This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
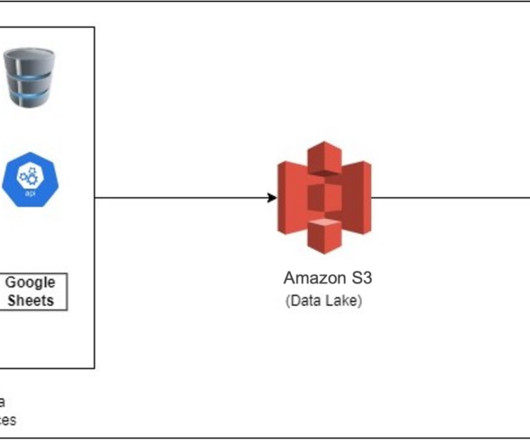
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
Today, we’re excited to announce general availability of Amazon Q dataintegration in AWS Glue. Amazon Q dataintegration, a new generative AI-powered capability of Amazon Q Developer , enables you to build dataintegration pipelines using natural language.
Amazon Redshift enables you to directly access data stored in Amazon Simple Storage Service (Amazon S3) using SQL queries and join data across your data warehouse and datalake. With Amazon Redshift, you can query the data in your S3 datalake using a central AWS Glue metastore from your Redshift data warehouse.
licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in datalakes. Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time.
Effective data analytics relies on seamlessly integratingdata from disparate systems through identifying, gathering, cleansing, and combining relevant data into a unified format. This solution also allows you to update certain fields of the account object in the datalake and push it back to Salesforce.
SageMaker still includes all the existing ML and AI capabilities you’ve come to know and love for data wrangling, human-in-the-loop data labeling with Amazon SageMaker Ground Truth , experiments, MLOps, Amazon SageMaker HyperPod managed distributed training, and more. The tools to transform your business are here.
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
For instance, a Data Cloud-triggered flow could update an account manager in Slack when shipments in an external datalake are marked as delayed. Sharing Customer 360 insights back without data replication. With zero-copy support, the insurance company wouldn’t have to load that weather data into their platform.
AWS Glue is a serverless, scalable dataintegration service that makes it easier to discover, prepare, move, and integratedata from multiple sources. AWS Glue provides an extensible architecture that enables users with different data processing use cases. AWS Glue version Hudi Delta Lake Iceberg AWS Glue 3.0
We refer to this role as TheSnapshotRole in this post. For instructions, refer to the earlier section in this post. For instructions, refer to the earlier section in this post. Sesha Sanjana Mylavarapu is an Associate DataLake Consultant at AWS Professional Services.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
In this post, I don’t want to debate the meanings and origins of different terms; rather, I’d like to highlight a technology weapon that you should have in your data management arsenal. We currently refer to this technology as data virtualization.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build data warehouses and datalakes based on operational data.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity.
Ingestion: Datalake batch, micro-batch, and streaming Many organizations land their source data into their datalake in various ways, including batch, micro-batch, and streaming jobs. Amazon AppFlow can be used to transfer data from different SaaS applications to a datalake.
Today, we are pleased to announce new AWS Glue connectors for Azure Blob Storage and Azure DataLake Storage that allow you to move data bi-directionally between Azure Blob Storage, Azure DataLake Storage, and Amazon Simple Storage Service (Amazon S3). option("header","true").load("wasbs://yourblob@youraccountname.blob.core.windows.net/loadingtest-input/100mb")
The infrastructure provides an analytics experience to hundreds of in-house analysts, data scientists, and student-facing frontend specialists. The data engineering team is on a mission to modernize its dataintegration platform to be agile, adaptive, and straightforward to use.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture.
Although the terms data fabric and data mesh are often used interchangeably, I previously explained that they are distinct but complementary. With Denodo Platform 9, the company also added enhanced federated governance support to enable the creation, management and reuse of data products by different business units and teams.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Recently, datalakes have gained lot of traction to become the foundation for analytical solutions, because they come with benefits such as scalability, fault tolerance, and support for structured, semi-structured, and unstructured datasets.
A point of data entry in a given pipeline. Examples of an origin include storage systems like datalakes, data warehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
AWS has invested in a zero-ETL (extract, transform, and load) future so that builders can focus more on creating value from data, instead of having to spend time preparing data for analysis. To create an AWS HealthLake data store, refer to Getting started with AWS HealthLake. reference", SUBSTRING(a."patient"."reference",
For more information about performance improvement capabilities, refer to the list of announcements below. Zero-ETL integration also enables you to load and analyze data from multiple operational database clusters in a new or existing Amazon Redshift instance to derive holistic insights across many applications.
For any modern data-driven company, having smooth dataintegration pipelines is crucial. These pipelines pull data from various sources, transform it, and load it into destination systems for analytics and reporting. For instructions, refer to Create a CloudWatch alarm based on a static threshold.
We have seen a strong customer demand to expand its scope to cloud-based datalakes because datalakes are increasingly the enterprise solution for large-scale data initiatives due to their power and capabilities. Let’s say that this company is located in Europe and the data product must comply with the GDPR.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. As part of the transformation, the objects need to be treated to ensure data privacy (for example, PII redaction).
This post focuses on such schema changes in file-based tables and shows how to automatically replicate the schema evolution of structured data from table formats in databases to the tables stored as files in cost-effective way. Apache Hudi supports ACID transactions and CRUD operations on a datalake. and save it.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing. Choose Create connection. Choose Next.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. Additionally, data is extracted from vendor APIs that includes data related to product, marketing, and customer experience.
The data sourcing problem To ensure the reliability of PySpark data pipelines, it’s essential to have consistent record-level data from both dimensional and fact tables stored in the Enterprise Data Warehouse (EDW). These tables are then joined with tables from the Enterprise DataLake (EDL) at runtime.
It’s even harder when your organization is dealing with silos that impede data access across different data stores. Seamless dataintegration is a key requirement in a modern data architecture to break down data silos. For more details, refer to Spark Release 3.3.0 AWS Glue Data Catalog client 3.6.0
It improves IT and business data literacy and knowledge, supporting enterprise data governance and business enablement. It helps solve the lack of visibility and control over “data at rest” in databases, datalakes and data warehouses and “data in motion” as it is integrated with and used by key applications.
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. AWS Glue provides both visual and code-based interfaces to make dataintegration effortless.
In AWS, hundreds of thousands of customers use AWS Glue , a serverless dataintegration service, to discover, combine, and prepare data for analytics and machine learning. For more information about Apache Spark UI, refer to Web UI in Apache Spark. For more information, refer to Data Catalog and crawlers in AWS Glue.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content