This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
Amazon Redshift is a fast, fully managed petabyte-scale cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing businessintelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
One-time and complex queries are two common scenarios in enterprise data analytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. file, enter the preprocessing code for the raw lineage data.
With this integration, you can now seamlessly query your governed datalake assets in Amazon DataZone using popular businessintelligence (BI) and analytics tools, including partner solutions like Tableau. Refer to the detailed blog post on how you can use this to connect through various other tools.
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your datalake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable).
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other businessdata, as well as support the use of businessintelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications.
AWS Glue provides an extensible architecture that enables users with different data processing use cases. A common use case is building datalakes on Amazon Simple Storage Service (Amazon S3) using AWS Glue extract, transform, and load (ETL) jobs. AWS Glue version Hudi Delta Lake Iceberg AWS Glue 3.0 AWS Glue 4.0
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing businessintelligence (BI) tools. The S3 object path can reference a set of folders that have the same key prefix.
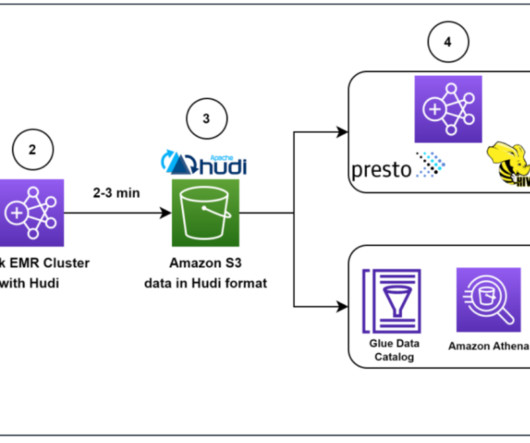
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. Apache Hudi connector for AWS Glue For this post, we use AWS Glue 4.0,
By collecting data from store sensors using AWS IoT Core , ingesting it using AWS Lambda to Amazon Aurora Serverless , and transforming it using AWS Glue from a database to an Amazon Simple Storage Service (Amazon S3) datalake, retailers can gain deep insights into their inventory and customer behavior.
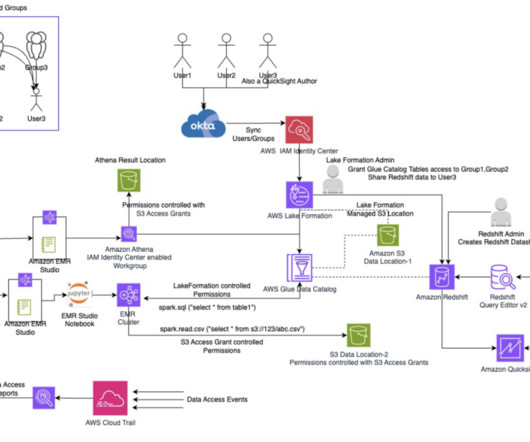
Refer to Configure SAML and SCIM with Okta and IAM Identity Center for instructions. You need to reference the bucket name and the certificate bundle.zip file in AWS CloudFormation. Refer to the following table for a list of important parameters. In this post, we use the us-east-1 Region. In this post, we grant access to Group1.
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build data warehouses and datalakes based on operational data.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the datalake using various cloud services like Amazon’s S3 and others. It will enable you to quickly transform and load the data results into Amazon S3 datalakes or JDBC data stores.
The product data is stored on Amazon Aurora PostgreSQL-Compatible Edition. Their existing businessintelligence (BI) tool runs queries on Athena. Furthermore, they have a data pipeline to perform extract, transform, and load (ETL) jobs when moving data from the Aurora PostgreSQL database cluster to other data stores.
Several large organizations have faltered on different stages of BI implementation, from poor data quality to the inability to scale due to larger volumes of data and extremely complex BI architecture. This is where businessintelligence consulting comes into the picture. What is BusinessIntelligence?
Several large organizations have faltered on different stages of BI implementation, from poor data quality to the inability to scale due to larger volumes of data and extremely complex BI architecture. This is where businessintelligence consulting comes into the picture. What is BusinessIntelligence?
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse service that makes it simple and cost-effective to efficiently analyze all your data using your existing businessintelligence (BI) tools. The Amazon Redshift service must be running in the same Region where the Salesforce Data Cloud is running.
If you’re used to using SQL Server Analysis Services for businessintelligence, Analysis Services offers that enterprise-grade analytics engine as a cloud service that you can also connect to Power BI. Azure DataLake Analytics. The reason Azure has so many analytics services is so you can build your entire stack there.
With this platform, Salesforce seeks to help organizations apply the cleverness of LLMs to the customer data they have squirreled away in Salesforce datalakes in the hopes of selling more. Einstein 1 Studio handles the piping so the data from your Einstein 1 platform instance will flow smoothly into the AI.
We have seen a strong customer demand to expand its scope to cloud-based datalakes because datalakes are increasingly the enterprise solution for large-scale data initiatives due to their power and capabilities. The team uses dbt-glue to build a transformed gold model optimized for businessintelligence (BI).
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning (ML), and application development. Apache Hudi supports ACID transactions and CRUD operations on a datalake. You don’t alter queries separately in the datalake.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud data warehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing businessintelligence tools.
Many of the existing visual businessintelligence and dashboard tools also use SQL as a standard language. Democratizing datarefers to a mechanism that provides a self-serve paradigm and culture for an ever-growing internal audience to get the data they need to add value to the business.
Flexible and easy to use – The solutions should provide less restrictive, easy-to-access, and ready-to-use data. A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users.
The term “ businessintelligence ” (BI) has been in common use for several decades now, referring initially to the OLAP systems that drew largely upon pre-processed information stored in data warehouses. As the cost benefit ratio of BI has become more and more attractive, the pace of global business has also accelerated.
For instance, a Data Cloud-triggered flow could update an account manager in Slack when shipments in an external datalake are marked as delayed. Sharing Customer 360 insights back without data replication. With zero-copy support, the insurance company wouldn’t have to load that weather data into their platform.
Today, tens of thousands of customers run business-critical workloads on Amazon Redshift to cost-effectively and quickly analyze their data using standard SQL and existing businessintelligence (BI) tools. Change the settings for existing Data Catalog resources.
Which type(s) of storage consolidation you use depends on the data you generate and collect. . One option is a datalake—on-premises or in the cloud—that stores unprocessed data in any type of format, structured or unstructured, and can be queried in aggregate. Set up unified data governance rules and processes.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. Additionally, data is extracted from vendor APIs that includes data related to product, marketing, and customer experience.
Data architect Armando Vázquez identifies eight common types of data architects: Enterprise data architect: These data architects oversee an organization’s overall data architecture, defining data architecture strategy and designing and implementing architectures.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
Figure 2: Example data pipeline with DataOps automation. In this project, I automated data extraction from SFTP, the public websites, and the email attachments. The automated orchestration published the data to an AWS S3 DataLake. Historic Balance – compares current data to previous or expected values.
To visualize data stored in Confluent, you can use one of over 120 pre-built connectors, provided by Confluent, to write streaming data to a destination data store of your choice. Next, you connect your businessintelligence (BI) tool to the data store to begin visualizing the data.
Application log challenges: Data management and compliance Application logs are an essential component of any application; they provide valuable information about the usage and performance of the system. Zoom and the AWS team (collectively referred to as “the team” going forward) identified two major workflows for data ingestion and deletion.
By using AWS Glue to integrate data from Snowflake, Amazon S3, and SaaS applications, organizations can unlock new opportunities in generative artificial intelligence (AI) , machine learning (ML) , businessintelligence (BI) , and self-service analytics or feed data to underlying applications. Choose Next.
To create your namespace and workgroup, refer to Creating a data warehouse with Amazon Redshift Serverless. Use Query Editor v2 to load customer data from Amazon S3 You can use Query Editor v2 to submit queries and load data to your data warehouse through a web interface.
You can extend the solution in directions such as the businessintelligence (BI) domain with customer 360 use cases, and the risk and compliance domain with transaction monitoring and fraud detection use cases. The application gets prompt templates from an S3 datalake and creates the engineered prompt.
They can connect to multiple data streams and pull data directly into Amazon Redshift without staging it in Amazon Simple Storage Service (Amazon S3). After running analytics, the insights can be made available broadly across the organization with Amazon QuickSight , a cloud-native, serverless businessintelligence service.
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
With Amazon EMR, you can take advantage of the power of these big data tools to process, analyze, and gain valuable businessintelligence from vast amounts of data. Refer to How do I set up a NAT gateway for a private subnet in Amazon VPC? For more information, refer to Prerequisites. manylinux2014_x86_64.whl
If after anonymization the level of information in the data is the same, the data is still useful. But once personal or sensitive references are removed, and the data is no longer effective, a problem arises. Synthetic data avoids these difficulties, but they’re not exempt from the need of a trade-off.
It automatically provisions and intelligently scales data warehouse compute capacity to deliver fast performance, and you pay only for what you use. Just load your data and start querying right away in the Amazon Redshift Query Editor or in your favorite businessintelligence (BI) tool.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content