This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Solution overview In this scenario, an e-commerce company sells products on their online platform. The product data is stored on Amazon Aurora PostgreSQL-Compatible Edition. An Aurora PostgreSQL database cluster. Select PostgreSQL , and choose Next. Now you have a unified connection for Aurora PostgreSQL-Compatible.
This particular code, or language, was developed in the 1970s , and since then, it has become the standard for communicating with various relational database management systems (RDMS), including the likes of Oracle, Microsoft SQL Server, Sybase, PostgreSQL, Informix, and MySQL. 4) “SQL Performance Explained” by Markus Winand.
Amazon Redshift scales linearly with the number of users and volume of data, making it an ideal solution for both growing businesses and enterprises. These improvements collectively reinforce Amazon Redshifts focus as a leading cloud data warehouse solution, offering unparalleled performance and value to customers.
He is devoted to designing and building end-to-end solutions to address customers data analytic and processing needs with cloud-based, data-intensive technologies. Stuti Deshpande is a Big Data Specialist Solutions Architect at AWS. She has extensive experience in big data, ETL, and analytics.
Customers are migrating their on-premises data warehouse solutions built on databases like Netezza, PostgreSQL, Greenplum, and Teradata to AWS based modern data platforms using services like Amazon Simple Storage Service (Amazon S3) and Amazon Redshift. Use AWS Glue ETL to curate data from the S3 staging bucket to an S3 curated bucket.
Solution overview To create a zero-ETL integration, you specify an Amazon Aurora PostgreSQL-Compatible Edition cluster (compatible with PostgreSQL 15.4 Solution overview To create a zero-ETL integration, you specify an Amazon Aurora PostgreSQL-Compatible Edition cluster (compatible with PostgreSQL 15.4
This offering is designed to provide an even more cost-effective solution for running Airflow environments in the cloud. Another important change is that the meta database will now use a t4g.medium Amazon Aurora PostgreSQL-Compatible Edition instance powered by AWS Graviton2. By providing a lightweight yet feature-rich solution, mw1.micro
In this post, I’ll walk you through how to copy data from one Amazon Relational Database Service (Amazon RDS) for PostgreSQL database to another, while scrubbing PII along the way using AWS Glue. This solution employs multiple AWS accounts. See JDBC connections for further details.
Customers need a cloud-native automated solution to archive historical data from their databases. This post proposes an automated solution by using AWS Glue for automating the PostgreSQL data archiving and restoration process, thereby streamlining the entire procedure. The following diagram illustrates the solution architecture.
Amazon Redshift zero-ETL integrations can load data from Amazon Aurora MySQL-Compatible Edition , Amazon Relational Database Service (Amazon RDS) for MySQL , Amazon RDS for PostgreSQL , and DynamoDB, with the added ability to perform transformations after loading. Associate the IAM role with your Amazon Redshift cluster.
A solution to this problem is to use AWS Database Migration Service (AWS DMS) for migrating historical and real-time transactional data into the data lake. Solution overview The following diagram shows the overall architecture of the solution that we implement in this post.
In addition to AKS and the load balancers mentioned above, this includes VNET, Data Lake Storage, PostgreSQL Azure database, and more. By default Azure Data Lake Storage, PostgreSQL Database, and Virtual Machines are accessible over public endpoints. Do enable the Create Private Endpoints option for the PostgreSQL Azure database.
SageMaker Lakehouse is a unified, open, and secure data lakehouse that now supports ABAC to provide unified access to general purpose Amazon S3 buckets, Amazon S3 Tables , Amazon Redshift data warehouses, and data sources such as Amazon DynamoDB or PostgreSQL. Implementing this solution consists of the following high-level steps.
To run analytics on their operational data, customers often build solutions that are a combination of a database, a data warehouse, and an extract, transform, and load (ETL) pipeline. ETL is the process data engineers use to combine data from different sources. Figure 2: How to create a zero-ETL integration using Amazon RDS.
In this post, we show how to build a RAG extract, transform, and load (ETL) ingestion pipeline to ingest large amounts of data into an Amazon OpenSearch Service cluster and use Amazon Relational Database Service (Amazon RDS) for PostgreSQL with the pgvector extension as a vector data store. Let’s look at the key components in more detail.
HPE Aruba Networking is the industry leader in wired, wireless, and network security solutions. Hewlett-Packard acquired Aruba Networks in 2015, making it a wireless networking subsidiary with a wide range of next-generation network access solutions. The following diagram illustrates the solution architecture.
Google Announces Cloud SQL for Microsoft SQL Server Google’s Cloud SQL now supports SQL Server in addition to PostgreSQL and MySQL Google Opens a new Cloud Region Located in Salt Lake City, Utah, it is named us-west3. Azure Sphere for IoT security goes GA This is a comprehensive security solution for IoT.
Solution overview The solution is designed to help you track the cost of your Spark applications running on EMR on EC2. The proposed solution uses a scheduled AWS Lambda function that operates on a daily basis. The utilization of these AWS services incurs additional costs for implementing this solution.
Underpinning each winning project is a diverse suite of products, solutions, and platforms, sourced from an array of vendors large and small. This is the 2022 US CIO 100 Solutions Partners. Please join us in congratulating the Solutions Partners of the 2022 US CIO 100 award winners. The 2022 winners.
This compiled data is then imported into Aurora PostgreSQL Serverless for operational reporting. Gupshup chose Aurora PostgreSQL as the operational reporting layer due to its anticipated increase in concurrency and cost-effectiveness for queries that retrieve only precalculated metrics.
Solution architecture Data lakes are usually organized using separate S3 buckets for three layers of data: the raw layer containing data in its original form, the stage layer containing intermediate processed data optimized for consumption, and the analytics layer containing aggregated data for specific use cases. Choose Create endpoint.
This post explains how you can extend the governance capabilities of Amazon DataZone to data assets hosted in relational databases based on MySQL, PostgreSQL, Oracle or SQL Server engines. This solution was built using the AWS Cloud Development Kit (AWS CDK) and was designed to be easy to set up in any AWS environment.
Open source data solutions like the ones we’ll discuss here allow them to do just that: take the software and make it theirs. In this article, we’ll dig into Hadoop, PostgreSQL, Apache Cassandra, and Elasticsearch. PostgreSQL. As the name implies, PostgreSQL is built on and extends the SQL language. Apache Cassandra.
In this post, I will demonstrate how to use the Cloudera Data Platform (CDP) and its streaming solutions to set up reliable data exchange in modern applications between high-scale microservices, and ensure that the internal state will stay consistent even under the highest load. Introduction Many modern application designs are event-driven.
Previous solutions. For instance, you might want to run an official PostgreSQL database image completely unchanged. The life cycle of data is very different than the life cycle of applications. Upgrading an application is a common occurrence, but data has to live across multiple such upgrades. Until Kubernetes 1.8,
Infomedia Ltd (ASX:IFM) is a leading global provider of DaaS and SaaS solutions that empowers the data-driven automotive ecosystem. Infomedia’s solutions help OEMs, NSCs, dealerships and 3rd party partners manage the vehicle and customer lifecycle. This is a guest post co-written with Gowtham Dandu from Infomedia.
PostgreSQL/Redshift PostgreSQL is a popular open source relation database. While NoSQL databases emerged with the advent of big data, relational databases remain widely popular and are still the best solution for many use cases. An accessible introduction into how to setup your own PostgreSQL database can be found here.
Solution overview In this scenario, we create a custom SQL direct query dataset to observe unoptimized SQL queries that are generated without dataset parameters, and demonstrate how your current custom SQL queries run if you don’t use dataset parameters. In this example, we use an Amazon RDS for PostgreSQL database.
Solution overview To implement this solution, we complete the following steps: Create an Amazon RDS for PostgreSQL instance. Create and run an AWS Glue job to extract data from the RDS for PostgreSQL DB instance using multiple job bookmark keys. Select the stack you created to deploy the solution and choose Delete.
Their Actian Vectorwise system was designed to replace Excel plugins and stock screeners but eventually evolved into a much larger and ambitious portfolio analysis solution running multiple API clusters on premises, serving some of the largest financial services firms worldwide. The downside here is over-provisioning.
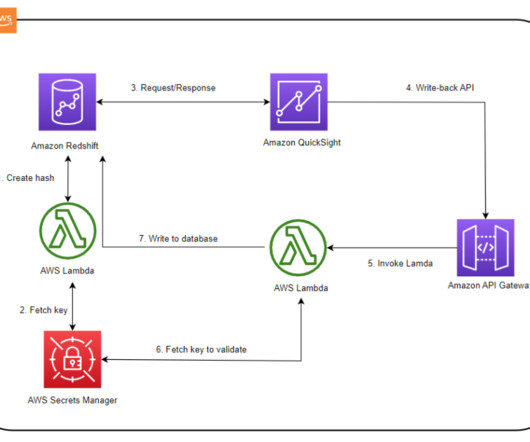
AnyCompany is a professional services firm that specializes in providing workforce solutions to their customers. AnyCompany currently uses Amazon Redshift as their enterprise data warehouse platform and QuickSight as their BI solution. You can further enhance this solution to render a web-based form when the write-back URL is opened.
Cloudera has a strong track record of providing a comprehensive solution for stream processing. Cloudera Stream Processing (CSP), powered by Apache Flink and Apache Kafka, provides a complete stream management and stateful processing solution. Deploying a new JDBC Sink connector to write data from a Kafka topic to a PostgreSQL table.
White labeling and embedding analytics tools and methodologies enhance interpretive capabilities, solve targeted challenges, address risks, and offer personalized real-time analytical solutions through smart modern real-time dashboard tools. BI solutions offer real-time access to multiple data sources in one centralized location.
These factors are why companies will spend over $12 billion on data analytics for marketing solutions by 2027. As a result, employees who work in sales acquire a lot of useful data from a sales report solution. Excel is one of the tools that can help companies use mined revenue data.
This post provides guidance on how to build scalable analytical solutions for gaming industry use cases using Amazon Redshift Serverless. Solutions should be flexible to scale up and down. Portability to multiple channels – Solutions should be compatible with most of endpoint channels like PC, mobile, and gaming platforms.
The solution? This includes all the basic backend foundations such as PostgreSQL or major products such as Salesforce or Quickbooks. Some of its pre-built solutions are focused on major categories such as consumer e-commerce or travel. The world of marketing is awash in data. Embrace a customer data platform.
Choosing the right solution to warehouse your data is just as important as how you collect data for business intelligence. In addition to its significant storage capacity, the data warehousing solution delivers several key benefits that make it an intriguing and possibly ideal choice for business intelligence.
Eightfold is transforming the world of work by providing solutions that empower organizations to recruit and retain a diverse global workforce. Solution overview Exposing a Redshift endpoint to all of Eightfold’s customers as part of the Talent Lake endeavor involved several design choices that had to be carefully considered.
You can troubleshoot your jobs by asking Amazon Q Developer to explain errors and propose solutions. He is passionate about distributed computing and using ML/AI for designing and building end-to-end solutions to address customers’ data integration needs. In his spare time, he enjoys spending time with family and friends.
This cloud service was a significant leap from the traditional data warehousing solutions, which were expensive, not elastic, and required significant expertise to tune and operate. At AWS re:Invent, we extended zero-ETL integration to additional sources specifically Aurora PostgreSQL, Dynamo DB, and Amazon RDS MySQL.
Moonfare, a private equity firm, is transitioning from a PostgreSQL-based data warehouse on AWS to a Dremio data lakehouse on AWS for business intelligence and predictive analytics. Wiesenfeld has since launched a startup called Kawa to bring similar solutions to other customers, particularly hedge funds.
You can extend the solution in directions such as the business intelligence (BI) domain with customer 360 use cases, and the risk and compliance domain with transaction monitoring and fraud detection use cases. The following figure summarizes the AWS services available to support the solution framework described so far.
Your server’s configuration is going to be essential for your cloud solutions. PostgreSQL. Another relational system, the PostgreSQL is in full compliance with top management standards; it even has ACID support. Here are a few things to look for when choosing used servers to support your cloud computing strategy.
To provide a variety of products, services, and solutions that are better suited to customers and society in each region, we have built business processes and systems that are optimized for each region and its market. Technical concepts In this section, we discuss some of the technical concepts of the solution.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content