This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
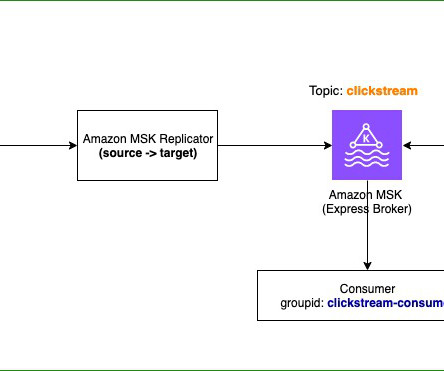
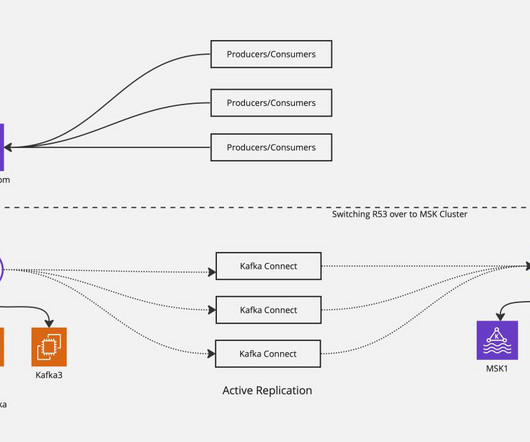
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is deployed across multiple Availability Zones and provides resilience within an AWS Region. This post explains how to use MSK Replicator for cross-cluster data replication and details the failover and failback processes while keeping the same topic name across Regions.
Amazon Kinesis Data Analytics for SQL is a data stream processing engine that helps you run your own SQL code against streaming sources to perform time series analytics, feed real-time dashboards, and create real-time metrics. Customers running SQL queries typically select Amazon Managed Service for Apache Flink Studio.
Introduction “Data Science” and “Machine Learning” are prominent technological topics in the 25th century. They are utilized by various entities, ranging from novice computer science students to major organizations like Netflix and Amazon.
Introduction Amazon Simple Notification Service (SNS) is a managed service that delivers messages from publishers to subscribers (also known as producers and consumers). Publishers communicate asynchronously by sending messages on a topic that serves as a logical access point and communication route for […].
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that allows you to build and run production Kafka applications. At the heart of this ecosystem lies Kafka, specifically Amazon MSK, which serves as the backbone for their data integration systems.
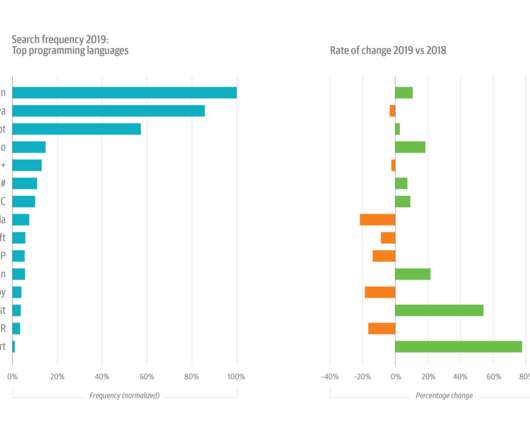
O’Reilly online learning contains information about the trends, topics, and issues tech leaders need to watch and explore. It’s also the data source for our annual usage study, which examines the most-used topics and the top search terms. [1]. Up until 2017, the ML+AI topic had been amongst the fastest growing topics on the platform.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
We’re thrilled to announce the launch of the official Amazon OpenSearch Service YouTube channel —a comprehensive resource for anyone looking to master Amazon OpenSearch Service. Amazon OpenSearch Service is a managed service that makes it straightforward to deploy, operate, and scale OpenSearch domains in AWS.
Amazon OpenSearch Service launches a modernized operational analytics experience that can provide comprehensive observability spanning multiple data sources , so that you can gain insights from OpenSearch and other integrated data sources in one place. You can add collaborators by their IAM Amazon Resource Name (ARN) or IDC username.
REA Group, a digital business that specializes in real estate property, solved this problem using Amazon Managed Streaming for Apache Kafka (Amazon MSK) and a data streaming platform called Hydro. REA Group’s team of more than 3,000 people is guided by our purpose: to change the way the world experiences property.
Amazon Managed Streaming for Apache Kafka (Amazon MSK) now offers a new broker type called Express brokers. To learn more about Express brokers, refer to Introducing Express brokers for Amazon MSK to deliver high throughput and faster scaling for your Kafka clusters.
In this post, we show how to use Amazon Kinesis Data Streams to buffer and aggregate real-time streaming data for delivery into Amazon OpenSearch Service domains and collections using Amazon OpenSearch Ingestion. For the Amazon S3 log use case, see Using an OpenSearch Ingestion pipeline with Amazon S3.
Infor introduced its original AI and machine learning capabilities in 2017 in the form of Coleman, which uses its Infor AI/ML platform built on Amazon’s SageMaker to create predictive and prescriptive analytics. It also offered a chatbot that utilized Amazon Lex.
Large-scale production recommenders, search engines, and other discovery processes also have a long history of leveraging knowledge graphs , such as at Amazon , Alphabet , Microsoft , LinkedIn , eBay , Pinterest , and so on. What is GraphRAG? Graph technologies help reveal nonintuitive connections within data.
Amazon Redshift Serverless is a fully managed, scalable cloud data warehouse that accelerates your time to insights with fast, simple, and secure analytics at scale. Amazon Redshift data sharing allows you to share data within and across organizations, AWS Regions, and even third-party providers, without moving or copying the data.
These businesses include eBay, Autotrader, and Amazon. In other words, “Sams Teach Yourself SQL in 10 Minutes” teaches the parts of SQL you need to know: starting with simple data retrieval and quickly going on to more complex topics including the use of SQL joins , subqueries, stored procedures, cursors, triggers, and table constraints.
Since the launch of tiered storage for Amazon Managed Streaming for Apache Kafka (Amazon MSK), customers have embraced this feature for its ability to optimize storage costs and improve performance. New messages are initially written to Amazon EBS for fast performance. This frees up space on the EBS volumes for new messages.
User stakeholders are interested in benefiting from the platform’s functionality: staying up-to-date, quickly finding new people and topics to follow, and engaging with family and friends. Customer stakeholders are the people and companies that advertise on the platform, and are most concerned with ROI on their ad spend.
to Amazon Managed Streaming for Apache Kafka (Amazon MSK) running version 2.6.2. Why we migrated to Amazon MSK For us, migrating to Amazon MSK came down to three key decision points: Simplified technical operations – Running Kafka on a self-managed infrastructure was an operational overhead for us.
Jacknis advises CIOs to focus on the three reasons why AI is such a hot topic. AI bias has already got organizations such as online retailer Amazon into hot water, and here again, the CIO must play a pivotal role in protecting the business. It’s back to Moore’s Law. We’ve already seen that AI depends on a lot of compute power.
With OpenSearch UI, you can have a unified interface to gain actionable insights across multiple data sources, including Amazon OpenSearch Service domains , Amazon OpenSearch Serverless collections , and AWS services such as Amazon CloudWatch and Amazon Security Lake.
AWS helps SaaS vendors by providing the building blocks needed to implement a streaming application with Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK), and real-time processing applications with Amazon Managed Service for Apache Flink. In particular, we focus on Amazon MSK.
Ingesting a high volume of streaming data has been a defining characteristic of operational analytics workloads with Amazon OpenSearch Service. Many of these workloads involve either self-managed Apache Kafka or Amazon Managed Streaming for Apache Kafka (Amazon MSK) to satisfy their data streaming needs.
The resource examples I’ll cite will be drawn from the upcoming Strata Data conference in San Francisco , where leading companies and speakers will share their learnings on the topics covered in this post. AI and machine learning in the enterprise. Security and Privacy.
A mere Amazon search of this topic returns over 15k items. Though printed in 1983, it remains a classic and a bestseller on Amazon. Boasting near flawless reader reviews on Amazon, this graphically-driven book on data visualization makes an excellent companion when it comes to thriving in the digital age.
Towards the end of 2022, AWS announced the general availability of real-time streaming ingestion to Amazon Redshift for Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK) , eliminating the need to stage streaming data in Amazon Simple Storage Service (Amazon S3) before ingesting it into Amazon Redshift.
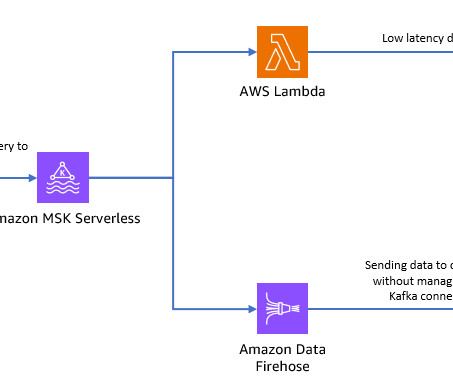
AWS offers multiple serverless services like Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Data Firehose , Amazon DynamoDB , and AWS Lambda that scale automatically depending on your needs. Create a serverless Kafka cluster on Amazon MSK We use Amazon MSK to ingest real-time telemetry data from modems.
I’m personally interested in this topic since I am a professor who researches human-computer interaction, user experience design, and cognitive science , so AI voice interfaces are fascinating to me. That in turn got me curious about the concept of syndication in the television business, so ChatGPT dived more into this topic.
In this post, we will describe how and why we decided to migrate from self-managed Kafka to Amazon Managed Streaming for Apache Kafka ( Amazon MSK ). We’ll start with an overview of our self-managed Kafka, why we chose to migrate to Amazon MSK, and ultimately how we did it. in “newkafka.”
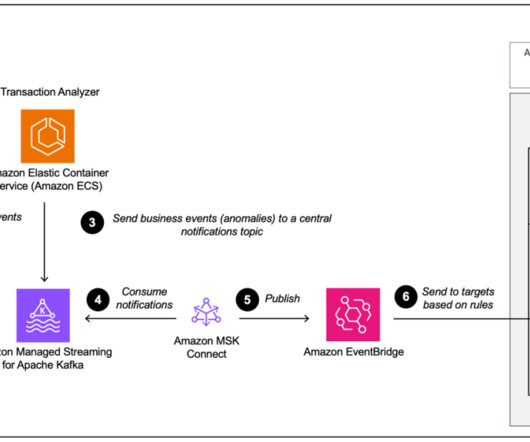
In EDAs, modern event brokers, such as Amazon EventBridge and Apache Kafka, play a key role to publish and subscribe to events. There are two ways to send events from Apache Kafka to EventBridge: the preferred method using Amazon EventBridge Pipes or the EventBridge sink connector for Kafka Connect.
In this post, we provide a detailed overview of streaming messages with Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon ElastiCache for Redis , covering technical aspects and design considerations that are essential for achieving optimal results. The following figure shows an example of the data flow at SOCAR.
The AWS Identity and Access Management (IAM) authentication feature in Amazon Managed Streaming for Apache Kafka (Amazon MSK) now supports all programming languages. Both Amazon MSK provisioned and serverless cluster types support the new Amazon MSK IAM expansion to all programming languages.
This post showcases how to use streaming ingestion to bring data to Amazon Redshift. It’s simple to set up, and directly ingests streaming data into your data warehouse from Amazon Kinesis Data Streams and Amazon Managed Streaming for Kafka ( Amazon MSK ) without the need to stage in Amazon Simple Storage Service (Amazon S3).
The hosted by Christopher Bergh with Gil Benghiat from DataKitchen covered a comprehensive range of topics centered around improving the performance and efficiency of data teams through Agile and DataOps methodologies.
dbt enables you to write SQL select statements, and then it manages turning these select statements into tables or views in Amazon Redshift. Queues and topics – Queues and topics come from various integration applications that generate data in real time.
Amazon Redshift , a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables.
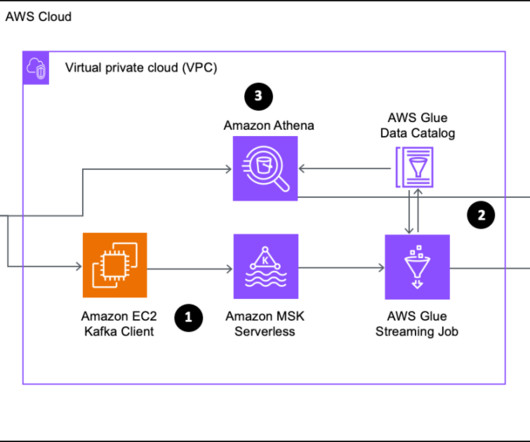
To address these issues effectively, we propose using Amazon Managed Streaming for Apache Kafka (Amazon MSK), a fully managed Apache Kafka service that offers a seamless way to ingest and process streaming data. Following the data processing, the streaming job stores data in Amazon S3 and generates a Data Catalog table.
Enterprise customers increasingly adopt Amazon OpenSearch Ingestion (OSI) to bring data into Amazon OpenSearch Service for various use cases. These sources can either be on Amazon Elastic Compute Cloud (Amazon EC2) or on-premises environments. Name resolution for data sources – OSI uses an Amazon Route 53 resolver.
In this post, Nexthink shares how Amazon Managed Streaming for Apache Kafka (Amazon MSK) empowered them to achieve massive scale in event processing. With Amazon MSK, Nexthink now seamlessly processes trillions of events per day, reaching over 5 GB per second of aggregated throughput.
Organizations are adopting Apache Kafka and Amazon Managed Streaming for Apache Kafka (Amazon MSK) to capture and analyze data in real time. Since its inception, Apache Kafka has depended on Apache Zookeeper for storing and replicating the metadata of Kafka brokers and topics. Starting from Apache Kafka version 3.3,
Amazon’s serverless Apache Kafka offering, Amazon Managed Streaming for Apache Kafka (Amazon MSK) Serverless , is attracting a lot of interest. At the time of writing, the Amazon MSK library for IAM is exclusive to Kafka libraries in Java, creating a challenge for users of other programming languages.
This post explains how the underlying infrastructure affects Kafka performance when you use Amazon Managed Streaming for Apache Kafka (Amazon MSK) tiered storage. We delve deep into the core components of Amazon MSK tiered storage and address questions such as: How does read and write work in a tiered storage-enabled cluster?
Managing configurations for Amazon MSK Connect , a feature of Amazon Managed Streaming for Apache Kafka (Amazon MSK), can become challenging, especially as the number of topics and configurations grows. The challenges lie in the overhead of managing configurations, as well as dealing with patching and upgrades.
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed Apache Kafka service. For more information about using IAM authentication, refer to Securely process near-real-time data from Amazon MSK Serverless using an AWS Glue streaming ETL job with IAM authentication. Create a Kafka connection in AWS Glue.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content