This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
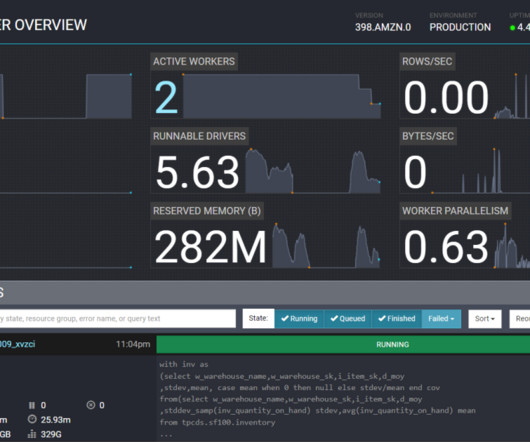
In this post, we provide benchmark results of running increasingly complex data quality rulesets over a predefined test dataset. Dataset details The test dataset contains 104 columns and 1 million rows stored in Parquet format. We define eight different AWS Glue ETL jobs where we run the data quality rulesets.
Lake Formation tag-based access control (LF-TBAC) is an authorization strategy that defines permissions based on attributes. In Lake Formation, these attributes are called LF-Tags. You can attach LF-Tags to Data Catalog resources, Lake Formation principals, and table columns. You can see the associated database LF-Tags.
AWS Glue is a serverless data integration service that enables you to run extract, transform, and load (ETL) workloads on your data in a scalable and serverless manner. Because an AWS Glue profile is a resource identified by an ARN, all the default IAM controls apply, including action-based, resource-based, and tag-based authorization.
In this post, we showcase how to use AWS Glue with AWS Glue Data Quality , sensitive data detection transforms , and AWS Lake Formation tag-based access control to automate data governance. For the purpose of this post, the following governance policies are defined: No PII data should exist in tables or columns tagged as public.
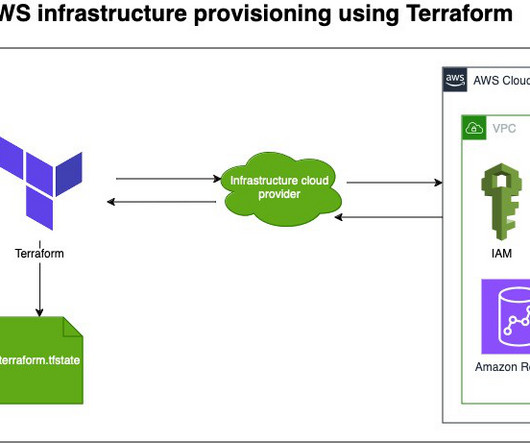
This post demonstrates how to orchestrate an end-to-end extract, transform, and load (ETL) pipeline using Amazon Simple Storage Service (Amazon S3), AWS Glue , and Amazon Redshift Serverless with Amazon MWAA. This is done by invoking AWS Glue ETL jobs and writing to data objects in a Redshift Serverless cluster in Account B.
To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset. This team is allowed to create AWS Glue for Spark jobs in development, test, and production environments. jobs because this feature will help reduce cost and optimize your ETL jobs.
This zero-ETL integration reduces the complexity and operational burden of data replication to let you focus on deriving insights from your data. When end-users in the appropriate user groups access Amazon S3 using AWS Glue ETL for Apache Spark , they will then automatically have the necessary permissions to read and write data.
Data Pipeline has been a foundational service for getting customer off the ground for their extract, transform, load (ETL) and infra provisioning use cases. Before starting any production workloads after migration, you need to test your new workflows to ensure no disruption to production systems. Choose ETL jobs.
Due to this limitation, the cost of failures of long-running extract, transform, and load (ETL) and batch queries on Trino was high in terms of completion time, compute wastage, and spend. These new enhancements in Trino with Amazon EMR provide improved resiliency for running ETL and batch workloads on Spot Instances with reduced costs.
We illustrate a cross-account sharing use case, where a Lake Formation steward in producer account A shares a federated Hive database and tables using LF-Tags to consumer account B. The admin continues to set up Lake Formation tag-based access control (LF-TBAC) on the federated Hive database and share it to account B.
They have dev, test, and production clusters running critical workloads and want to upgrade their clusters to CDP Private Cloud Base. Hive-on-Tez for better ETL performance. Customer Environment: The customer has three environments: development, test, and production. Test and QA. Test and QA. Background: .
It also applies general software engineering principles like integrating with git repositories, setting up DRYer code, adding functional test cases, and including external libraries. Tests – These are assertions you make about your models and other resources in your dbt project (such as sources, seeds, and snapshots). project-dir.
Test access to the producer cataloged Amazon S3 data using EMR Serverless in the consumer account. Test access using Athena queries in the consumer account. Test access using SageMaker Studio in the consumer account. It is recommended to use test accounts. The producer account will host the EMR cluster and S3 buckets.
Spark is primarily used to create ETL workloads by data engineers and data scientists. Impala only masquerades as an ETL pipeline tool: use NiFi or Airflow instead It is common for Cloudera Data Platform (CDP) users to ‘test’ pipeline development and creation with Impala because it facilitates fast, iterate development and testing.
The following are common asks from our customers: Is it possible to develop and test AWS Glue data integration jobs on my local laptop? The software development lifecycle on AWS defines the following six phases: Plan, Design, Implement, Test, Deploy, and Maintain. Test In the testing phase, you check the implementation for bugs.
Import existing Excel or CSV files, use the drag-and-drop feature to extract the mappings from your ETL scripts, or manually populate the inventory to then be visualized with the lineage analyzer. Data Cataloging: Catalog and sync metadata with data management and governance artifacts according to business requirements in real time.
It’s easier to map, move and test data for regular maintenance of existing structures, movement from legacy systems to new systems during a merger or acquisition or a modernization effort. Quicker project delivery. Greater productivity & reduced costs. Digital transformation.
A data domain producer maintains its own ETL stack using AWS Glue , AWS Lambda to process, AWS Glue Databrew to profile the data and prepare the data asset (data product) before cataloguing it into AWS Glue Data Catalog in their account. Producers ingest data into their S3 buckets through pipelines they manage, own, and operate.
Additionally, it manages table definitions in the AWS Glue Data Catalog , containing references to data sources and targets of extract, transform, and load (ETL) jobs in AWS Glue. It is possible to define stages (DEV, INT, PROD) in each layer to allow structured release and test without affecting PROD.
Synthea is a synthetic patient generator that creates realistic patient data and associated medical records that can be used for testing healthcare software applications. To learn more about Pydeequ as a data testing framework, see Testing Data quality at scale with Pydeequ. onData(df).useRepository(metricsRepository).addCheck(
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it straightforward and cost-effective to analyze all your data using standard SQL and your existing extract, transform, and load (ETL); business intelligence (BI); and reporting tools. Add any necessary tags to the instance.
Developers need to understand the application APIs, write implementation and test code, and maintain the code for future API changes. Optionally, provide a description for the flow and tags. Test the solution Log in to your Salesforce account, and edit any record in the Account object. Choose Create flow. Choose Next.
It’s obvious that the manual road is very challenging to discover and synthesize data that resides in different formats in thousands of unharvested, undocumented databases, applications, ETL processes and procedural code.
In order to mature our data marts, it became clear that we needed to provide Analysts and other data consumers with all tracked digital analytics data in our DWH as they depend on it for analyses, reporting, campaign evaluation, product development and A/B testing. We made sure to add appropriate tags for cost monitoring.
This data transformation tool enables data analysts and engineers to transform, test and document data in the cloud data warehouse. First, we pulled unique contact titles into a Google Sheet from Hubspot and other sources, and tagged them with internal attributes; this helps downstream analysts get work done.
But social extends even further; it includes the comments users make, assets they flag as favorites, the watches they set on assets, who they tag and how, and their level of expertise. People often use the same data sources, so capturing knowledge about that usage, (including their role, team, and expertise), layers on important context.
The data engineering team owns the extract, transform, and load (ETL) application that will process the raw data to create and maintain the Iceberg tables. The ETL application will use IAM role-based access to the Iceberg table, and the data analyst gets Lake Formation permissions to query the same tables. Choose Grant.
Built-in zero-ETL connectors reduce data silos by integrating various data sources, enabling unified analytics across teams. Under LF-Tags or catalog resources , select Named Data Catalog resources. The Lake Formation admin verifies that the shared resources are accessible by running test queries in Athena. Choose Grant.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content