This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now, instead of making a direct call to the underlying database to retrieve information, a report must query a so-called “data entity” instead. Each data entity provides an abstract representation of businessobjects within the database, such as, customers, general ledger accounts, or purchase orders. DataLakes.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. The following diagram illustrates this architecture.
The new table needs to be refreshed periodically to get the latest data from the shared Data Cloud objects with this solution. Considerations when using data sharing in Amazon Redshift For a comprehensive list of considerations and limitations of data sharing, refer to Considerations when using data sharing in Amazon Redshift.
Data can be shared with a Redshift Serverless or provisioned cluster in the same Region or with a Redshift Serverless cluster in a different Region. To get an overview of Salesforce Zero Copy integration with Amazon Redshift, please refer to this Salesforce Blog. For more details, refer to Querying the AWS Glue Data Catalog.
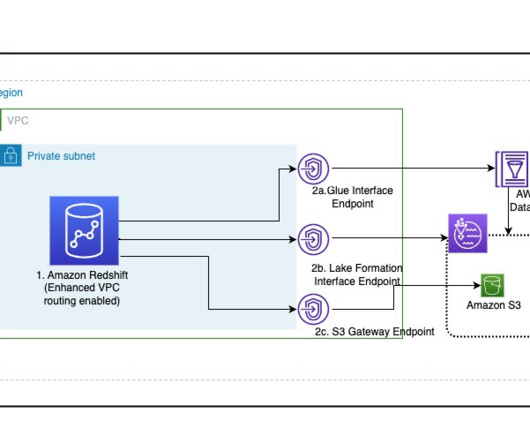
Many customers are extending their data warehouse capabilities to their datalake with Amazon Redshift. They are looking to further enhance their security posture where they can enforce access policies on their datalakes based on Amazon Simple Storage Service (Amazon S3). Choose Create endpoint.
With SageMaker Lakehouse unified data connectivity, you can confidently connect, explore, and unlock the full value of your data across AWS services and achieve your businessobjectives with agility. This new capability can simplify your data journey. To learn more, refer to Amazon SageMaker Unified Studio.
With that in mind, the agency uses open-source technology and high-performance hybrid cloud infrastructure to transform how it processes demographic and economic data with an Enterprise DataLake (EDL). This confidence and trust is key to enabling them to use data to its fullest potential and generating business value. .
This post also discusses the art of the possible with newer innovations in AWS services around streaming, machine learning (ML), data sharing, and serverless capabilities. Flexible and easy to use – The solutions should provide less restrictive, easy-to-access, and ready-to-use data. Data repositories represent the hub.
Customers often face challenges in locating and accessing the fragmented data they need, expending time and resources in the process. For instructions on ingesting metadata for AWS Glue tables, refer to Create and run an Amazon DataZone data source for the AWS Glue Data Catalog. Choose Add terms under GLOSSARY TERMS.
For more information, refer to Setting up AWS Identity and Access Management (IAM) permissions. Create an S3 bucket for the project and create a folder to upload the raw input data. Prerequisites For this walkthrough, you should have the following prerequisites: An AWS account.
Depending on your enterprise’s culture and goals, your migration pattern of a legacy multi-tenant data platform to Amazon Redshift could use one of the following strategies: Leapfrog strategy – In this strategy, you move to an AWS modern data architecture and migrate one tenant at a time. Vijay Bagur is a Sr. Technical Account Manager.
It is prudent to consolidate this data into a single customer view, serving as a primary reference for downstream applications, ranging from ecommerce platforms to CRM systems. This consolidated view acts as a liaison between the data platform and customer-centric applications.
Business Intelligence (BI) encompasses a wide variety of tools, applications and methodologies that enable organizations to collect data from internal systems and external sources, process it and deliver it to business users in a format that is easy to understand and provides the context needed for informed decision making.
Business Intelligence (BI) encompasses a wide variety of tools, applications and methodologies that enable organizations to collect data from internal systems and external sources, process it and deliver it to business users in a format that is easy to understand and provides the context needed for informed decision making.
This has led to the emergence of real-time OLAP solutions, which are particularly relevant in the following use cases: User-facing analytics – Incorporating analytics into products or applications that consumers use to gain insights, sometimes referred to as data products.
For instructions on installing Keycloak, refer to Keycloak Downloads. To perform these steps, refer to Configure an automated email sync for federated SSO users to access Amazon QuickSight. Vamsi Bhadriraju is a Data Architect at AWS. Sign in to your Keycloak admin dashboard. For the Keycloak admin dashboard, use [link].
The reasons for this are simple: Before you can start analyzing data, huge datasets like datalakes must be modeled or transformed to be usable. According to a recent survey conducted by IDC , 43% of respondents were drawing intelligence from 10 to 30 data sources in 2020, with a jump to 64% in 2021!
For details about best practices, refer to Enable private access to Amazon Redshift from your client applications in another VPC. Navigate to the Salesforce Data Cloud setup and wait 30 seconds, then refresh the private connect route so the status shows as Ready. For additional details, refer to Part 1 of this series.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content