This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. These activities translate into the ability to run append, insert, update, and delete operations. Data management is the foundation of quantitative research.
Primary among these is the need to ensure the data that will power their AI strategies is fit for purpose. Primary among these is the need to ensure the data that will power their AI strategies is fit for purpose. In fact, a data framework is critical first step for AI success.
This is where activemetadata comes in. Listen to “Why is ActiveMetadata Management Essential?” What is ActiveMetadata? The post The Power of ActiveMetadata appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information.
Amazon Redshift is a fully managed, AI-powered cloud data warehouse that delivers the best price-performance for your analytics workloads at any scale. It enables you to get insights faster without extensive knowledge of your organization’s complex database schema and metadata. Within this feature, user data is secure and private.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Key recommendations include investing in AI-powered cleansing tools and adopting federated governance models that empower domains while ensuring enterprise alignment.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed data lake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
OpenSearch Ingestion is a serverless pipeline that provides powerful tools for extracting, transforming, and loading data into an OpenSearch Service domain. You can use this approach for a variety of use cases, from real-time log analytics to integrating application messaging data for real-time search.
Amazon SageMaker Lakehouse unifies all your data across Amazon S3 data lakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. In addition, organizations rely on an increasingly diverse array of digital systems, data fragmentation has become a significant challenge.
Solution overview To illustrate the new Amazon Bedrock Knowledge Bases integration with structured data in Amazon Redshift, we will build a conversational AI-powered assistant for financial assistance that is designed to help answer financial inquiries, like Who has the most accounts?
In this context, the adoption of data lakes and the data mesh framework emerges as a powerful approach. In this context, the adoption of data lakes and the data mesh framework emerges as a powerful approach. Data is the most significant asset of any organization. At the core of this ecosystem lies the enterprise data platform.
When we analyzed the results , we determined the AI space was in a state of rapid change, so we eagerly commissioned a follow-up survey to help find out where AI stands right now. The new survey, which ran for a few weeks in December 2019, generated an enthusiastic 1,388 responses. There’s a lot to bite into here, so let’s get started.
Like many others, I’ve known for some time that machine learning models themselves could pose security risks. A recent flourish of posts and papers has outlined the broader topic, listed attack vectors and vulnerabilities, started to propose defensive solutions, and provided the necessary framework for this post.
Amazon Redshift is a fast, petabyte-scale, cloud data warehouse that tens of thousands of customers rely on to power their analytics workloads. Many customers have already implemented identity providers (IdPs) like Microsoft Entra ID (formerly Azure Active Directory) for single sign-on (SSO) access across their applications and services.
First, what activemetadata management isn’t : “Okay, you metadata! Now, what activemetadata management is (well, kind of): “Okay, you metadata! Metadata are the details on those tools: what they are, what to use them for, what to use them with. . Quit lounging around! And one – and zero!”.
Organizations need to understand what the most critical operational activities are and the most impactful projects that need to proceed. Where crisis leads to vulnerability, data governance as an emergency service enables organization management to direct or redirect efforts to ensure activities continue and risks are mitigated.
Customer relationship management (CRM) platforms are very reliant on big data. As these platforms become more widely used, some of the data resources they depend on become more stretched. CRM providers need to find ways to address the technical debt problem they are facing through new big data initiatives. What is technical debt anyway?
Whether driving digital experiences, mapping customer journeys, enhancing digital operations, developing digital innovations, finding new ways to interact with customers, or building digital ecosystems or marketplaces – all of this digital transformation is powered by data. Data readiness is everything. The State of Data Automation.
It’s a set of HTTP endpoints to perform operations such as invoking Directed Acyclic Graphs (DAGs), checking task statuses, retrieving metadata about workflows, managing connections and variables, and even initiating dataset-related events, without directly accessing the Airflow web interface or command line tools.
If you’re already a software product manager (PM), you have a head start on becoming a PM for artificial intelligence (AI) or machine learning (ML). You already know the game and how it is played: you’re the coordinator who ties everything together, from the developers and designers to the executives. Why AI software development is different.
Lanier argues that training a model should be a protected activity, but that the output generated by a model can infringe on someone’s copyright. Generative AI stretches our current copyright law in unforeseen and uncomfortable ways. If a human writes software to generate prompts that in turn generate an image, is that copyrightable?
Metadata is the pertinent, practical details about data assets: what they are, what to use them for, what to use them with. Without metadata, data is just a heap of numbers and letters collecting dust. Where does metadata come from? What is a metadata management tool? What are examples of metadata management tools?
Background Multi-AZ with Standby deploys OpenSearch Service domain instances across three Availability Zones, with two zones designated as active and one as standby. During regular operations, the active zone handles coordinator traffic for both read and write requests, as well as shard query traffic.
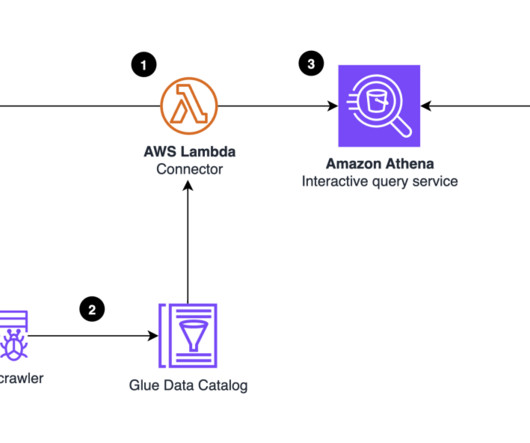
The lineage visualized includes activities inside the Amazon DataZone business data catalog. Lineage captures the assets cataloged as well as the subscribers to those assets and to activities that happen outside the business data catalog captured programmatically using the API.
Relational databases (RDBS) have been the workhorse of ICT for decades. Being able to sit down and define a complete schema, a blueprint of the database, gave everyone assurity and consistency. Sure, you have to ignore the edge cases and hope that they stay edge cases. Surely, business requirements don’t change over time, right?
Iceberg tables maintain metadata to abstract large collections of files, providing data management features including time travel, rollback, data compaction, and full schema evolution, reducing management overhead. Implementing these solutions requires data sharing between purpose-built data stores.
Today’s AI-powered catalogs are more like trusted advisors that work alongside you, anticipating needs and taking initiative. Think of AI copilots as your data expedition partnersthey’re not just answering questions but actively helping you navigate the terrain. Each day, the walls shift and new pathways emerge.
I recently saw an informal online survey that asked users which types of data (tabular, text, images, or “other”) are being used in their organization’s analytics applications. This was not a scientific or statistically robust survey, so the results are not necessarily reliable, but they are interesting and provocative.
Salesforce Data Cloud is a data platform that unifies all of your company’s data into Salesforce’s Einstein 1 Platform , giving every team a 360-degree view of the customer to drive automation, create analytics, personalize engagement, and power trusted artificial intelligence (AI). What is Zero Copy Data Federation?
Experience the power of Business Intelligence with our 14-days free trial! The benefits of business intelligence and analytics are plentiful and varied, but they all have one thing in common: they bring power. Consumers have grown more and more immune to ads that aren’t targeted directly at them.
What is Microsoft’s Common Data Model (CDM), and why is it so powerful? Insights: Given the meaning of the data is the same, regardless of the domain it came from, an organization can use its data to power business insights. It would make your work frustrating, complicated and slow. The CDM takes this concept to the next level.
The zero-copy pattern helps customers map the data from external platforms into the Salesforce metadata model, providing a virtual object definition for that object. The zero-copy pattern helps customers map the data from external platforms into the Salesforce metadata model, providing a virtual object definition for that object. “It
High costs associated with launching campaigns, the security risk of duplicating data, and the time spent on SQL requests have created a demand for a better solution for managing and activating customer data. Organizations are demanding secure, cost efficient, and time efficient solutions to power their marketing outcomes.
For B2B sales and marketing teams, few metaphors are as powerful as the sales funnel. Today, so much online activity has shifted to social media channels, leading to an inescapable conclusion. But the question that matters is, how can you measure and analyze the true impact of social activity on your sales funnel?
This platform is an advanced information retrieval system engineered to assist healthcare professionals and researchers in navigating vast repositories of medical documents, medical literature, research articles, clinical guidelines, protocol documents, activity logs, and more. Evidence generation is rife with knowledge management challenges.
According to erwin’s “2020 State of Data Governance and Automation” report , close to 70 percent of data professional respondents say they spend an average of 10 or more hours per week on data-related activities, and most of that time is spent searching for and preparing data. Doing Data Lineage Right. Faster Business Turnaround.
We split the solution into two primary components: generating Spark job metadata and running the SQL on Amazon EMR. The first component (metadata setup) consumes existing Hive job configurations and generates metadata such as number of parameters, number of actions (steps), and file formats.
These include internet-scale web and mobile applications, low-latency metadata stores, high-traffic retail websites, Internet of Things (IoT) and time series data, online gaming, and more. Table metadata, such as column names and data types, is stored using the AWS Glue Data Catalog. You don’t need to write any code.
As someone who is passionate about the transformative power of technology, it is fascinating to see intelligent computing – in all its various guises – bridge the schism between fantasy and reality. The excitement is palpable. This first article emphasizes data as the ‘foundation-stone’ of AI-based initiatives. Establishing a Data Foundation.
Today, this is powering every part of the organization, from the customer-favorite online cake customization feature to democratizing data to drive business insight. Today, this is powering every part of the organization, from the customer-favorite online cake customization feature to democratizing data to drive business insight.
Foundation models are a class of very powerful AI models that can be used as the basis for other models: they can be specialized, or retrained, or otherwise modified for specific applications. What is it, how does it work, what can it do, and what are the risks of using it? It has helped to write a book. Or a text adventure game.
Knowledge graphs (KG) came later, but quickly became a powerful driver for adoption of Semantic Web standards and all species of semantic technology implementing them. Knowledge graphs (KG) came later, but quickly became a powerful driver for adoption of Semantic Web standards and all species of semantic technology implementing them.
This is where the true power of complete data observability comes into play, and it’s time to get acquainted with its two critical parts: ‘Data in Place’ and ‘Data in Use.’ Complaints from dissatisfied customers and apathetic data providers only add to the mounting stress. One of the primary sources of tension?
This option provides improved reliability and the added benefit of simplifying cluster configuration and management by enforcing best practices and reducing complexity. In this post, we share how Multi-AZ with Standby works under the hood to achieve high resiliency and consistent performance to meet the four 9s. This approach was reactive at best.
In this blog post, we compare Cloudera Data Warehouse (CDW) on Cloudera Data Platform (CDP) using Apache Hive-LLAP to Microsoft HDInsight (also powered by Apache Hive-LLAP) on Azure using the TPC-DS 2.9 Once the benchmark run has completed, the Virtual Warehouse automatically suspends itself when no further activity is detected.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content