve your consumer-facing strategies and communications. Your Chance: Want to build professional CRM reports & dashboards?
Download our free executive summary and boost your sales strategy! Download our free executive summary and boost your sales strategy! Number 6 on our list is a sales graph example that offers a detailed snapshot of sales conversion rates. Download our free executive summary and boost your sales strategy! 5) Sales Cycle.
How can BAs ensure requirements are practical and in line with the strategy/capabilities of the business? Study after study shows that when CEOs discuss strategy, most employees don’t get it. Requirements should therefore be in alignment with the business architecture and strategy of the organization.
Without data, you will only ever be ‘shooting in the dark’ when it comes to formulating strategies and making informed decisions. Key performance provides a panoramic snapshot of your business’s essential activities. Benchmarking: One of the most powerful functions of committing to track KPI metrics is gaining the ability to benchmark.
Market research analyses are the go-to solution for many professionals, and with reason: they save time, they provide new insights and clarification on the business market you are working on and help you to refine and polish your strategy. Such dashboards are extremely convenient to share the most important information in a snapshot.
It can be expanded with each new VM spun up, providing a highly scalable strategy that guarantees the security of the enterprise’s data. Counting the Benefits of Encrypting VMs for HCI Encrypting VMs for HCI provides various advantages to the IT department and the larger company.
Organizations were evaluated based on their current use of data and analytics, parties championing the use of data and the extent to which data is used across processes, the presence of enterprise data strategies, and the extent to which capabilities relating to an Enterprise Data Cloud have been achieved. .
History and versioning : Iceberg’s versioning feature captures every change in table metadata as immutable snapshots, facilitating data integrity, historical views, and rollbacks. Snapshot management allows concurrent data operations without interference, maintaining data consistency across transactions.
How redefining the replication strategy boosts the indexing throughput OpenSearch supports two replication strategies: logical (document) and physical (segment) replication. So how do snapshots work when we already have the data present on Amazon S3? So how do snapshots work when we already have the data present on Amazon S3?
This blog discusses a few problems that you might encounter with Iceberg tables and offers strategies on how to optimize them in each of those scenarios. You can take advantage of a combination of the strategies provided and adapt them to your particular use cases. You could also change the isolation level to snapshot isolation.
These improvements are geared toward managing the most intense AI workloads with ease so that enterprises can execute their AI strategies without performance bottlenecks. NetApp is committed to delivering industry-leading performance through its upcoming enhancements to the NetApp AFF series systems and the ONTAP software.
Whether you manage a big or small company, business reports must be incorporated to establish goals, track operations, and strategy, to get an in-depth view of the overall company state. This clear overview of data can set apart the success of your management strategy, since it is not possible to omit vital information.
Lake Formation tag-based access control (LF-TBAC) is an authorization strategy that defines permissions based on attributes. Iceberg creates snapshots for the table contents. Each snapshot is a complete set of data files in the table at a point in time. In Lake Formation, these attributes are called LF-Tags.
A modern data strategy redefines and enables sharing data across the enterprise and allows for both reading and writing of a singular instance of the data using an open table format. The open table format accelerates companies’ adoption of a modern data strategy because it allows them to use various tools on top of a single copy of the data.
With built-in features such as automated snapshots and cross-Region replication, you can enhance your disaster resilience with Amazon Redshift. Identify recovery strategies to meet the recovery objectives. In the following sections, we discuss the various failure modes and associated recovery strategies.
This is just one business intelligence report sample that can be developed in more detail by establishing the right KPIs and developing a business strategy and goals. There are countless KPI examples to select and adopt in a strategy, but only the right tracking and analysis can bring profitable results. click to enlarge**.
Backtesting is a process used in quantitative finance to evaluate trading strategies using historical data. This helps traders determine the potential profitability of a strategy and identify any risks associated with it, enabling them to optimize it for better performance.
Engagement: By obtaining access to a panoramic snapshot of your business’s entire customer service and support processes, you’ll be able to make vital improvements to your service levels, consumer touchpoints, content, and communications. Support tickets by channel.
On the secondary storage front, you need to figure out what to do from a replication/snapshot perspective for disaster recovery and business continuity. Data needs to be air-gapped, including logical air gapping and immutable snapshot technologies. It all starts with making storage a part of your corporate cybersecurity strategy. .
This isn’t just valuable for the customer – it allows logistics companies to see patterns at play that can be used to optimize their delivery strategies. Influential brands including Apple, Nokia, and Johnson & Johnson are placing a strong focus on data-driven solutions to improve their customer experience strategy.
These formats enable ACID (atomicity, consistency, isolation, durability) transactions, upserts, and deletes, and advanced features such as time travel and snapshots that were previously only available in data warehouses. It will never remove files that are still required by a non-expired snapshot.
We will continue with tips on how to do a procurement analysis, and wrap up with real-life examples that you can implement into your own business strategies. You also need to harmonize all your transactions to be able to increase visibility on all your spending processes and ensure that your procurement strategies will increase productivity.
It provides a brief snapshot of the entire business. I humbly believe the challenge is that in a world of too much data, with lots more on the way, there is a deep desire amongst executives to get "summarize data," to get "just a snapshot," or to get the "top-line view." digital performance. Standstill.
Dashboards are used within the business intelligence (BI) environment, creating a link between managers and the company’s strategy, allowing departments to collaborate more effectively, and enabling employees to perform with an increased productivity level. Each dashboard created should be a live snapshot of your business.
Today’s data security strategies need new solutions, but unfortunately, many existing tools can only manage one piece of that much bigger and more complex puzzle. Highlight gaps in your current strategy. Efficiently identifying the most recent clean snapshot (the point just before the malware intrusion and data compromise).
Storytelling through data is the process of transforming data-driven analyses into a widely-accessible visual format to influence a business decision, strategy, or action by utilizing analytical information that, ultimately, turn into actionable insights. What Is Data Storytelling? Compliance Rate KPI.
Usually, these reports are considered to be financial statements which include: a balance sheet: is a snapshot of a business at a specific time and shows the ending assets, liability, and equity balances as of the balance sheet date. The balance sheet is a snapshot of your business finances at a moment in time, showing assets and liabilities.
Helping you understand your position: a management-style report provides you with the right metrics to get a snapshot of your business’ health and evolution. You can compare it to your competitors to focus or realign your strategy. How much money you make, on average, for every new email subscriber and calculate the expected ROI.
Armed with powerful visualizations and real-time data, modern weekly summary reports enable businesses to closely monitor their performance and the progress of their strategies to extract relevant insights and optimize their processes to ensure constant growth. This way you can prepare your resources and strategies accordingly.
We’ve already discussed how checkpoints, when triggered by the job manager, signal all source operators to snapshot their state, which is then broadcasted as a special record called a checkpoint barrier. When barriers from all upstream partitions have arrived, the sub-task takes a snapshot of its state.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content