This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datalakes and datawarehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Business units access clean, standardized data.
Data architecture has evolved significantly to handle growing data volumes and diverse workloads. Initially, datawarehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
SageMaker still includes all the existing ML and AI capabilities you’ve come to know and love for data wrangling, human-in-the-loop data labeling with Amazon SageMaker Ground Truth , experiments, MLOps, Amazon SageMaker HyperPod managed distributed training, and more. The tools to transform your business are here.
Amazon Redshift is a fast, fully managed petabyte-scale cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
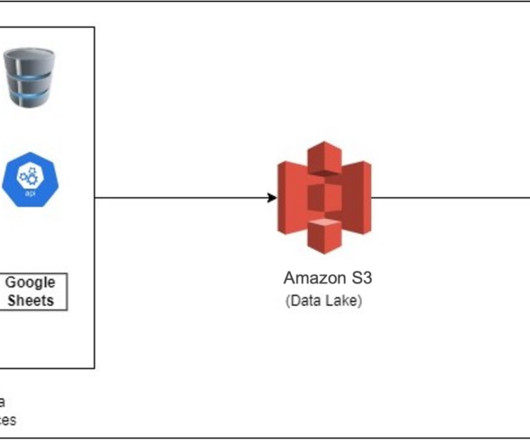
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. Refer to Easy analytics and cost-optimization with Amazon Redshift Serverless to get started. For this post, we use Redshift Serverless. Choose Run all on each notebook tab.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in datalakes. Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time.
Today, many customers build data quality validation pipelines using its Data Quality Definition Language (DQDL) because with static rules, dynamic rules , and anomaly detection capability , its fairly straightforward. One of its key features is the ability to manage data using branches.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
This post explores how to start using Delta Lake UniForm on Amazon Web Services (AWS). You can learn how to query Delta Lake native tables through UniForm from different datawarehouses or engines such as Amazon Redshift as an example of expanding data access to more engines. in Delta Lake public document.
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. Test access using SageMaker Studio in the consumer account.
These types of queries are suited for a datawarehouse. The goal of a datawarehouse is to enable businesses to analyze their data fast; this is important because it means they are able to gain valuable insights in a timely manner. Amazon Redshift is fully managed, scalable, cloud datawarehouse.
That stands for “bring your own database,” and it refers to a model in which core ERP data are replicated to a separate standalone database used exclusively for reporting. OLAP reporting has traditionally relied on a datawarehouse. Option 3: Azure DataLakes. Datalakes are not a mature technology.
One-time and complex queries are two common scenarios in enterprise data analytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level datawarehouses in massive data scenarios. Here, data modeling uses dbt on Amazon Redshift.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. and later supports the Apache Iceberg framework for datalakes. AWS Glue 3.0 The following diagram illustrates the solution architecture.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, datawarehouse, and purpose-built stores with a unified governance model. Of those tables, some are larger (such as in terms of record volume) than others, and some are updated more frequently than others.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Amazon AppFlow automatically encrypts data in motion, and allows you to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink , reducing exposure to security threats. Refer to the Amazon Redshift Database Developer Guide for more details.
Its solution was to replicate data from the production database, using data entities, into a traditional relational database. Microsoft referred to this approach as “bring your own database” (BYOD). For more sophisticated multidimensional reporting functions, however, a more advanced approach to staging data is required.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Enterprise data is brought into datalakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on.
Amazon Redshift Serverless makes it simple to run and scale analytics without having to manage your datawarehouse infrastructure. For more details on tagging, refer to Tagging resources overview. For more tagging best practices, refer to Tagging AWS resources. Choose Save changes. About the Authors Sandeep Bajwa is a Sr.
Whether you are new to Apache Iceberg on AWS or already running production workloads on AWS, this comprehensive technical guide offers detailed guidance on foundational concepts to advanced optimizations to build your transactional datalake with Apache Iceberg on AWS. He can be reached via LinkedIn. He can be reached via LinkedIn.
In this post, we discuss how the Kaplan data engineering team implemented data integration from the Salesforce application to Amazon Redshift. Solution overview The high-level data flow starts with the source data stored in Amazon S3 and then integrated into Amazon Redshift using various AWS services.
This leads to having data across many instances of datawarehouses and datalakes using a modern data architecture in separate AWS accounts. We recently announced the integration of Amazon Redshift data sharing with AWS Lake Formation.
Datalakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a datalake design, data should be immutable once stored. A datalake built on AWS uses Amazon Simple Storage Service (Amazon S3) as its primary storage environment.
When you build your transactional datalake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 datalake to optimize the production environment. For more information, refer to Retry Amazon S3 requests with EMRFS. availability.
With Amazon Redshift, you can use standard SQL to query data across your datawarehouse, operational data stores, and datalake. Migrating a datawarehouse can be complex. You have to migrate terabytes or petabytes of data from your legacy system while not disrupting your production workload.
You can now generate data integration jobs for various data sources and destinations, including Amazon Simple Storage Service (Amazon S3) datalakes with popular file formats like CSV, JSON, and Parquet, as well as modern table formats such as Apache Hudi , Delta , and Apache Iceberg.
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your datalake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable).
In a datawarehouse, a dimension is a structure that categorizes facts and measures in order to enable users to answer business questions. As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for datalake, datawarehouse, and machine learning use cases. If you’re new to Amazon DataZone, refer to Getting started.
but to reference concrete tooling used today in order to ground what could otherwise be a somewhat abstract exercise. Adapted from the book Effective Data Science Infrastructure. ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing datawarehouses.
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build datawarehouses and datalakes based on operational data.
Today, customers are embarking on data modernization programs by migrating on-premises datawarehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. The following diagram illustrates this use case’s historical data migration architecture.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central datawarehouse or a datalake to deliver business insights.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content