This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Do you buy a solution from a big integration company like IBM, Cloudera, or Amazon? Integrated all-in-one platforms assemble many tools together, and can therefore provide a full solution to common workflows. However some assembly is required because they need to be used alongside other products to create full solutions.
Delta Lake UniForm can be a solution to meet this requirement. After creating the Studio Workspace is complete, you are redirected to Jupyter Notebook. Upload Jupyter Notebook Complete the following steps to configure a Jupyter Notebook to use Delta Lake UniForm with Amazon EMR. Download delta-lake-uniform-on-aws.ipynb.
Solution overview This post demonstrates text-to-SQL generation for Athena using an example implemented using Amazon Bedrock. The solution architecture and workflow. The relevant CloudFormation template, Jupyter Notebooks, and details of launching the necessary AWS services are covered in this section.
There is a decades-long tradition of data-centric programming : developers who have been using data-centric IDEs, such as RStudio, Matlab, Jupyter Notebooks, or even Excel to model complex real-world phenomena, should find this paradigm familiar. To plug this gap, frameworks like Metaflow or MLFlow provide a custom solution for versioning.
Solution overview In this solution, we show how to query a dataset stored in Amazon S3 Tables for further analysis using data managed in Amazon Redshift. Also enter your IP or VPN range for Jupyter Notebook access in the SourceCidrForNotebook parameter in CloudFormation. Replace the routes with your organizations IP addresses.
aws redshift-data execute-statement --sql "select count(*) from dev.stage_stores" --session-id 5a254dc6-4fc2-4203-87a8-551155432ee4 --session-keep-alive-seconds 10 Solution walkthrough You will use AWS Step Functions to call the Data API because this is one of the more straightforward ways to create a codeless ETL.
In recent years, driven by the commoditization of data storage and processing solutions, the industry has seen a growing number of systematic investment management firms switch to alternative data sources to drive their investment decisions. The bulk of our data scientists are heavy users of Jupyter Notebook.
Data quality solutions almost always boil down to two big issues: politics and cost. Another one-fifth use a notebook environment (such as Jupyter ). The problem (and partial solution) is that they need quality data to power their AI projects. The remaining 50% (i.e., This includes deciding what is not worth addressing.
The sheer volume of data captured daily continues to grow, calling for platforms and solutions to evolve. Services such as Amazon Simple Storage Service (Amazon S3) offer a scalable solution that adapts yet remains cost-effective for growing datasets. This solution was inspired by work with a key AWS customer, the UK Met Office.
Jupyter Notebooks. Jupyter Notebooks let readers do more than absorb. Jupyter Notebooks let readers do more than absorb. Today, the standard Jupyter Notebook supports more than 40 programming languages, and it’s common to find R, Julia, or even Java or C within them. Jupyter Notebooks don’t just run themselves.
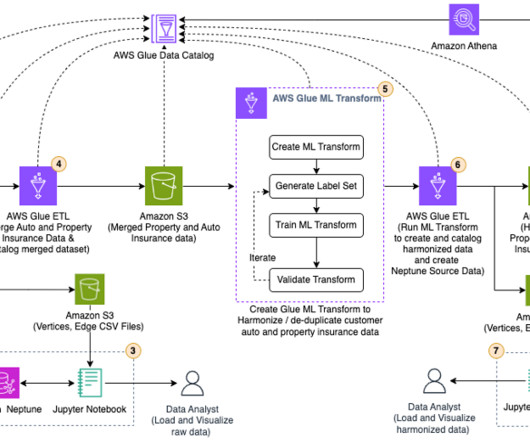
Overview of solution In this post, we go through the various steps to apply ML-based fuzzy matching to harmonize customer data across two different datasets for auto and property insurance. The following diagram shows our solution architecture. Prerequisites To follow along with this walkthrough, you must have an AWS account.
AWS Glue interactive sessions offer a powerful way to iteratively explore datasets and fine-tune transformations using Jupyter-compatible notebooks. Solution overview You can quickly provision new interactive sessions directly from your notebook without needing to interact with the AWS Command Line Interface (AWS CLI) or the console.
In recognition of the diverse workload that data scientists face, Cloudera’s library of Applied ML Prototypes (AMPs) provide Data Scientists with pre-built reference examples and end-to-end solutions, using some of the most cutting edge ML methods, for a variety of common data science projects. AutoML with TPOT.
This technology is enabled by the use of notebook IDEs, such as the AWS Glue Studio notebook, Amazon SageMaker Studio , or your own Jupyter notebooks. Users can run AWS Glue interactive sessions by using both AWS Glue Studio notebooks via the AWS Glue console, as well as Jupyter notebooks that run on their local machine.
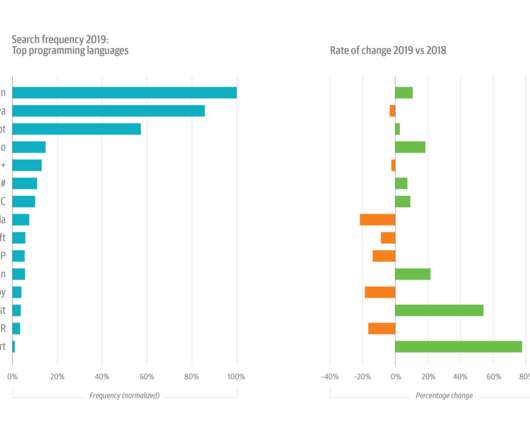
Kubernetes has emerged as the de facto solution for orchestrating services and microservices in cloud native design patterns. relational database,” “Oracle database solutions,” “Hive,” “database administration,” “data models,” “Spark”—declined in usage, year-over-year, in 2019.
Amazon EMR , with its open-source Hadoop modules and support for Apache Spark and Jupyter and JupyterLab notebooks, is a good choice to solve this multi-cloud data access problem. Overview of solution Amazon EMR inherently includes Apache Hadoop at its core and integrates other related open-source modules.
Composite AI mixes statistics and machine learning; industry-specific solutions. SageMaker is a full-service platform with data preparation tools such as the Data Wrangler, a nice presentation layer built out of Jupyter notebooks, and an automated option called Autopilot. On premises or in SAP cloud. Per user, per month. Free tier.
This blog post provides a step-by-step guide for building a multimodal search solution using OpenSearch Service. Multimodal search solution architecture We will provide the steps required to set up multimodal search using OpenSearch Service. The following image depicts the solution architecture. OpenSearch version is 2.13
Open table formats, such as Apache Iceberg , provide a solution to this issue. In this post, we show you how you can convert existing data in an Amazon S3 data lake in Apache Parquet format to Apache Iceberg format to support transactions on the data using Jupyter Notebook based interactive sessions over AWS Glue 4.0. Choose ETL Jobs.
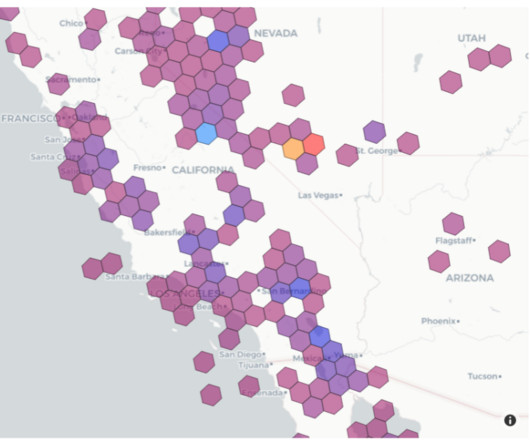
In this post, we present a solution that uses Uber’s Hexagonal Hierarchical Spatial Index (H3) to divide the globe into equally-sized hexagons. Solution overview The solution extends Athena’s built-in geospatial capabilities by creating a UDF powered by AWS Lambda. Open the notebook instance by choosing Jupyter or JupyterLab.
Solution overview In this post, we demonstrate how to implement FGAC on Apache Hudi tables using Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2) integrated with Lake Formation. The following diagram illustrates the solution architecture. For example, the users only can access data rows that belong to their country.
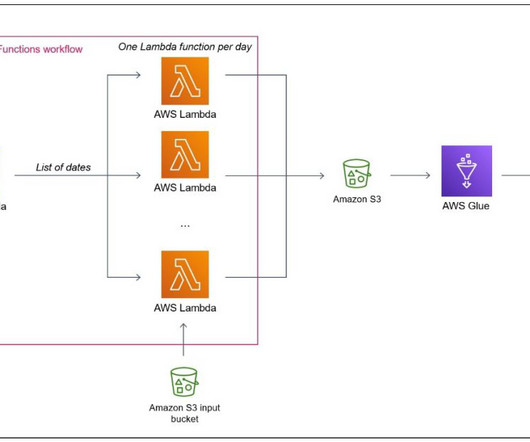
Solution overview To achieve our goal, we use parallel Lambda functions. Deployment of this solution: In this post, we provide step-by-step instructions to deploy each part of the architecture manually. The following screenshot illustrates running the preceding code in a Jupyter notebook.
BI developers, with an average salary of $83,091, work with databases and software to develop and fine-tune IT solutions. The cert demonstrates that you are up-to-date with BI technologies and are knowledgeable about best practices, solutions, and emerging trends.
It’s that practice of engineering at Netflix which I find so interesting – really since Ariel Tseitlin led Cloud Solutions there. For example, while enjoying dinner the evening before Rev, a close friend questioned the use of Jupyter beyond exploratory data science. Jupyter fits brilliantly for that purpose. — Randi R.
Domino provides data scientists with the ability to run code either in workspace environments that provide IDEs such as Jupyter, R Studio or VS Code or conversely to create a job that runs a particular piece of code. About Snowflake. About Domino Data Lab. Domino Data Lab is the system-of-record for enterprise data science teams.
In our previous blog posts of the series, we talked about how to ingest data from different sources into GraphDB , validate it and infer new knowledge from the extant facts as well as how to adapt and scale our basic solution. With Ontotext’s products , LAZY is firmly on the way towards finding a solution.
While that may involve one-off projects, more typically data science teams seek to identify key data assets that can be turned into data pipelines that feed maintainable tools and solutions. Examples include credit card fraud monitoring solutions used by banks, or tools used to optimize the placement of wind turbines in wind farms.
Today, Blackstone’s data analytics stack includes Fivetran, Snowflake, Sigma, Jupyter Notebooks, Alation, and various other tools. Pologruto solved this problem by giving people the option to analyze data in the tool of their choice: Jupyter Notebooks for data scientists and more technical teams, and Sigma for business teams.
Founded in 2016 by the creator of Apache Zeppelin, Zepl provides a self-service data science notebook solution for advanced data scientists to do exploratory, code-centric work in Python, R, and Scala. It supports both Zeppelin and Jupyter notebooks — new or imported. The Perfect Complement. DataRobot + Zepl. Sign Up Now.
A Jupyter notebook to run using Amazon EMR Studio using Amazon EMR on an EC2 cluster A PySpark script to run using Amazon EMR Studio and Amazon EMR Serverless After the stack creation is complete, choose the stack name redshift-spark and navigate to the Outputs We utilize these output values later in this post.
This example provides a solution for enterprises looking to enhance their AI capabilities. Solution overview The following diagram illustrates the solution architecture. In an actual solution, you would encapsulate the code in classes and pass the values where needed. Use these scripts as examples to pull from.
Solution overview In the following sections, we first introduce the Common Crawl dataset and how to explore and filter the data we need. SageMaker JumpStart provides a set of solutions for the most common use cases that can be deployed with just a few clicks. The following diagram illustrates the architecture of this solution.
Then the data is consumed by SaaS-based computational tools, but it still sits within our organization and sits within the controls of our cloud-based solutions.” From a language perspective, scientists use Python and Jupyter Notebooks. Much of Regeneron’s data, of course, is confidential.
Solution overview Our solution demonstrates how financial analysts can use generative artificial intelligence (AI) to adapt their investment recommendations based on financial reports and earnings transcripts with RAG to use LLMs to generate factual content. This makes RAG adaptive for situations where facts could evolve over time.
You can use Eclipse technology, Jupyter and Zeppelin. In the Data Science world, Jupyter is very common. Apache Spark is an open source software solution until allows you to work on data that’s held in memory. We can also use it with Jupyter Notebooks as well. So, let’s take a look!
Your “simple” pipeline involves a toolchain that features Fivetran, DBT, SQL, a Jupyter notebook, and Tableau. While quite valuable, these solutions all produce lagging indicators. For more information about DataKitchen's Observability solution, contact us!
If we can crack the nut of enabling a wider workforce to build AI solutions, we can start to realize the promise of data science. In the future it will be as easy to train on hundreds of GPUs as it is to train on a Jupyter notebook in a managed workspace. An important part of these foundational layers is Keras Tuner and AutoKeras.
By observing and analyzing data, we can develop more accurate theories and formulate more effective solutions. Because sending Jupyter Notebook or Python scripts to non-technical people will undoubtedly cause some problems, which prevents them from being widely promoted in the traditional business of large enterprises.
This post proposes a solution to this challenge by introducing the Batch Processing Gateway (BPG) , a centralized gateway that automates job management and routing in multi-cluster environments. Solution overview Martin Fowler describes a gateway as an object that encapsulates access to an external system or resource.
Solution overview The solution is designed to help you track the cost of your Spark applications running on EMR on EC2. The proposed solution uses a scheduled AWS Lambda function that operates on a daily basis. The utilization of these AWS services incurs additional costs for implementing this solution.
We do not and cannot have a “one size fits all” solution for data science training. NASA persistently misspells Jupyter. In terms of teaching and learning data science, Project Jupyter is probably the biggest news over the past decade – even though Jupyter’s origins go back to 2001! Translated: MOOCs are no panacea.
Through this series of blog posts, we’ll discuss how to best scale and branch out an analytics solution using a knowledge graph technology stack. Our main weapons when beating that beast will be GraphDB , Ontotext Platform , Kafka , Elasticsearch , Kibana and Jupyter.
Often it is easy to collect data manually, that is, downloading from a web site and cleaning it up manually in Excel, Jupyter Notebook, or RStudio. Install a few packages that we will use for this chapter: i.e., Pandas, Jupyter. To inspect the data, start a Jupyter Notebook using the command: jupyter notebook.
” No-code and low-code solutions for time series data exploration IBM introduced Downer to the realm where no-code and low-code solutions could build predictive models to provide faster insights. Speed and scalability : Downer efficiently adapted models to diverse data signals using tools like the Jupyter Notebook.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content