This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Over the years, this customer-centric approach has led to the introduction of groundbreaking features such as zero-ETL , data sharing , streaming ingestion , datalake integration , Amazon Redshift ML , Amazon Q generative SQL , and transactional datalake capabilities.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust data strategy incorporating a comprehensive datagovernance approach. Datagovernance is a critical building block across all these approaches, and we see two emerging areas of focus.
With this integration, you can now seamlessly query your governeddatalake assets in Amazon DataZone using popular business intelligence (BI) and analytics tools, including partner solutions like Tableau. Refer to the detailed blog post on how you can use this to connect through various other tools.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
One-time and complex queries are two common scenarios in enterprise data analytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. file, enter the preprocessing code for the raw lineage data.
In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as datagovernance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated.
Leading companies like Cisco, Nielsen, and Finnair turn to Alation + Snowflake for datagovernance and analytics. By joining forces, we can build more potent, tailored solutions that leverage datagovernance as a competitive asset. Lastly, active datagovernance simplifies stewardship tasks of all kinds.
Datagovernance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure datagovernance at scale for your datalake.
In this blog post, there are three personas: DataLake Administrator (with admin level access) User Silver from the Data Engineering group User Lead Auditor from the Auditor group. You will see how different personas in an organization can access the data without the need to modify their existing enterprise entitlements.
Data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. This leads to having data across many instances of data warehouses and datalakes using a modern data architecture in separate AWS accounts.
In this post, I don’t want to debate the meanings and origins of different terms; rather, I’d like to highlight a technology weapon that you should have in your data management arsenal. We currently refer to this technology as data virtualization.
Datagovernance is the collection of policies, processes, and systems that organizations use to ensure the quality and appropriate handling of their data throughout its lifecycle for the purpose of generating business value.
Although the terms data fabric and data mesh are often used interchangeably, I previously explained that they are distinct but complementary. Denodo remains a specialist data management software provider and in September 2023 announced that it had received a $336 million investment from asset management firm TPG.
AWS Lake Formation and the AWS Glue Data Catalog form an integral part of a datagovernance solution for datalakes built on Amazon Simple Storage Service (Amazon S3) with multiple AWS analytics services integrating with them. To learn more about DataZone, refer to the User Guide. Crawlers, salut!
New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for datalake, data warehouse, and machine learning use cases. If you’re new to Amazon DataZone, refer to Getting started.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. With an on-premise deployment, enterprises have full control over data security, data access, and datagovernance. Data that needs to be tightly controlled (e.g. The Problem with Hybrid Cloud Environments.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture.
Refer to the appendix at the end of this post for more details. To organize the data assets within the organization, the admin logs in to the SageMaker Unified Studio URL and creates domain units aligned with the business divisions. Refer to the appendix at the end of this post for more details.
Solutions data architect: These individuals design and implement data solutions for specific business needs, including data warehouses, data marts, and datalakes. Application data architect: The application data architect designs and implements data models for specific software applications.
The solution is data intelligence. It improves IT and business data literacy and knowledge, supporting enterprise datagovernance and business enablement. Organizations need a real-time, accurate picture of the metadata landscape to: Discover data – Identify and interrogate metadata from various data management silos.
I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or Data Science. Today we have had over 20,000 signatures , millions of page views, and copycat clones, and it is frequently used as a reference guide. It’s Customer Journey for data analytic systems.
Today, we are pleased to announce new AWS Glue connectors for Azure Blob Storage and Azure DataLake Storage that allow you to move data bi-directionally between Azure Blob Storage, Azure DataLake Storage, and Amazon Simple Storage Service (Amazon S3). option("header","true").load("wasbs://yourblob@youraccountname.blob.core.windows.net/loadingtest-input/100mb")
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business. In the navigation pane, under Data catalog , choose Settings.
Flexible and easy to use – The solutions should provide less restrictive, easy-to-access, and ready-to-use data. A data hub is a center of data exchange that constitutes a hub of data repositories and is supported by data engineering, datagovernance, security, and monitoring services.
These data requirements could be satisfied with a strong datagovernance strategy. Governance can — and should — be the responsibility of every data user, though how that’s achieved will depend on the role within the organization. How can data engineers address these challenges directly?
Which type(s) of storage consolidation you use depends on the data you generate and collect. . One option is a datalake—on-premises or in the cloud—that stores unprocessed data in any type of format, structured or unstructured, and can be queried in aggregate. Set up unified datagovernance rules and processes.
The first post of this series describes the overall architecture and how Novo Nordisk built a decentralized data mesh architecture, including Amazon Athena as the data query engine. The third post will show how end-users can consume data from their tool of choice, without compromising datagovernance.
The solution uses AWS services such as AWS HealthLake , Amazon Redshift , Amazon Kinesis Data Streams , and AWS Lake Formation to build a 360 view of patients. Simultaneously and as part of AWS HealthLake managed service, the nested JSON FHIR data undergoes an ETL process and is stored in Apache Iceberg open table format in Amazon S3.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. For more details, refer to Creating Apache Iceberg tables. If this is the first time accessing the Lake Formation console, add yourself as the datalake administrator.
Datagovernance is a key enabler for teams adopting a data-driven culture and operational model to drive innovation with data. Amazon DataZone allows you to simply and securely govern end-to-end data assets stored in your Amazon Redshift data warehouses or datalakes cataloged with the AWS Glue data catalog.
Amazon Redshift now makes it easier for you to run queries in AWS datalakes by automatically mounting the AWS Glue Data Catalog. You no longer have to create an external schema in Amazon Redshift to use the datalake tables cataloged in the Data Catalog.
Datagovernance is traditionally applied to structured data assets that are most often found in databases and information systems. This blog focuses on governing spreadsheets that contain data, information, and metadata, and must themselves be governed.
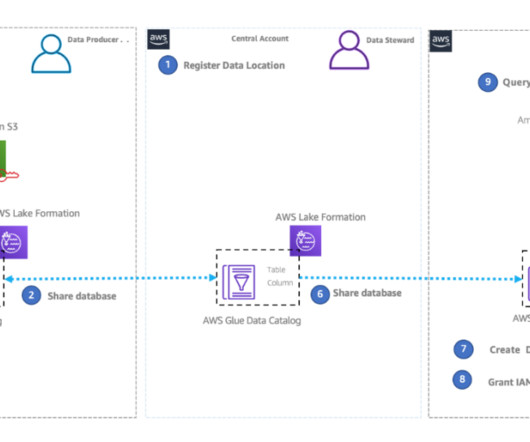
In this solution (as shown in the preceding figure), the AWS account that contains the data assets is referred to as the producer account. The AWS account that needs to access or use the data from the producer account is referred to as the consumer account. You will then publish the data assets from these data sources.
A data lakehouse is an emerging data management architecture that improves efficiency and converges data warehouse and datalake capabilities driven by a need to improve efficiency and obtain critical insights faster. Let’s start with why data lakehouses are becoming increasingly important.
Refer to Enabling AWS PrivateLink in the Snowflake documentation to verify the steps, required access level, and service level to set the configurations. For Data sources , search for and select Snowflake. To obtain the Snowflake PrivateLink account URL, refer to parameters obtained in the prerequisites. Choose Next.
Introduction to OpenLineage compatible data lineage The need to capture data lineage consistently across various analytical services and combine them into a unified object model is key in uncovering insights from the lineage artifact. To learn more, refer to Creating inventory and published data in Amazon DataZone.
AWS Lake Formation helps with enterprise datagovernance and is important for a data mesh architecture. It works with the AWS Glue Data Catalog to enforce data access and governance. This solution only replicates metadata in the Data Catalog, not the actual underlying data.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
Many customers need an ACID transaction (atomic, consistent, isolated, durable) datalake that can log change data capture (CDC) from operational data sources. There is also demand for merging real-time data into batch data. Delta Lake framework provides these two capabilities.
In turn, they both must also have the data literacy skills to be able to verify the data’s accuracy, ensure its security, and provide or follow guidance on when and how it should be used. Then, it applies these insights to automate and orchestrate the data lifecycle.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content