This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Dataarchitecture has evolved significantly to handle growing data volumes and diverse workloads. For more examples and references to other posts, refer to the following GitHub repository.
Amazon Redshift enables you to directly access data stored in Amazon Simple Storage Service (Amazon S3) using SQL queries and join data across your data warehouse and datalake. With Amazon Redshift, you can query the data in your S3 datalake using a central AWS Glue metastore from your Redshift data warehouse.
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern dataarchitecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
They understand that a one-size-fits-all approach no longer works, and recognize the value in adopting scalable, flexible tools and open data formats to support interoperability in a modern dataarchitecture to accelerate the delivery of new solutions.
The Analytics specialty practice of AWS Professional Services (AWS ProServe) helps customers across the globe with modern dataarchitecture implementations on the AWS Cloud. Of those tables, some are larger (such as in terms of record volume) than others, and some are updated more frequently than others.
A modern dataarchitecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
SageMaker still includes all the existing ML and AI capabilities you’ve come to know and love for data wrangling, human-in-the-loop data labeling with Amazon SageMaker Ground Truth , experiments, MLOps, Amazon SageMaker HyperPod managed distributed training, and more. The tools to transform your business are here.
In the current industry landscape, datalakes have become a cornerstone of modern dataarchitecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters.
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern dataarchitectures.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
Organizations have chosen to build datalakes on top of Amazon Simple Storage Service (Amazon S3) for many years. A datalake is the most popular choice for organizations to store all their organizational data generated by different teams, across business domains, from all different formats, and even over history.
Tens of thousands of customers use Amazon Redshift every day to run analytics, processing exabytes of data for business insights. times better price performance than other cloud data warehouses. For more details, refer to the BladeBridge Analyzer Demo. Amazon Redshift is built for scale and delivers up to 7.9
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
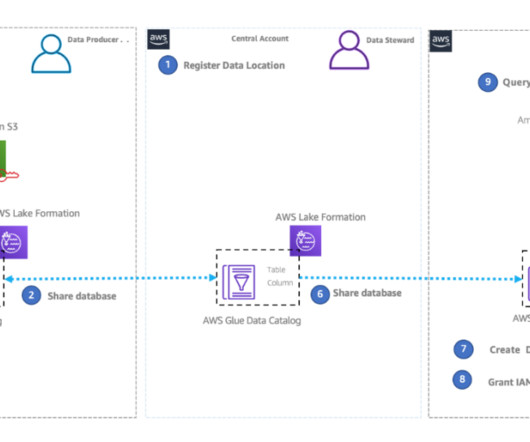
This leads to having data across many instances of data warehouses and datalakes using a modern dataarchitecture in separate AWS accounts. We recently announced the integration of Amazon Redshift data sharing with AWS Lake Formation. Take note of this role’s ARN to use later in the steps.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
Automate ingestion from a single data source With a auto-copy job, you can automate ingestion from a single data source by creating one job and specifying the path to the S3 objects that contain the data. The S3 object path can reference a set of folders that have the same key prefix.
Dataarchitecture is a complex and varied field and different organizations and industries have unique needs when it comes to their data architects. Solutions data architect: These individuals design and implement data solutions for specific business needs, including data warehouses, data marts, and datalakes.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
This solution only replicates metadata in the Data Catalog, not the actual underlying data. To have a redundant datalake using Lake Formation and AWS Glue in an additional Region, we recommend replicating the Amazon S3-based storage using S3 replication , S3 sync, aws-s3-copy-sync-using-batch or S3 Batch replication process.
We have collected some of the key talks and solutions on data governance, data mesh, and modern dataarchitecture published and presented in AWS re:Invent 2022, and a few datalake solutions built by customers and AWS Partners for easy reference.
Ingestion: Datalake batch, micro-batch, and streaming Many organizations land their source data into their datalake in various ways, including batch, micro-batch, and streaming jobs. Amazon AppFlow can be used to transfer data from different SaaS applications to a datalake.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Compare ongoing data that is replicated from the source on-premises database to the target S3 datalake.
Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake. Data confidentiality and data quality are the two essential themes for data governance.
I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or Data Science. Today we have had over 20,000 signatures , millions of page views, and copycat clones, and it is frequently used as a reference guide. It’s Customer Journey for data analytic systems.
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business. In the navigation pane, under Data catalog , choose Settings.
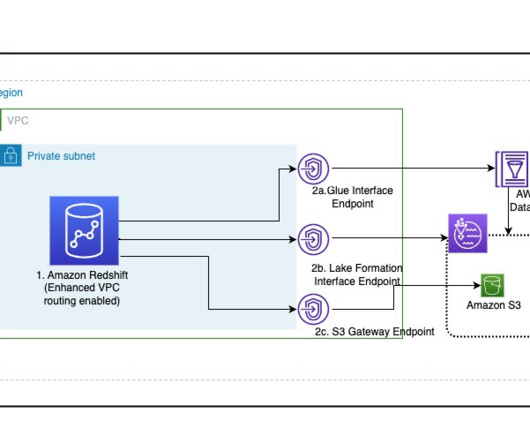
Many customers are extending their data warehouse capabilities to their datalake with Amazon Redshift. They are looking to further enhance their security posture where they can enforce access policies on their datalakes based on Amazon Simple Storage Service (Amazon S3). Choose Create endpoint.
However, more mainstream games use big data as well. Fortnite is one of the games that uses big data to offer great service to its customers. Even Forbes Tech Council has written about the benefits of datalakes in Fortnite. As it turns out, Epic uses a datalake for this massive undertaking.
For more information about performance improvement capabilities, refer to the list of announcements below. Zero-ETL integration also enables you to load and analyze data from multiple operational database clusters in a new or existing Amazon Redshift instance to derive holistic insights across many applications.
You might be modernizing your dataarchitecture using Amazon Redshift to enable access to your datalake and data in your data warehouse, and are looking for a centralized and scalable way to define and manage the data access based on IdP identities. For Permission mode , select Lake Formation.
To learn more about RAG, refer to Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart. A RAG-based generative AI application can only produce generic responses based on its training data and the relevant documents in the knowledge base.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
The CDP Disaster Recovery ReferenceArchitecture. Today we announce the official release of the CDP Disaster Recovery ReferenceArchitecture (DRRA). The CDP Disaster Recovery ReferenceArchitecture is available in our public documentation within the CDP ReferenceArchitectures microsite.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. Additionally, data is extracted from vendor APIs that includes data related to product, marketing, and customer experience.
First, you must understand the existing challenges of the data team, including the dataarchitecture and end-to-end toolchain. Figure 2: Example data pipeline with DataOps automation. In this project, I automated data extraction from SFTP, the public websites, and the email attachments.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
After countless open-source innovations ushered in the Big Data era, including the first commercial distribution of HDFS (Apache Hadoop Distributed File System), commonly referred to as Hadoop, the two companies joined forces, giving birth to an entire ecosystem of technology and tech companies.
Convergent Evolution refers to something else. That was the Science, here comes the Technology… A Brief Hydrology of DataLakes. Of course some architectures featured both paradigms as well. So far so simple. This is the essence of Convergent Evolution. This required additional investments in metadata.
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source datalake. What is a data fabric?
For more details on how to configure and schedule the log collector, refer to the yarn-log-collector GitHub repo. For more information on how to use the YARN log organizer, refer to the yarn-log-organizer GitHub repo. He also understands how to apply technologies to solve big data problems and build a well-designed dataarchitecture.
Tens of thousands of customers run business-critical workloads on Amazon Redshift , AWS’s fast, petabyte-scale cloud data warehouse delivering the best price-performance. With Amazon Redshift, you can query data across your data warehouse, operational data stores, and datalake using standard SQL.
Kinesis Data Streams has native integrations with other AWS services such as AWS Glue and Amazon EventBridge to build real-time streaming applications on AWS. Refer to Amazon Kinesis Data Streams integrations for additional details. To access your data from Timestream, you need to install the Timestream plugin for Grafana.
Building datalakes from continuously changing transactional data of databases and keeping datalakes up to date is a complex task and can be an operational challenge. You can then apply transformations and store data in Delta format for managing inserts, updates, and deletes. with Apache Spark version 3.3.0)
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content