This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. About the Authors Dave Horne is a Sr.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
Datalakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a datalake design, data should be immutable once stored. A datalake built on AWS uses Amazon Simple Storage Service (Amazon S3) as its primary storage environment.
Refer to Easy analytics and cost-optimization with Amazon Redshift Serverless to get started. Let’s ask Amazon Q “Can you give me the total sales for 1998, from different sales channels, using a union of the sales data from different channels?” It can help optimize the generation process by reducing unnecessary table references.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on.
AWS Glue provides an extensible architecture that enables users with different data processing use cases. A common use case is building datalakes on Amazon Simple Storage Service (Amazon S3) using AWS Glue extract, transform, and load (ETL) jobs. AWS Glue version Hudi Delta Lake Iceberg AWS Glue 3.0 AWS Glue 4.0
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
In modern data architectures, Apache Iceberg has emerged as a popular table format for datalakes, offering key features including ACID transactions and concurrent write support. For more detailed configuration, refer to Write properties in the Iceberg documentation.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. Apache Hudi connector for AWS Glue For this post, we use AWS Glue 4.0,
This post shows you how to integrate Apache Flink in Amazon EMR with the AWS Glue Data Catalog so that you can ingest streaming data in real time and access the data in near-real time for business analysis. For data read/write, Flink has the interface DynamicTableSourceFactory for read and DynamicTableSinkFactory for write.
With this platform, Salesforce seeks to help organizations apply the cleverness of LLMs to the customer data they have squirreled away in Salesforce datalakes in the hopes of selling more. Einstein 1 Studio handles the piping so the data from your Einstein 1 platform instance will flow smoothly into the AI.
We have seen a strong customer demand to expand its scope to cloud-based datalakes because datalakes are increasingly the enterprise solution for large-scale data initiatives due to their power and capabilities. Let’s say that this company is located in Europe and the data product must comply with the GDPR.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
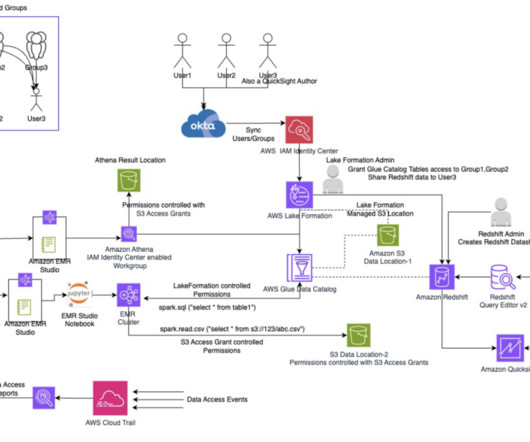
These users interact with and run analytical queries across AWS analytics services. To enable them to use the AWS services, their identities from the external IdP are mapped to AWS Identity and Access Management (IAM) roles within AWS, and access policies are applied to these IAM roles by data administrators.
There are several choices to consider, each with its own set of advantages and disadvantages: Data warehouses are used to store data that has been processed for a specific function from one or more sources. Datalakes hold raw data that has not yet been altered to meet a specific purpose.
When it was no longer a hard requirement that a physical data model be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) and data sources residing in AWS, on-premises, or other cloud systems using SQL or Python. He works with enterprise customers building data products, analytics platforms, and solutions on AWS.
Refer to the appendix at the end of this post for more details. To organize the data assets within the organization, the admin logs in to the SageMaker Unified Studio URL and creates domain units aligned with the business divisions. Refer to the appendix at the end of this post for more details.
Unstructured data is typically stored across siloed systems in varying formats, and generally not managed or governed with the same level of rigor as structured data. On the backend, the batch data engineering processes refreshing the enterprise datalake need to expand to ingest, transform, and manage unstructured data.
Data Explorer is a big data analytics platform that you can use, as the name suggests, for exploring data using KQL, also known as the Kusto Query Language, from the codename for the project which may or may not be a reference to exploring your ocean of data as if you were Jacques Cousteau.
We have collected some of the key talks and solutions on data governance, data mesh, and modern data architecture published and presented in AWS re:Invent 2022, and a few datalake solutions built by customers and AWS Partners for easy reference.
Amazon Q Developer can now generate complex data integration jobs with multiple sources, destinations, and data transformations. and Amazon Q provides concise explanations along with references you can use to follow up on your questions and validate the guidance. Configure an IAM role to interact with Amazon Q.
With Amazon EMR 6.15, we launched AWS Lake Formation based fine-grained access controls (FGAC) on Open Table Formats (OTFs), including Apache Hudi, Apache Iceberg, and Delta lake. Many large enterprise companies seek to use their transactional datalake to gain insights and improve decision-making.
For NoSQL, datalakes, and datalake houses—data modeling of both structured and unstructured data is somewhat novel and thorny. This blog is an introduction to some advanced NoSQL and datalake database design techniques (while avoiding common pitfalls) is noteworthy. Data Modeling.
Lately, the concept of data experience has been gaining attention in discussions around the enterprise data stack. As the name suggests, it refers to how people interact with data in enterprise settings. Due to fragmented data setups in these companies, their datalakes have the following characteristics:
Data producer setup In this section, we present the steps to set up the data producer. In the navigation pane, under Register and ingest , choose Datalake locations. For additional information about roles, refer to Requirements for roles used to register locations. Choose Register location.
I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or Data Science. Today we have had over 20,000 signatures , millions of page views, and copycat clones, and it is frequently used as a reference guide. It’s Customer Journey for data analytic systems.
For interactive applications, Athena Spark allows you to spend less time waiting and be more productive, with application startup time in under a second. Running SQL on datalakes is fast, and Athena provides an optimized, Trino- and Presto-compatible API that includes a powerful optimizer.
Many organizations are building datalakes to store and analyze large volumes of structured, semi-structured, and unstructured data. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products.
To enable this use case, we used the BMW Group’s cloud-native data platform called the Cloud Data Hub. In 2019, the BMW Group decided to re-architect and move its on-premises datalake to the AWS Cloud to enable data-driven innovation while scaling with the dynamic needs of the organization.
The data sourcing problem To ensure the reliability of PySpark data pipelines, it’s essential to have consistent record-level data from both dimensional and fact tables stored in the Enterprise Data Warehouse (EDW). These tables are then joined with tables from the Enterprise DataLake (EDL) at runtime.
Use case A typical workload for AWS Glue for Apache Spark jobs is to load data from a relational database to a datalake with SQL-based transformations. For instructions, refer to Create a CloudWatch alarm based on a static threshold. When the example job ran, the workerUtilization metrics showed the following trend.
To learn more about RAG, refer to Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart. A RAG-based generative AI application can only produce generic responses based on its training data and the relevant documents in the knowledge base.
Flexible and easy to use – The solutions should provide less restrictive, easy-to-access, and ready-to-use data. A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users.
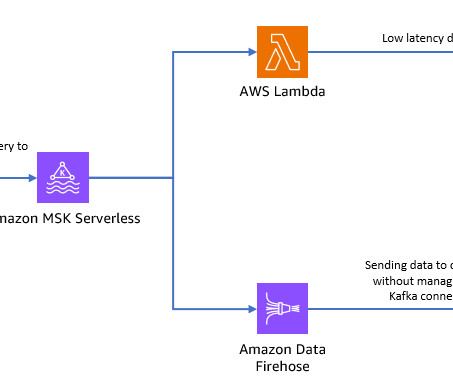
For your application’s low-latency and real-time data access, you can use Lambda and DynamoDB. For longer-term data storage, you can use managed serverless connector service Amazon Data Firehose to send data to your datalake. To use the console, refer to Getting started using MSK Serverless clusters.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. For more details, refer to Creating Apache Iceberg tables. The customer wants to make product data accessible to analyst personas for interactive analysis using Athena.
This report is essential for understanding revenue streams, identifying opportunities for optimization, and making data-driven decisions regarding pricing and promotions. Refer to Enabling AWS PrivateLink in the Snowflake documentation to verify the steps, required access level, and service level to set the configurations. Choose Next.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
This data is often stored and analyzed using various tools, such as Amazon OpenSearch Service , a powerful search and analytics service offered by AWS. OpenSearch Service provides real-time insights into your data to support use cases like interactive log analytics, real-time application monitoring, website search, and more.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content