This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we focus on data management implementation options such as accessing data directly in Amazon Simple Storage Service (Amazon S3), using popular data formats like Parquet, or using open table formats like Iceberg. Data management is the foundation of quantitative research.
According to Richard Kulkarni, Country Manager for Quest, a lack of clarity concerning governance and policy around AI means that employees and teams are finding workarounds to access the technology. Some senior technology leaders fear a Pandoras Box type situation with AI becoming impossible to control once unleashed.
Amazon Redshift is a fully managed, AI-powered cloud data warehouse that delivers the best price-performance for your analytics workloads at any scale. It enables you to get insights faster without extensive knowledge of your organization’s complex database schema and metadata. Within this feature, user data is secure and private.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machine learning services to streamline the user journey from data to insight. This led to inefficiencies in data governance and access control.
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. Both Delta Lake and Iceberg metadata files reference the same data files.
Zero-ETL is a set of fully managed integrations by AWS that minimizes the need to build ETL data pipelines. We take care of the ETL for you by automating the creation and management of data replication. Zero-ETL provides service-managed replication. Glue ETL offers customer-managed data ingestion. What is zero-ETL?
Kinesis Data Streams is a fully managed, serverless data streaming service that stores and ingests various streaming data in real time at any scale. Solution overview In this solution, we consider a common use case for centralized log aggregation for an organization. To create a Kinesis Data Stream, see Create a data stream.
Solution overview To illustrate the new Amazon Bedrock Knowledge Bases integration with structured data in Amazon Redshift, we will build a conversational AI-powered assistant for financial assistance that is designed to help answer financial inquiries, like Who has the most accounts? Create an AWS Identity and Access Management (IAM) role.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics.
With this launch of JDBC connectivity, Amazon DataZone expands its support for data users, including analysts and scientists, allowing them to work in their preferred environments—whether it’s SQL Workbench, Domino, or Amazon-native solutions—while ensuring secure, governed access within Amazon DataZone.
When building custom stream processing applications, developers typically face challenges with managing distributed computing at scale that is required to process high throughput data in real time. reduces the Amazon DynamoDB cost associated with KCL by optimizing read operations on the DynamoDB table storing metadata.
As data-centric AI, automated metadatamanagement and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant. Instead, organizations resort to manual workarounds often managed by overburdened analysts or domain experts. Assign domain data stewards.
Amazon DataZone , a data management service, helps you catalog, discover, share, and govern data stored across AWS, on-premises systems, and third-party sources. This solution enhances governance and simplifies access to unstructured data assets across the organization. The solution architecture is shown in the following screenshot.
As organizations increasingly adopt cloud-based solutions and centralized identity management, the need for seamless and secure access to data warehouses like Amazon Redshift becomes crucial. federated users to access the AWS Management Console. From there, the user can access the Redshift Query Editor V2.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a fully managed service that builds upon Apache Airflow, offering its benefits while eliminating the need for you to set up, operate, and maintain the underlying infrastructure, reducing operational overhead while increasing security and resilience.
This is a good time to assess enterprise activities, as there are many indications a number of companies are already beginning to use machine learning. and managed services in the cloud. Not surprisingly, data integration and ETL were among the top responses, with 60% currently building or evaluating solutions in this area.
Supply chain management (SCM) is a critical focus for companies that sell products, services, hardware, and software. The updated version includes more emerging drivers of supply chain success, covering topics such as omnichannel, metadata, and blockchain , according to the ASCM. What is the main focus of the SCOR model?
If you’re already a software product manager (PM), you have a head start on becoming a PM for artificial intelligence (AI) or machine learning (ML). But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools.
A recent flourish of posts and papers has outlined the broader topic, listed attack vectors and vulnerabilities, started to propose defensive solutions, and provided the necessary framework for this post. Like many others, I’ve known for some time that machine learning models themselves could pose security risks. Data poisoning attacks.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a fully managed orchestration service that makes it straightforward to run data processing workflows at scale. In this post, we dive deep into the implementation for both strategies and provide a deployable solution to realize the architectures in your own AWS account.
It encompasses the people, processes, and technologies required to manage and protect data assets. The Data Management Association (DAMA) International defines it as the “planning, oversight, and control over management of data and the use of data and data-related sources.”
What Is Metadata? Metadata is information about data. A clothing catalog or dictionary are both examples of metadata repositories. Indeed, a popular online catalog, like Amazon, offers rich metadata around products to guide shoppers: ratings, reviews, and product details are all examples of metadata.
First, what activemetadatamanagement isn’t : “Okay, you metadata! Now, what activemetadatamanagement is (well, kind of): “Okay, you metadata! Metadata are the details on those tools: what they are, what to use them for, what to use them with. . That takes activemetadatamanagement.
Why it’s challenging to process and manage unstructured data Unstructured data makes up a large proportion of the data in the enterprise that can’t be stored in a traditional relational database management systems (RDBMS). You can integrate different technologies or tools to build a solution.
Organizations with legacy, on-premises, near-real-time analytics solutions typically rely on self-managed relational databases as their data store for analytics workloads. We introduce you to Amazon Managed Service for Apache Flink Studio and get started querying streaming data interactively using Amazon Kinesis Data Streams.
1) What Is Data Quality Management? 10) Data Quality Solutions: Key Attributes. However, with all good things comes many challenges and businesses often struggle with managing their information in the correct way. Enters data quality management. What Is Data Quality Management (DQM)? Table of Contents.
Organizations need to understand what the most critical operational activities are and the most impactful projects that need to proceed. Where crisis leads to vulnerability, data governance as an emergency service enables organization management to direct or redirect efforts to ensure activities continue and risks are mitigated.
Customer relationship management (CRM) platforms are very reliant on big data. In software development, technical debt is often defined as the cost of choosing an easy solution now instead of a better approach that might take longer. Complex Salesforce orgs can work just fine if they are properly managed.
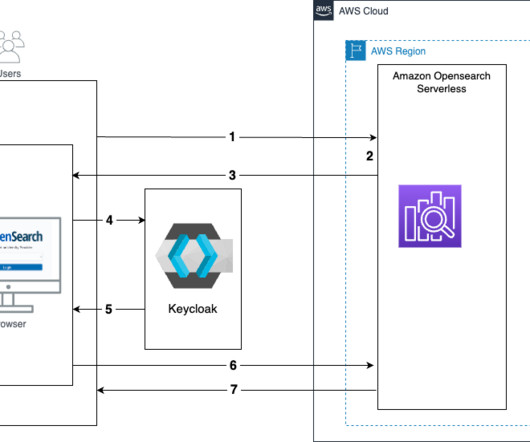
Amazon OpenSearch Serverless is a serverless version of Amazon OpenSearch Service , a fully managed open search and analytics platform. This improves the user experience and reduces the overhead of managing multiple credentials. aoss:UpdateSecurityConfig – Modify a given SAML provider configuration, including the XML metadata.
They understand that a one-size-fits-all approach no longer works, and recognize the value in adopting scalable, flexible tools and open data formats to support interoperability in a modern data architecture to accelerate the delivery of new solutions. Implementing these solutions requires data sharing between purpose-built data stores.
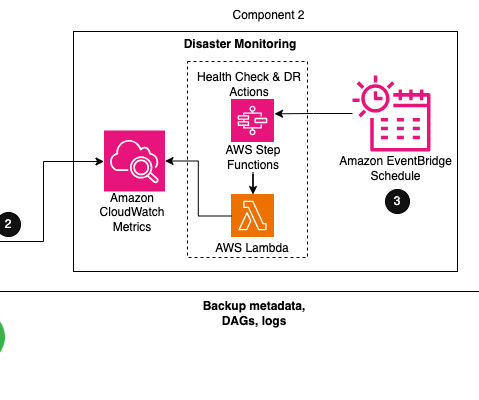
For organizations implementing critical workload orchestration using Amazon Managed Workflows for Apache Airflow (Amazon MWAA), it is crucial to have a DR plan in place to ensure business continuity. Within Airflow, the metadata database is a core component storing configuration variables, roles, permissions, and DAG run histories.
Metadata is the pertinent, practical details about data assets: what they are, what to use them for, what to use them with. Without metadata, data is just a heap of numbers and letters collecting dust. Where does metadata come from? What is a metadatamanagement tool? Metadata harvesting.
Oracle has announced the launch of Oracle Fusion Cloud Sustainability — an app that integrates data from Oracle Fusion Cloud ERP and Oracle Fusion Cloud SCM , enabling analysis and reporting within Oracle Fusion Cloud Enterprise Performance Management (EPM) and Oracle Fusion Data Intelligence.
As organizations deal with managing ever more data, the need to automate data management becomes clear. One piece of the research that stuck with me is that 70% of respondents spend 10 or more hours per week on data-related activities. That’s a lot of data to manage! It’s time to automate data management.
Last but not least, we looked at the amount of time spent on data activities. The great news is that most organizations spend more than 10 hours a week on data-related activities. Automating data operations adds a lot of value by making a solution more effective and more powerful. Data Automation Adds Value.
Every enterprise needs a data strategy that clearly defines the technologies, processes, people, and rules needed to safely and securely manage its information assets and practices. Data is no longer just used by analysts and data scientists,” says Dinesh Nirmal, general manager of AI and automation at IBM Data.
What few of these groups know how to reckon with, though, is how to best manage data that’s no longer in use – particularly data from systems the organization has since retired. When data is no longer in active use, the best thing that healthcare systems can do it archive it. What’s the best way to handle this information?
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud data warehouse. We use AWS Glue , a fully managed, serverless, ETL (extract, transform, and load) service, and the Google BigQuery Connector for AWS Glue (for more information, refer to Migrating data from Google BigQuery to Amazon S3 using AWS Glue custom connectors ).
Designing for high throughput with 11 9s of durability OpenSearch Service manages tens of thousands of OpenSearch clusters. The following diagram illustrates the recovery flow in OR1 instances OR1 instances persist not only the data, but the cluster metadata like index mappings, templates, and settings in Amazon S3.
Customers prefer to let the service manage its capacity automatically rather than having to manually provision capacity. Until now, customers have had to rely on using custom code or third-party solutions to move the data between provisioned OpenSearch Service domains and OpenSearch Serverless.
There are challenges such as complexity in managing cross-account permissions and difficulty in discovering the right data across accounts that organizations face when trying to share data products across AWS accounts. A straightforward data access and sharing mechanism is crucial for enabling effective data sharing across an organization.
By 2024 , 60% of the data used for the development of AI and analytics solutions will be synthetically generated. Predicts 2021: Artificial Intelligence in Enterprise Applications : By 2024, the degree of manual effort required for the contract review process will be halved in enterprises that adopt advanced contract analytics solutions.
To address these growing data management challenges, AWS customers are using Amazon DataZone , a data management service that makes it fast and effortless to catalog, discover, share, and govern data stored across AWS, on-premises, and third-party sources. The overall structure can be represented in the following figure.
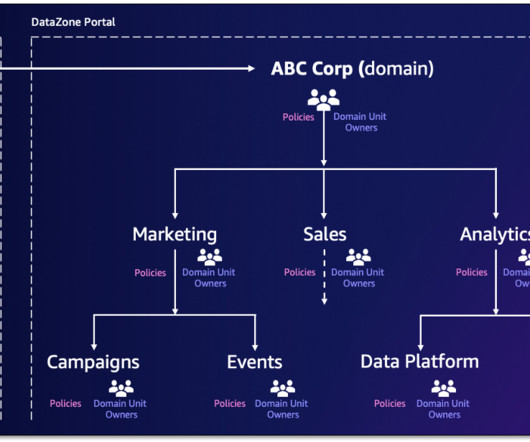
Amazon DataZone has announced a set of new data governance capabilities—domain units and authorization policies—that enable you to create business unit-level or team-level organization and manage policies according to your business needs. Some examples of child domain units include drug discovery and clinical trials management.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content