This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
athena_sql_generating_instructions = """ Read database schema inside the tags which contains a list of table names and their schemas to do the following: 1. These SQL generating instructions specify which compute engine the SQL query should run on and other instructions to guide the model in generating the SQL query.
This middleware consists of custom code that runs data flows to stitch datatransformations, search queries, and AI enrichments in varying combinations tailored to use cases, datasets, and requirements. Ingest flows are created to enrich data as its added to an index. Flows are a pipeline of processor resources.
In other words, kind of like Hansel and Gretel in the forest, your data leaves a trail of breadcrumbs – the metadata – to record where it came from and who it really is. So the first step in any data lineage mapping project is to ensure that all of your datatransformation processes do in fact accurately record metadata.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
Governance – At CFM, our Data teams are split into autonomous teams that can use different technologies based on their requirements and skills. To share data to our internal consumers, we use AWS Lake Formation with LF-Tags to streamline the process of managing access rights across the organization.
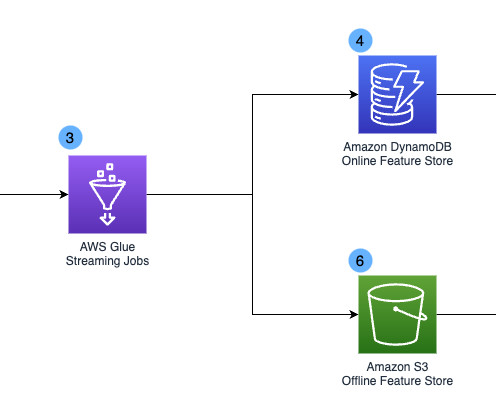
We choose AWS Glue mainly due to its serverless nature, which simplifies infrastructure management with automatic provisioning and worker management, and the ability to perform complex datatransformations at scale. The data infrastructure team built an abstraction layer on top of Spark and integrated services.
Building a Data Culture Within a Finance Department. Our finance users tell us that their first exposure to the Alation Data Catalog often comes soon after the launch of organization-wide datatransformation efforts. After all, finance is one of the greatest consumers of data within a business.
Datatransformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset.
This means there are no unintended data errors, and it corresponds to its appropriate designation (e.g., Here, it all comes down to the datatransformation error rate. Data time-to-value: evaluates how long it takes you to gain insights from a data set. Remember: keeping your data high-quality isn’t a one-time job.
The new approach involved federating its vast and globally dispersed data repositories in the cloud with Amazon Web Services (AWS). Unifying its data within a centralized architecture allows AstraZeneca’s researchers to easily tag, search, share, transform, analyze, and govern petabytes of information at a scale unthinkable a decade ago. .
Insights hidden in your data are essential for optimizing business operations, finetuning your customer experience, and developing new products — or new lines of business, like predictive maintenance. And as businesses contend with increasingly large amounts of data, the cloud is fast becoming the logical place where analytics work gets done.
The platform converges data cataloging, data ingestion, data profiling, datatagging, data discovery, and data exploration into a unified platform, driven by metadata. Modak Nabu automates repetitive tasks in the data preparation process and thus accelerates the data preparation by 4x.
The difference lies in when and where datatransformation takes place. In ETL, data is transformed before it’s loaded into the data warehouse. In ELT, raw data is loaded into the data warehouse first, then it’s transformed directly within the warehouse.
In the next step, clauses are identified and logical relationships are formalized – either via an automated NLP process using a large language model (LLM) or by manual annotation and tagging using the RASE method. The rules are formalized automatically via NLP. Manual formalization requires expression authoring.
With Amazon AppFlow, you can run data flows at nearly any scale at the frequency you choose—on a schedule, in response to a business event, or on demand. You can configure datatransformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps.
Getting this AI properly trained required a huge learning dataset with countless documents that were tagged according to specific criteria. Accurately prepared data is the base of AI. As an AI product manager, here are some important data-related questions you should ask yourself: What is the problem you’re trying to solve?
Scale effectively: Leverage taxonomies to ensure consistent modeling outcomes when introducing new data sets or changing business demands. Track data lineage: Document data origins, record datatransformation and movement, and visualize flow throughout the entire data lifecycle.
Every time the business requirement changes (such as adding data sources or changing datatransformation logic), you make changes on the AWS Glue app stack and re-provision the stack to reflect your changes. runs all the jobs including a specific tag, then verifies the state and its duration.
Now, joint users will get an enhanced view into cloud and datatransformations , with valuable context to guide smarter usage. Integrating helpful metadata into user workflows gives all people, from data scientists to analysts , the context they need to use data more effectively.
A data warehouse is typically used by companies with a high level of data diversity or analytical requirements. Let’s look at why: Data Quality and Consistency.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This datatransformation tool enables data analysts and engineers to transform, test and document data in the cloud data warehouse. We also populated our internal data catalog with these descriptions.
Organizations have spent a lot of time and money trying to harmonize data across diverse platforms , including cleansing, uploading metadata, converting code, defining business glossaries, tracking datatransformations and so on.
Select Allow external engines to filter data in Amazon S3 locations registered with Lake Formation. Choose Amazon EMR for Session tag values. Choose Databases under Data Catalog in the navigation pane. Melody Yang is a Senior Big Data Solution Architect for Amazon EMR at AWS. Enter your AWS account ID for AWS account IDs.
Data Analysis Report (by FineReport ) Note: All the data analysis reports in this article are created using the FineReport reporting tool. Leveraging the advanced enterprise-level web reporting tool capabilities of FineReport , we empower businesses to achieve genuine datatransformation. Try FineReport Now 1.
An active data governance framework includes: Assigning data stewards. Standardizing data formats. Identifying structured and unstructured data. Setting data management policies, like taggingdata. The Alation Data Catalog has helped the State of Tennessee accomplish this and more.
Solutions Architect – AWS SafeGraph is a geospatial data company that curates over 41 million global points of interest (POIs) with detailed attributes, such as brand affiliation, advanced category tagging, and open hours, as well as how people interact with those places.
Most web analytics tools (including all the ones mentioned above) provide not great data about consumption of your website on mobile devices. So if you want really good mobile behavior data (in a separate but useful silo) then go get Percent Mobile. I am forgetting the other 25 features these tools provide for free.
By Industry Businesses from many industries use embedded analytics to make sense of their data. In a recent study by Mordor Intelligence , financial services, IT/telecom, and healthcare were tagged as leading industries in the use of embedded analytics. DataTransformation and Enrichment Data can be enriched for analysis.
Streaming pipelines used Spark Streaming to ingest real-time data from Kafka, writing raw datasets to an Amazon Simple Storage Service (Amazon S3) data lake while simultaneously loading them into BigQuery and Google Cloud Storage to build logical data layers.
Flink SQL and Confluent Avro data type mapping limitation Flink provides several APIs designed for different levels of abstraction and user expertise: Flink SQL sits at the highest level, allowing users to express datatransformations using familiar SQL syntax, which is ideal for analysts and teams comfortable with relational concepts.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content