This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Probability is a cornerstone of statistics and data science, providing a framework to quantify uncertainty and make predictions. Understanding joint, marginal, and conditional probability is critical for analyzing events in both independent and dependent scenarios. What is Probability?
Inspired by the chance and excitement of the Monte Carlo Casino in Monaco, this powerful statistical method transforms the uncertainty of life into a tool for making informed decisions. Introduction Imagine being able to predict the future with a roll of the dice—sounds intriguing, right? Welcome to the world of Monte Carlo simulation!
by AMIR NAJMI & MUKUND SUNDARARAJAN Data science is about decision making under uncertainty. Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. But there are other kinds of uncertainty, at least as important, that are not statistical in nature.
There was a lot of uncertainty about stability, particularly at smaller companies: Would the company’s business model continue to be effective? Economic uncertainty caused by the pandemic may be responsible for the declines in compensation. Average salary by tools for statistics or machine learning. What about Kafka? (See
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. Machine learning adds uncertainty. Underneath this uncertainty lies further uncertainty in the development process itself.
It’s no surprise, then, that according to a June KPMG survey, uncertainty about the regulatory environment was the top barrier to implementing gen AI. So here are some of the strategies organizations are using to deploy gen AI in the face of regulatory uncertainty. AI is a black box.
This classification is based on the purpose, horizon, update frequency and uncertainty of the forecast. With those stakes and the long forecast horizon, we do not rely on a single statistical model based on historical trends. A single model may also not shed light on the uncertainty range we actually face.
AI and Uncertainty. Some people react to the uncertainty with fear and suspicion. Recently published research addressed the question of “ When Does Uncertainty Matter?: Understanding the Impact of Predictive Uncertainty in ML Assisted Decision Making.”. People are unsure about AI because it’s new. AI you can trust.
In addition, they can use statistical methods, algorithms and machine learning to more easily establish correlations and patterns, and thus make predictions about future developments and scenarios. Most use master data to make daily processes more efficient and to optimize the use of existing resources.
A DSS supports the management, operations, and planning levels of an organization in making better decisions by assessing the significance of uncertainties and the tradeoffs involved in making one decision over another. Commonly used models include: Statistical models. They emphasize access to and manipulation of a model.
Bootstrap sampling techniques are very appealing, as they don’t require knowing much about statistics and opaque formulas. Instead, all one needs to do is resample the given data many times, and calculate the desired statistics. Don’t compare confidence intervals visually. Pitfall #1: Inaccurate confidence intervals.
Statistics over time have proven that the firearms industry does exceptionally well under two conditions: right before a presidential election and during a national crisis. Likewise, when a national crisis emerges, people rush to buy firearms and ammunition out of fear, uncertainty, and preparedness. Currently, the U.S.
Such bleak statistics suggest that indecision around how to proceed with genAI is paralyzing organizations and preventing them from developing strategies that will unlock value. Even as organizations plan to boost spending on genAI in 2024. Even as organizations plan to boost spending on genAI in 2024.
Systems should be designed with bias, causality and uncertainty in mind. Uncertainty is a measure of our confidence in the predictions made by a system. We need to understand and provide the greatest human oversight on systems with the greatest levels of uncertainty. System Design. Human Judgement & Oversight.
This was not a scientific or statistically robust survey, so the results are not necessarily reliable, but they are interesting and provocative. I recently saw an informal online survey that asked users which types of data (tabular, text, images, or “other”) are being used in their organization’s analytics applications.
The responses show a surfeit of concerns around data quality and some uncertainty about how best to address those concerns. His insight was a corrective to the collective bias of the Army’s Statistical Research Group (SRG). Key survey results: The C-suite is engaged with data quality. The SRG could not imagine that it was missing data.
More importantly, we also have statistical models that draw error bars that delineate the limits of our analysis. Good data scientists can also reduce some of this uncertainty through cleansing. People even spell their names differently from year to year, day to day, or even line to line on the same form.
Most commonly, we think of data as numbers that show information such as sales figures, marketing data, payroll totals, financial statistics, and other data that can be counted and measured objectively. All descriptive statistics can be calculated using quantitative data. Digging into quantitative data. This is quantitative data.
CIOs are readying for another demanding year, anticipating that artificial intelligence, economic uncertainty, business demands, and expectations for ever-increasing levels of speed will all be in play for 2024. But at the end of the day, it boils down to statistics. Statistics can be very misleading.
Capitalizing on SAP’s in-memory database, the solution is renowned for meeting the exact challenges Huabao hoped to address navigating uncertainty and refining business results. Rise with SAP S/4HANA Cloud, Private Edition , an ERP tool for large enterprises, would be utilized as the digital core of the new platform.
Women disproportionately affected by burnout For women, the statistics around burnout are even worse. Keeping in line with employees’ clear desire to have flexible work options, 43% also said that they valued remote work business allowances, to ensure they have all the necessary resources at home to effectively perform their jobs.
Seeing the actual data as well helps us keep in mind that statistical models are estimates, built on assumptions, which are never entirely true. So, to recap, noise in communication, including data visualization, is content that isn’t part of and doesn’t support the intended message or content that isn’t truthful.
From a data science perspective, it is possible to begin immediately by framing problems regarding machine learning or statistical issues. VUCA stands for volatility, uncertainty, complexity, and ambiguity; these terms could be relevant to many data-based projects. Data strategy in a VUCA environment.
But importance sampling in statistics is a variance reduction technique to improve the inference of the rate of rare events, and it seems natural to apply it to our prevalence estimation problem. Statistical Science. Statistics in Biopharmaceutical Research, 2010. [4] High Risk 10% 5% 33.3% How Many Strata? 16 (2): 101–133. [3]
Cybersecurity risks This one is no surprise, given the scary statistics on the growing number of cyberattacks, the rate of successful attacks, and the increasingly high consequences of being breached. Surveys show a mixed executive outlook, indicating a level of uncertainty about what to expect.
These circumstances have induced uncertainty across our entire business value chain,” says Venkat Gopalan, chief digital, data and technology officer, Belcorp. “As To address the challenges, the company has leveraged a combination of computer vision, neural networks, NLP, and fuzzy logic.
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. Crucially, it takes into account the uncertainty inherent in our experiments.
Their latest placement and salary statistics are: 88% of Insight Fellows accept a job offer in their chosen field within 6 months of finishing the Fellows Program, and the median time to accept a job offer is 8 weeks. They work at over 700 companies across North America, with many of them working as heads of their teams.
For example, imagine a fantasy football site is considering displaying advanced player statistics. A ramp-up strategy may mitigate the risk of upsetting the site’s loyal users who perhaps have strong preferences for the current statistics that are shown. One reason to do ramp-up is to mitigate the risk of never before seen arms.
Markets and competition today are highly dynamic and complex, and the future is characterized by uncertainty – not least because of COVID-19. This uncertainty is currently at the forefront of everyone‘s minds. Satisfying customer needs and securing solvency in volatile markets both require quick decisions and decisive action. .
Markets and competition today are highly dynamic and complex, and the future is characterized by uncertainty – not least because of COVID-19. This uncertainty is currently at the forefront of everyone‘s minds. Satisfying customer needs and securing solvency in volatile markets both require quick decisions and decisive action. .
To adapt to continued market uncertainty, businesses need to be agile and resilient in order to ensure continued growth. Both statistics are alarming considering market uncertainty increases the demand for more frequent, more accurate forecasts and reporting.
This statistic will likely widen an already sizable skills gap as more financial professionals retire from the workforce. CEOs are increasingly partnering with CFOs to guide companies through this current uncertainty. Achieving predictability amidst uncertainty requires finance teams to enter a new stage of digital transformation.
You should describe the uncertainty of your findings. You should document the steps that you took, including the statistics that you used, and maintain the data that you produced during the course of your work. You should present your findings as comprehensively as necessary to enable the level of understanding that’s needed.
For many businesses and organizations, this can introduce uncertainties that slow adoption of generative AI, particularly in highly regulated industries. will enable organizations to create synthetic tabular data that is pre-labeled and preserves the statistical properties of their original enterprise data.
Quantification of forecast uncertainty via simulation-based prediction intervals. Prediction Intervals A statistical forecasting system should not lack uncertainty quantification. Journal of Official Statistics 6.1 Large-Scale Parallel Statistical Forecasting Computations in R ”, Google Research report. [8]
In this time of terrifying uncertainty, some might focus on their own career journey over others. Wishlists are especially off-putting to women, who statistically will only apply to job opportunities if they meet 100% of the listed requirements, versus men applying when they meet 60%. However, many are looking out for their colleagues.
Overnight, the impact of uncertainty, dynamics and complexity on markets could no longer be ignored. Local events in an increasingly interconnected economy and uncertainties such as the climate crisis will continue to create high volatility and even chaos. The COVID-19 pandemic caught most companies unprepared.
SCOTT Time series data are everywhere, but time series modeling is a fairly specialized area within statistics and data science. They may contain parameters in the statistical sense, but often they simply contain strategically placed 0's and 1's indicating which bits of $alpha_t$ are relevant for a particular computation. by STEVEN L.
With 66% of respondents seeing an increase in demand for operational reporting in 2022, it’s crucial that organizations invest in automating these processes to stabilize through economic uncertainty. Key findings include: Operational reporting costs 71% of IT departments, on average, 1 day per week, or $23,730 per year in salary costs.
Remember that the raw number is not the only important part, we would also measure statistical significance. They might deal with uncertainty, but they're not random. The result? The properties with professional photography had 2-3 times the number of bookings! Airbnb had enough data points to be confident in their results.
Integrity of statistical estimates based on Data. Having spent 18 years working in various parts of the Insurance industry, statistical estimates being part of the standard set of metrics is pretty familiar to me [7]. The thing with statistical estimates is that they are never a single figure but a range. million ± £0.5
We often use statistical models to summarize the variation in our data, and random effects models are well suited for this — they are a form of ANOVA after all. In the context of prediction problems, another benefit is that the models produce an estimate of the uncertainty in their predictions: the predictive posterior distribution.
For example, applying machine learning to wind forecasting is expected to reduce uncertainty in wind energy production by more than 45% and will allow utilities to integrate wind more easily with traditional forms of power supply.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



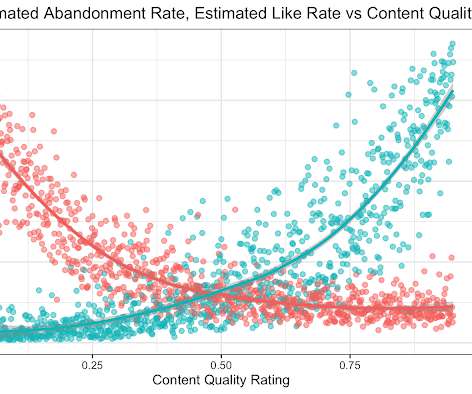



























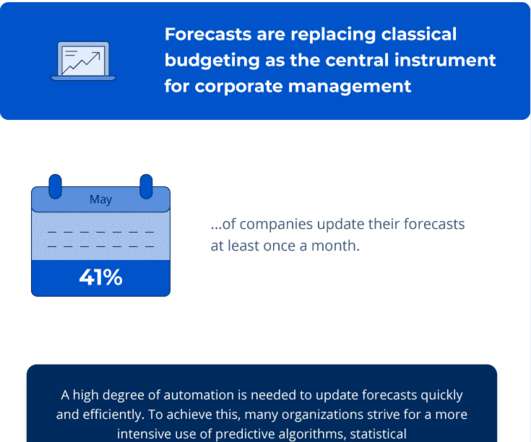




















Let's personalize your content