This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalakeanalytics, machine learning (ML), and data monetization.
Amazon Redshift has established itself as a highly scalable, fully managed cloud data warehouse trusted by tens of thousands of customers for its superior price-performance and advanced dataanalytics capabilities. This allows you to maintain a comprehensive view of your data while optimizing for cost-efficiency.
Many organizations operate datalakes spanning multiple cloud data stores. In these cases, you may want an integrated query layer to seamlessly run analytical queries across these diverse cloud stores and streamline your dataanalytics processes. Refer to the respective documentation for details.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. Apache Iceberg integration is supported by AWS analytics services including Amazon EMR , Amazon Athena , and AWS Glue. AWS Glue 3.0
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
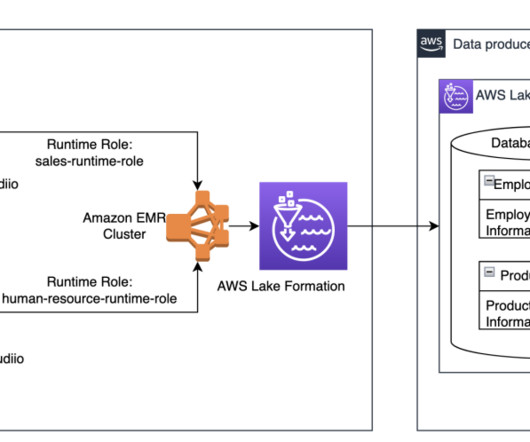
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters.
Amazon SageMaker Unified Studio (preview) provides a unified experience for using data, analytics, and AI capabilities. You can use familiar AWS services for model development, generative AI, data processing, and analyticsall within a single, governed environment. Refer to the appendix at the end of this post for more details.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
Organizations have chosen to build datalakes on top of Amazon Simple Storage Service (Amazon S3) for many years. A datalake is the most popular choice for organizations to store all their organizational data generated by different teams, across business domains, from all different formats, and even over history.
That stands for “bring your own database,” and it refers to a model in which core ERP data are replicated to a separate standalone database used exclusively for reporting. Option 3: Azure DataLakes. This leads us to Microsoft’s apparent long-term strategy for D365 F&SCM reporting: Azure DataLakes.
One-time and complex queries are two common scenarios in enterprise dataanalytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. file, enter the preprocessing code for the raw lineage data.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
We refer to this role as TheSnapshotRole in this post. For instructions, refer to the earlier section in this post. For instructions, refer to the earlier section in this post. Samir works directly with enterprise customers to design and build customized solutions catered to their dataanalytics and cybersecurity needs.
Refer to Easy analytics and cost-optimization with Amazon Redshift Serverless to get started. It can help optimize the generation process by reducing unnecessary table references. The public.set_translations table contains the data sufficient to answer the question. For this post, we use Redshift Serverless.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
This post explores how you can use BladeBridge , a leading data environment modernization solution, to simplify and accelerate the migration of SQL code from BigQuery to Amazon Redshift. Tens of thousands of customers use Amazon Redshift every day to run analytics, processing exabytes of data for business insights.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. Search for the Jira Cloud connector.
Amazon Kinesis DataAnalytics makes it easy to transform and analyze streaming data in real time. In this post, we discuss why AWS recommends moving from Kinesis DataAnalytics for SQL Applications to Amazon Kinesis DataAnalytics for Apache Flink to take advantage of Apache Flink’s advanced streaming capabilities.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Dataanalytics on operational data at near-real time is becoming a common need. Then we can query the data with Amazon Athena visualize it in Amazon QuickSight.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Traditional batch ingestion and processing pipelines that involve operations such as data cleaning and joining with referencedata are straightforward to create and cost-efficient to maintain.
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. To learn more, refer to Amazon Q data integration in AWS Glue. About the Authors Bo Li is a Senior Software Development Engineer on the AWS Glue team.
By collecting data from store sensors using AWS IoT Core , ingesting it using AWS Lambda to Amazon Aurora Serverless , and transforming it using AWS Glue from a database to an Amazon Simple Storage Service (Amazon S3) datalake, retailers can gain deep insights into their inventory and customer behavior.
Apache Iceberg is an open table format for very large analytic datasets. It manages large collections of files as tables, and it supports modern analyticaldatalake operations such as record-level insert, update, delete, and time travel queries. Mikhail specializes in dataanalytics services.
These services enable you to collect and analyze data in near real time and put a comprehensive data governance framework in place that uses granular access control to secure sensitive data from unauthorized users. To create an AWS HealthLake data store, refer to Getting started with AWS HealthLake.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Create a report on Google Analytics. Refer to the Amazon Redshift Database Developer Guide for more details.
New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for datalake, data warehouse, and machine learning use cases. If you’re new to Amazon DataZone, refer to Getting started.
AWS-powered datalakes, supported by the unmatched availability of Amazon Simple Storage Service (Amazon S3), can handle the scale, agility, and flexibility required to combine different data and analytics approaches. For more information, refer to Amazon S3: Allows read and write access to objects in an S3 Bucket.
However, computerization in the digital age creates massive volumes of data, which has resulted in the formation of several industries, all of which rely on data and its ever-increasing relevance. Dataanalytics and visualization help with many such use cases. It is the time of big data. What Is DataAnalytics?
You can attach an EMR Studio Workspace to an EMR cluster, and use the compute power of the EMR cluster and run data science jobs on the cluster. Data is often stored in datalakes managed by AWS Lake Formation , enabling you to apply fine-grained access control through a simple grant or revoke mechanism.
We have defined all layers and components of our design in line with the AWS Well-Architected Framework DataAnalytics Lens. Ingestion: Datalake batch, micro-batch, and streaming Many organizations land their source data into their datalake in various ways, including batch, micro-batch, and streaming jobs.
Lately, the concept of data experience has been gaining attention in discussions around the enterprise data stack. As the name suggests, it refers to how people interact with data in enterprise settings. Due to fragmented data setups in these companies, their datalakes have the following characteristics:
The rapid adoption of software as a service (SaaS) solutions has led to data silos across various platforms, presenting challenges in consolidating insights from diverse sources. This solution also allows you to update certain fields of the account object in the datalake and push it back to Salesforce.
Though you may encounter the terms “data science” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
And as businesses contend with increasingly large amounts of data, the cloud is fast becoming the logical place where analytics work gets done. For many enterprises, Microsoft Azure has become a central hub for analytics. Azure Data Explorer. Azure DataLakeAnalytics.
In the dataanalytics space, organizations often deal with many tables in different databases and file formats to hold data for different business functions. Apache Hudi supports ACID transactions and CRUD operations on a datalake. For instructions to set up Aurora, refer to Creating an Amazon Aurora DB cluster.
The term “dataanalytics” refers to the process of examining datasets to draw conclusions about the information they contain. Data analysis techniques enhance the ability to take raw data and uncover patterns to extract valuable insights from it. Dataanalytics is not new.
I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or Data Science. Today we have had over 20,000 signatures , millions of page views, and copycat clones, and it is frequently used as a reference guide. It’s Customer Journey for dataanalytic systems.
To provide a response that includes the enterprise context, each user prompt needs to be augmented with a combination of insights from structured data from the data warehouse and unstructured data from the enterprise datalake. For more information, refer to Encryption at rest and Protecting data using encryption.
To enable this use case, we used the BMW Group’s cloud-native data platform called the Cloud Data Hub. In 2019, the BMW Group decided to re-architect and move its on-premises datalake to the AWS Cloud to enable data-driven innovation while scaling with the dynamic needs of the organization.
To learn more about RAG, refer to Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart. A RAG-based generative AI application can only produce generic responses based on its training data and the relevant documents in the knowledge base.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content