This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Source Introduction: In this article, we will learn all the important. The post A Guide To Complete Statistics For Data Science Beginners! appeared first on Analytics Vidhya.
ArticleVideos This article was published as a part of the Data Science Blogathon. You can have data without information, but you cannot have information. The post Essential Statistical Concepts for Data Cognizance appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Hypothesis testing is one of the most important concepts in. The post Hypothesis Testing- Parametric and Non-Parametric Tests in Statistics appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Data Science is an interdisciplinary field that uses various algorithms. The post Introductory Statistics for Data Science! appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. The post Interpreting P-Value and R Squared Score on Real-Time Data – StatisticalData Exploration appeared first on Analytics Vidhya. Overview In this article, I will share my thoughts on the below.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Feature Selection is the process of selecting the features which. The post Feature Selection using Statistical Tests appeared first on Analytics Vidhya.
The post Introduction to ANOVA for Statistics and Data Science (with COVID-19 Case Study using Python) appeared first on Analytics Vidhya. Introduction “A fact is a simple statement that everyone believes. It’s innocent, unless found guilty. A Hypothesis is a novel suggestion that no one.
A Latent Space Theory for Emergent Abilities in Large Language Models ” by Hui Jiang presents a statistical explanation for emergent LLM abilities, exploring a relationship between ambiguity in a language versus the scale of models and their training data. “ Do LLMs Really Adapt to Domains? that is required in your use case.
Sisu Data is an analytics platform for structureddata that uses machine learning and statistical analysis to automatically monitor changes in data sets and surface explanations. It can prioritize facts based on their impact and provide a detailed, interpretable context to refine and support conclusions.
ArticleVideos Image by Author In statistics, correlation or dependence is any statistical relationship, whether causal or not, between two random variables or bivariate data. The post Using Predictive Power Score to Pinpoint Non-linear Correlations appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Regression analysis is used to solve problems of prediction based on datastatistical parameters. In this article, we will look at the use of a polynomial regression model on a simple example using real statisticdata.
Introduction Pandas is more than just a name – it’s short for “panel data.” Use the Data formats with pandas in economics and statistics. It refers to structureddata sets that hold observations across multiple periods for different entities or subjects. ” Now, what exactly does that mean?
This article was published as a part of the Data Science Blogathon What is Hypothesis Testing? Any data science project starts with exploring the data. When we perform an analysis on a sample through exploratory data analysis and inferential statistics we get information about the sample.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In applied Statistics and Machine Learning, Data Visualization is one. The post Must Known Data Visualization Techniques for Data Science appeared first on Analytics Vidhya.
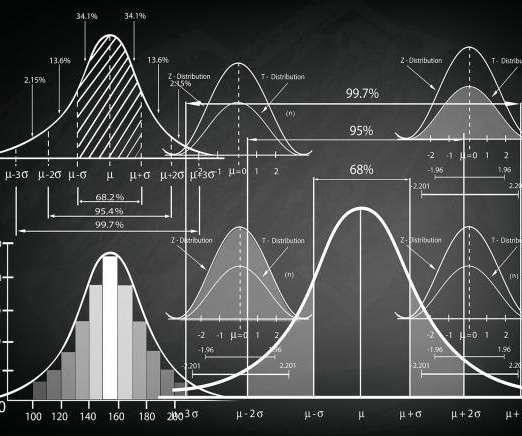
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction The normal distribution is an important class of Statistical Distribution that. The post Normal Distribution : An Ultimate Guide appeared first on Analytics Vidhya.
Sisu Data is an analytics platform for structureddata that uses machine learning and statistical analysis to automatically monitor changes in data sets and surface explanations. It can prioritize facts based on their impact and provide a detailed, interpretable context to refine and support conclusions.
Today, we’re making available a new capability of AWS Glue Data Catalog that allows generating column-level statistics for AWS Glue tables. These statistics are now integrated with the cost-based optimizers (CBO) of Amazon Athena and Amazon Redshift Spectrum , resulting in improved query performance and potential cost savings.
In life sciences, simple statistical software can analyze patient data. While this process is complex and data-intensive, it relies on structureddata and established statistical methods. Use traditional tools for structureddata and reserve LLMs for the truly complex stuff.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structureddata from open format files in Amazon S3 data lake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your data lake, enabling you to run analytical queries.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction Statistics is the foundation of Data Science. Before jumping to. The post Five Number Summary for Analysis! appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Many engineers have never worked in statistics or data science. The post Know the basics of Exploratory Data Analysis appeared first on Analytics Vidhya.
Machine Learning is the method of teaching computer programs to do a specific task accurately (essentially a prediction) by training a predictive model using various statistical algorithms leveraging data. Introduction Let’s have a simple overview of what Machine Learning is. Source: [link] For […].
This article was published as a part of the Data Science Blogathon. Introduction A popular and widely used statistical method for time series forecasting. The post How to Create an ARIMA Model for Time Series Forecasting in Python appeared first on Analytics Vidhya.
We enhanced support for querying Apache Iceberg data and improved the performance of querying Iceberg up to threefold year-over-year. You can invoke these models using familiar SQL commands, making it simpler than ever to integrate generative AI capabilities into your data analytics workflows.
The data that data scientists analyze draws from many sources, including structured, unstructured, or semi-structureddata. The more high-quality data available to data scientists, the more parameters they can include in a given model, and the more data they will have on hand for training their models.
They emphasize access to and manipulation of large databases of structureddata, often a time-series of internal company data and sometimes external data. Commonly used models include: Statistical models. XLSTAT is an Excel data analysis add-on geared for corporate users and researchers. Model-driven DSS.
Using techniques from a range of disciplines, including computer programming, mathematics, and statistics, data analysts draw conclusions from data to describe, predict, and improve business performance. Data analyst role Data analysts mostly work with an organization’s structureddata.
Computer Vision: Data Mining: Data Science: Application of scientific method to discovery from data (including Statistics, Machine Learning, data visualization, exploratory data analysis, experimentation, and more). NLG is a software process that transforms structureddata into human-language content.
An analytical report is a type of a business report that uses qualitative and quantitative company data to analyze as well as evaluate a business strategy or process while empowering employees to make data-driven decisions based on evidence and analytics. Patient Wait Time.
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon Redshift is used to analyze structured and semi-structureddata across data warehouses, operational databases, and data lakes.
Machine learning identifies patterns in data using algorithms that are primarily based on traditional methods of statistical learning. It’s most helpful in analyzing structureddata. Based on the concept of neural networks, it’s useful for analyzing images, videos, text and other unstructured data.
Introduction Multicollinearity might be a handful to pronounce but it’s a topic you should be aware of in the machine learning field. The post What is Multicollinearity? Here’s Everything You Need to Know appeared first on Analytics Vidhya.
I recently saw an informal online survey that asked users which types of data (tabular, text, images, or “other”) are being used in their organization’s analytics applications. This was not a scientific or statistically robust survey, so the results are not necessarily reliable, but they are interesting and provocative.
This article was published as a part of the Data Science Blogathon Introduction Q-Q plots are also known as Quantile-Quantile plots. As the name suggests, they plot the quantiles of a sample distribution against quantiles of a theoretical distribution.
AWS Glue Data catalog now automates generating statistics for new tables The AWS Glue Data Catalog now automates generating statistics for new tables. These statistics are integrated with a cost-based optimizer (CBO) from Amazon Redshift and Athena, resulting in improved query performance and potential cost savings.
For example, they may not be easy to apply or simple to comprehend but thanks to bench scientists and mathematicians alike, companies now have a range of logistical frameworks for analyzing data and coming to conclusions. More importantly, we also have statistical models that draw error bars that delineate the limits of our analysis.
Most commonly, we think of data as numbers that show information such as sales figures, marketing data, payroll totals, financial statistics, and other data that can be counted and measured objectively. This is quantitative data. It’s “hard,” structureddata that answers questions such as “how many?”
Overview A/B testing is a popular way to test your products and is gaining steam in the data science field Here, we’ll understand what. The post A/B Testing for Data Science using Python – A Must-Read Guide for Data Scientists appeared first on Analytics Vidhya.
I recently saw an informal online survey that asked users what types of data (tabular; text; images; or “other”) are being used in their organization’s analytics applications. This was not a scientific or statistically robust survey, so the results are not necessarily reliable, but they are interesting and provocative.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In my previous article, I talk about the theoretical concepts. The post Feature Engineering – How to Detect and Remove Outliers (with Python Code) appeared first on Analytics Vidhya.
Overview Microsoft Excel is one of the most widely used tools for data analysis Learn the essential Excel functions used to analyze data for. The post 10+ Simple Yet Powerful Excel Tricks for Data Analysis appeared first on Analytics Vidhya.
ArticleVideos This article was published as a part of the Data Science Blogathon. What is Multicollinearity? One of the key assumptions for a regression-based. The post Multicollinearity: Problem, Detection and Solution appeared first on Analytics Vidhya.
ArticleVideo Book Introduction In this article, we will be discussing two different types of correlation coefficients i.e. Pearson correlation coefficient and Spearman correlation coefficient. The post Comparison of Pearson and Spearman correlation coefficients appeared first on Analytics Vidhya.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content