This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Language understanding benefits from every part of the fast-improving ABC of software: AI (freely available deep learning libraries like PyText and language models like BERT ), big data (Hadoop, Spark, and Spark NLP ), and cloud (GPU's on demand and NLP-as-a-service from all the major cloud providers). NLP Pipeline API’s.
Third, any commitment to a disruptive technology (including data-intensive and AI implementations) must start with a business strategy. These changes may include requirements drift, data drift, model drift, or concept drift. I suggest that the simplest business strategy starts with answering three basic questions: What?
Through a visual designer, you can configure custom AI search flowsa series of AI-driven data enrichments performed during ingestion and search. Flows are a pipeline of processor resources. Ingest flows are created to enrich data as its added to an index. They consist of: A data sample of the documents you want to index.
Enterprise data is brought into data lakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. These instructions are included in the prompt sent to the Bedrock model.
In recent years, data lakes have become a mainstream architecture, and data quality validation is a critical factor to improve the reusability and consistency of the data. In this post, we provide benchmark results of running increasingly complex data quality rulesets over a predefined test dataset.
Introduction In the real world, obtaining high-quality annotated data remains a challenge. Therefore we explored how GenAI could automate several stages of the graph-building pipeline. Therefore we explored how GenAI could automate several stages of the graph-building pipeline. sec Llama 80 57 66.8 sec CoT prompt GPT-4o 78.9
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in data lakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your data lake.
With a few clicks, MSK Connect allows you to deploy connectors that move data between Apache Kafka and external systems. MSK Connect now supports the ability to delete MSK Connect worker configurations, tag resources, and manage worker configurations and custom plugins using AWS CloudFormation. Provide a name and optional description.
Backtesting is a process used in quantitative finance to evaluate trading strategies using historical data. We specifically explore how Amazon EMR and the newly developed Apache Iceberg branching and tagging feature can address the challenge of look-ahead bias in backtesting.
We have the tools to create data analytics workflows that address AI bias. When our work processes for creating and monitoring analytics contain built-in controls against bias, data analytics organizations will no longer be dependent on individual social awareness or heroism. What Is AI Bias? What Is AI Bias?
As enterprises collect increasing amounts of data from various sources, the structure and organization of that data often need to change over time to meet evolving analytical needs. Schema evolution enables adding, deleting, renaming, or modifying columns without needing to rewrite existing data. Query the data using Athena.
AWS DataPipeline helps customers automate the movement and transformation of data. With DataPipeline, customers can define data-driven workflows, so that tasks can be dependent on the successful completion of previous tasks. The option you choose depends on your current workload on DataPipeline.
Data is a key enabler for your business. Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless data integration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for data integration?
Amazon Redshift is a cloud data warehousing service that provides high-performance analytical processing based on a massively parallel processing (MPP) architecture. Building and maintaining datapipelines is a common challenge for all enterprises. Macros – These are pieces of code that can be reused multiple times.
In May 2021 at the CDO & Data Leaders Global Summit, DataKitchen sat down with the following data leaders to learn how to use DataOps to drive agility and business value. Kurt Zimmer, Head of Data Engineering for Data Enablement at AstraZeneca. Jim Tyo, Chief Data Officer, Invesco. Data takes a long journey.
In this paper, we showcase how to easily deploy a banking application on both IBM Cloud for Financial Services and Satellite , using automated CI/CD/CC pipelines in a common and consistent manner. To achieve the deployment on Satellite the CI/CC pipelines were reused, and a new CD pipeline was created.
To simplify data access and empower users to leverage trusted information, organizations need a better approach that provides better insights and business outcomes faster, without sacrificing data access controls. There are many different approaches, but you’ll want an architecture that can be used regardless of your data estate.
Cloudera delivers an enterprise data cloud that enables companies to build end-to-end datapipelines for hybrid cloud, spanning edge devices to public or private cloud, with integrated security and governance underpinning it to protect customers data. Data Science and machine learning workloads using CDSW.
Modak, a leading provider of modern data engineering solutions, is now a certified solution partner with Cloudera. Customers can now seamlessly automate migration to Cloudera’s Hybrid Data Platform — Cloudera Data Platform (CDP) to dynamically auto-scale cloud services with Cloudera Data Engineering (CDE) integration with Modak Nabu.
Here are some tips and tricks of the trade to prevent well-intended yet inappropriate data engineering and data science activities from cluttering or crashing the cluster. For data engineering and data science teams, CDSW is highly effective as a comprehensive platform that trains, develops, and deploys machine learning models.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a managed orchestration service for Apache Airflow that you can use to set up and operate datapipelines in the cloud at scale. The data engineering team wants to separate the raw data into its own AWS account (Account B in the diagram) for increased security and control.
Data transformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. Picture a scenario where you, the VP of Data and Analytics, are in charge of your data and analytics environments and workloads running on AWS where you manage a team of data engineers and analysts.
This encompasses tasks such as integrating diverse data from various sources with distinct formats and structures, optimizing the user experience for performance and security, providing multilingual support, and optimizing for cost, operations, and reliability.
As data analytics use cases grow, factors of scalability and concurrency become crucial for businesses. Your analytic solution architecture should be able to handle large data volumes at high concurrency and without compromising speed, thereby delivering a scalable high-performance analytics environment. Enter the endpoint name.
This Domino Data Science Field Note provides highlights and excerpted slides from Chloe Mawer ’s “ The Ingredients of a Reproducible Machine Learning Model ” talk at a recent WiMLDS meetup. Mawer is a Principal Data Scientist at Lineage Logistics as well as an Adjunct Lecturer at Northwestern University. Introduction.
Proceeding with caution While H&R Block’s leadership and board were enticed by the possibilities of gen AI, Lowden notes he had to address some concerns before they fully bought into the project, especially with regard to safety and data privacy. “No The first was safety and data privacy testing. The third was guardrails.
Metadata management is key to wringing all the value possible from data assets. However, most organizations don’t use all the data at their disposal to reach deeper conclusions about how to drive revenue, achieve regulatory compliance or accomplish other strategic objectives. Quite simply, metadata is data about data.
With in-place version upgrades, upgrading your application runtime version can be achieved simply, statefully, and without incurring data loss or adding additional orchestration to your workload. In addition, logs, metrics, application tags, application configurations, VPCs, and other settings are retained between version upgrades.
Stage 1: Development automation Infrastructure automation (IaC) and pipeline automation are self-contained within the development team, which makes automation a great place to start. Build AuthN/AuthZ integration patterns that abstract nuances and standardize authentication and authorization of applications, data and services.
Over the years, organizations have invested in creating purpose-built, cloud-based data lakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple data lakes, each built on different technology stacks.
Amazon EMR provides a managed Hadoop framework that makes it straightforward, fast, and cost-effective to process vast amounts of data using EC2 instances. Amazon EMR with Spot Instances allows you to reduce costs for running your big data workloads on AWS. The following diagram illustrates this architecture.
How dbt Core aids data teams test, validate, and monitor complex data transformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based data transformations, has become a must-have tool for modern data teams as the complexity of datapipelines grows.
However, various challenges arise in the QA domain that affect test case inventory, test case automation and defect volume. Managing test case inventory can become problematic due to the sheer volume of cases, which lead to inefficiencies and resource constraints.
Customers face a challenge when distributing cloud resources between different teams running workloads such as development, testing, or production. In this post, we show how to define per-team resource limits for big data workloads using EMR serverless. and you need to test the same workload on Amazon EMR 6.10.0,
In this post, we walk through creating a new PySpark project that analyzes weather data from the NOAA Global Surface Summary of Day open dataset. to run and is tested on macOS, Linux, and Windows. One use case for this is with CI/CD pipelines. Most CI/CD pipelines allow you to access the git tag.
In this post, you can learn about the Managed Service for Apache Flink cost model, areas to save on cost in your Apache Flink applications, and overall gain a better understanding of your data processing pipelines. An additional KPU per application is also charged for orchestration and not directly used for data processing.
Today, we are pleased to announce that Amazon DataZone is now able to present data quality information for data assets. Other organizations monitor the quality of their data through third-party solutions. Amazon DataZone now integrates directly with AWS Glue to display data quality scores for AWS Glue Data Catalog assets.
Guest post by Jeff Melching, Distinguished Engineer / Chief Architect Data & Analytics. We’ve developed a model-driven software platform, called Climate FieldView , that captures, visualizes, and analyzes a vast array of data for farmers and provides new insight and personalized recommendations to maximize crop yield.
As most organizations, that have turned to Google Analytics (GA) as a digital analytics solution, mature they discover a more pressing need to integrate this data silo with the rest of their organization’s data to enable better analytics and resulting product development and fraud detection.
In a previous blog of this series, Turning Streams Into Data Products , we talked about the increased need for reducing the latency between data generation/ingestion and producing analytical results and insights from this data. containing data that may have to be used to enrich the streaming data.
Rapidly deploying applications to cloud requires not just development acceleration with continuous integration, deployment and testing (CI/CD/CT), It also requires supply chain lifecycle acceleration, which involves multiple other groups such as governance risk and compliance (GRC), change management, operations, resiliency and reliability.
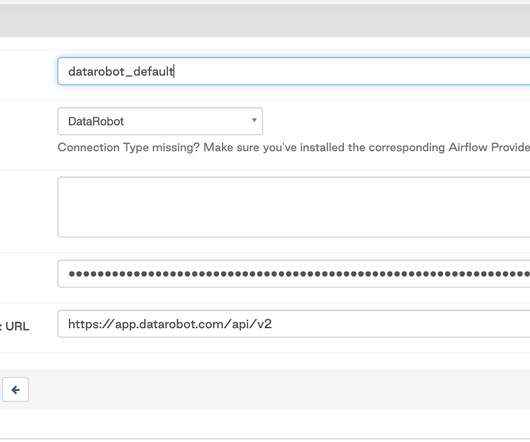
Airflow is a perfect tool to orchestrate stages of the DataRobot machine learning (ML) pipeline, because it provides an easy but powerful solution to integrate DataRobot capabilities into bigger pipelines, combine it with other services, as well as to clean your data, and store or publish the results. DataRobot Provider Modules.
Episode 4: Unlocking the Value of Enterprise AI with Data Engineering Capabilities. Unlocking the Value of Enterprise AI with Data Engineering Capabilities. They discuss how the data engineering team is instrumental in easing collaboration between analysts, data scientists and ML engineers to build enterprise AI solutions.
It’s official – Cloudera and Hortonworks have merged , and today I’m excited to announce the availability of Cloudera Data Science Workbench (CDSW) for Hortonworks Data Platform (HDP). Trusted by large data science teams across hundreds of enterprises —. Sound familiar? What is CDSW? Install any library or framework (e.g.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























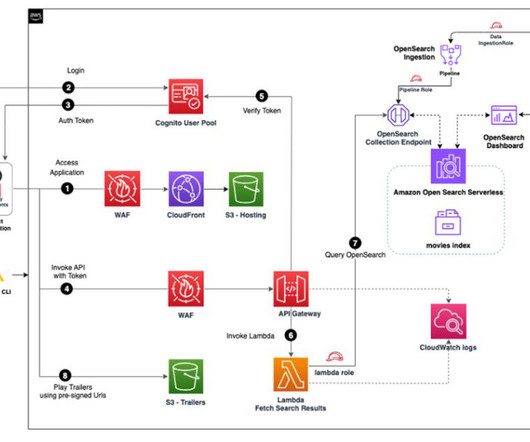
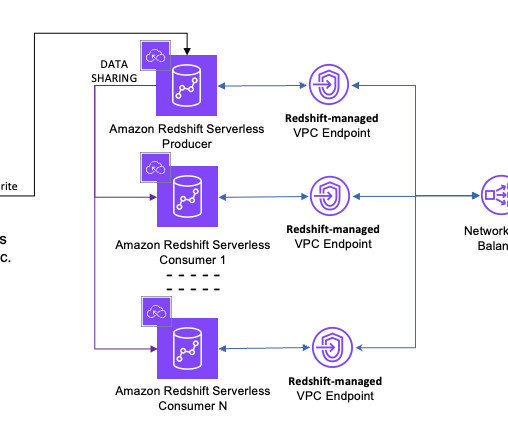






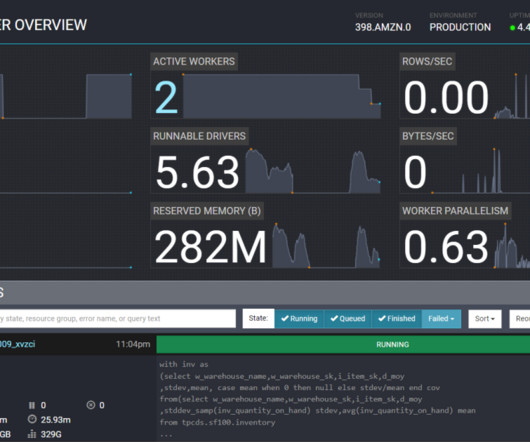




















Let's personalize your content