This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. About the Authors Dave Horne is a Sr.
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters.
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. Next, the merged data is filtered to include only a specific geographic region. Then the transformed output data is saved to Amazon S3 for further processing in future.
The workflow consists of the following initial steps: OpenSearch Service is hosted in the primary Region, and all the active traffic is routed to the OpenSearch Service domain in the primary Region. We refer to this role as TheSnapshotRole in this post. For instructions, refer to the earlier section in this post.
On your project, in the navigation pane, choose Data. For Add data source , choose Add connection. For Host , enter your host name of your Aurora PostgreSQL database cluster. format(connection_properties["HOST"],connection_properties["PORT"],connection_properties["DATABASE"]) df.write.format("jdbc").option("url",
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. Apache Hudi connector for AWS Glue For this post, we use AWS Glue 4.0,
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Recently, datalakes have gained lot of traction to become the foundation for analytical solutions, because they come with benefits such as scalability, fault tolerance, and support for structured, semi-structured, and unstructured datasets.
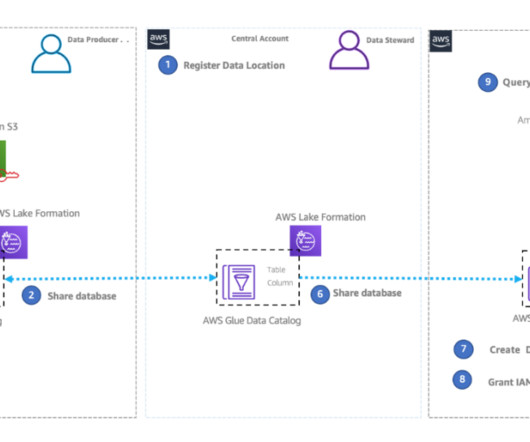
Today’s modern datalakes span multiple accounts, AWS Regions, and lines of business in organizations. It’s important that their data solution gives them the ability to share and access data securely and safely across Regions. For example, we are using a datalake administrator role called LF-Admin.
The Hive metastore is a repository of metadata about the SQL tables, such as database names, table names, schema, serialization and deserialization information, data location, and partition details of each table. Therefore, organizations have come to host huge volumes of metadata of their structured datasets in the Hive metastore.
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
Many organizations are building datalakes to store and analyze large volumes of structured, semi-structured, and unstructured data. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products.
This involves creating VPC endpoints in both the AWS and Snowflake VPCs, making sure data transfer remains within the AWS network. Use Amazon Route 53 to create a private hosted zone that resolves the Snowflake endpoint within your VPC. For Data sources , search for and select Snowflake. Choose Create connection. Choose Next.
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business. In the navigation pane, under Data catalog , choose Settings.
Modern applications store massive amounts of data on Amazon Simple Storage Service (Amazon S3) datalakes, providing cost-effective and highly durable storage, and allowing you to run analytics and machine learning (ML) from your datalake to generate insights on your data.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. For more details, refer to Creating Apache Iceberg tables. The customer wants to make product data accessible to analyst personas for interactive analysis using Athena.
It supports both data quality at rest and data quality in AWS Glue extract, transform, and load (ETL) pipelines. Data quality at rest focuses on validating the data stored in datalakes, databases, or data warehouses. It ensures that the data meets specific quality standards before it is consumed.
Datalakes are designed for storing vast amounts of raw, unstructured, or semi-structured data at a low cost, and organizations share those datasets across multiple departments and teams. The queries on these large datasets read vast amounts of data and can perform complex join operations on multiple datasets.
For instructions, refer to Creating and managing Amazon OpenSearch Service domains. For Host , enter events.PagerDuty.com. For more information about anomaly detection and alerts in OpenSearch Service, refer to Anomaly Detection in Amazon OpenSearch and Configuring Alerts in Amazon OpenSearch. For Method , choose POST.
Set up EMR Studio In this step, we demonstrate the actions needed from the datalake administrator to set up EMR Studio enabled for trusted identity propagation and with IAM Identity Center integration. If Lake Formation is not already enabled, refer to Getting started with Lake Formation.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
For additional details, refer to Automated snapshots. For additional details, refer to Manual snapshots. Amazon Redshift integrates with AWS Backup to help you centralize and automate data protection across all your AWS services, in the cloud, and on premises. This can result in recovery times between 10–60 minutes.
Refer to How do I set up a NAT gateway for a private subnet in Amazon VPC? For more information, refer to Prerequisites. For more information, refer to Storing database credentials in AWS Secrets Manager. For instructions to set up AWS Cloud9, refer to Getting started: basic tutorials for AWS Cloud9. manylinux2014_x86_64.whl
Over the past decade, deep learning arose from a seismic collision of data availability and sheer compute power, enabling a host of impressive AI capabilities. Slate refers to a family of encoder-only (RoBERTa-based) models, which while not generative, are fast and effective for many enterprise NLP tasks. All watsonx.ai
Building datalakes from continuously changing transactional data of databases and keeping datalakes up to date is a complex task and can be an operational challenge. You can then apply transformations and store data in Delta format for managing inserts, updates, and deletes. with Apache Spark version 3.3.0)
In scenarios where a pipeline ingests data from multiple topics, the topic with the highest number of partitions should be used as a reference to configure the maximum OCUs. sink: - opensearch: # Provide an AWS OpenSearch Service domain endpoint hosts: [ "[link]. > region: " >" msk: # Provide the MSK ARN.
For more details, refer to Amazon QuickSight resource type reference. In this post, we show how to automate the deployment of a QuickSight analysis connecting to an Amazon Redshift data warehouse with a CloudFormation template. For instructions, refer to Authorizing connections from Amazon QuickSight to Amazon Redshift clusters.
Amazon Redshift , a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables. example.com:9092,broker-2.example.com:9092'
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. This solution uses Amazon Aurora MySQL hosting the example database salesdb.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
For instructions, refer to Installing or updating the latest version of the AWS CLI. For instructions, refer to Configuration and credential file settings. Also, note that we are using data-team-a as a namespace and emr-job-execution-sa as a service account, which we created in the previous step.
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. Over time, workloads start processing more data, tenants start onboarding more workloads, and administrators (admins) start onboarding more tenants. Cloudera Manager (CM) 6.2
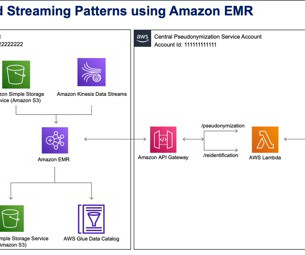
The account on the right hosts the pseudonymization service, which you can deploy using the instructions provided in the Part 1 of this series. For an overview of how to build an ACID compliant datalake using Iceberg, refer to Build a high-performance, ACID compliant, evolving datalake using Apache Iceberg on Amazon EMR.
It is prudent to consolidate this data into a single customer view, serving as a primary reference for downstream applications, ranging from ecommerce platforms to CRM systems. This consolidated view acts as a liaison between the data platform and customer-centric applications.
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating datalakes, serving as object storage for consumer applications, storing logs, and archiving data. This could be your datalake or application S3 bucket.
I’m referring not only to our technology partners, but also to our cloud partners that host the Denodo Platform, Denodo is a very partner-friendly company, and here I’d like to share some thoughts about how Denodo works with our partners.
Depending on your enterprise’s culture and goals, your migration pattern of a legacy multi-tenant data platform to Amazon Redshift could use one of the following strategies: Leapfrog strategy – In this strategy, you move to an AWS modern data architecture and migrate one tenant at a time. Vijay Bagur is a Sr. Technical Account Manager.
Data as a product Treating data as a product entails three key components: the data itself, the metadata, and the associated code and infrastructure. In this approach, teams responsible for generating data are referred to as producers.
The data lakehouse is gaining in popularity because it enables a single platform for all your enterprise data with the flexibility to run any analytic and machine learning (ML) use case. Cloud data lakehouses provide significant scaling, agility, and cost advantages compared to cloud datalakes and cloud data warehouses.
At Stitch Fix, we have been powered by data science since its foundation and rely on many modern datalake and data processing technologies. In our infrastructure, Apache Kafka has emerged as a powerful tool for managing event streams and facilitating real-time data processing.
Tens of thousands of customers use Amazon Redshift to gain business insights from their data. With Amazon Redshift, you can use standard SQL to query data across your data warehouse, operational data stores, and datalake. For more information, refer to Configuring ongoing data replication.
Start where your data is Using your own enterprise data is the major differentiator from open access gen AI chat tools, so it makes sense to start with the provider already hosting your enterprise data. Walker refers to “guided play sessions” and users were encouraged to share what worked with their peers.
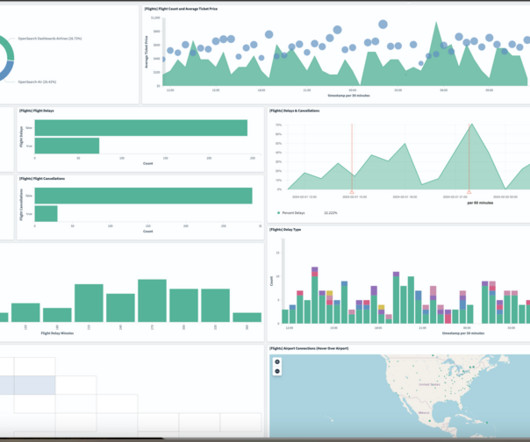
Top line revenue refers to the total value of sales of an organization’s services or products. The data from the S3 datalake is used for batch processing and analytics through Amazon EMR and Amazon Redshift. Operational dashboards are hosted on Grafana integrated with Druid.
“Flashpoint” (2018) – GDPR went into effect, plus major data blunders happened seemingly everywhere. Fun fact : I co-founded an e-commerce company (realistically, a mail-order catalog hosted online) in December 1992 using one of those internetworking applications called Gopher , which was vaguely popular at the time. Upcoming Events.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content