This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
Over the years, this customer-centric approach has led to the introduction of groundbreaking features such as zero-ETL , data sharing , streaming ingestion , datalake integration , Amazon Redshift ML , Amazon Q generative SQL , and transactional datalake capabilities.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. This is where Amazon Bedrock comes into play.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machine learning (ML) models and AI-powered applications. Amazon SageMaker Unified Studio (Preview) solves this challenge by providing an integrated authoring experience to use all your data and tools for analytics and AI.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. Of those tables, some are larger (such as in terms of record volume) than others, and some are updated more frequently than others.
That stands for “bring your own database,” and it refers to a model in which core ERP data are replicated to a separate standalone database used exclusively for reporting. OLAP reporting based on a data warehouse model is a well-proven solution for companies with robust reporting requirements.
One-time and complex queries are two common scenarios in enterprise data analytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. Here, datamodeling uses dbt on Amazon Redshift.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. foundation model (FM) in Amazon Bedrock as the LLM. Can it also help write SQL queries?
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
Consultants and developers familiar with the AX datamodel could query the database using any number of different tools, including a myriad of different report writers. Data entities are more secure and arguably easier to master than the relational database model, but one downside is there are lots of them! DataLakes.
Let’s start by considering the job of a non-ML software engineer: writing traditional software deals with well-defined, narrowly-scoped inputs, which the engineer can exhaustively and cleanly model in the code. Not only is data larger, but models—deep learning models in particular—are much larger than before. Compute.
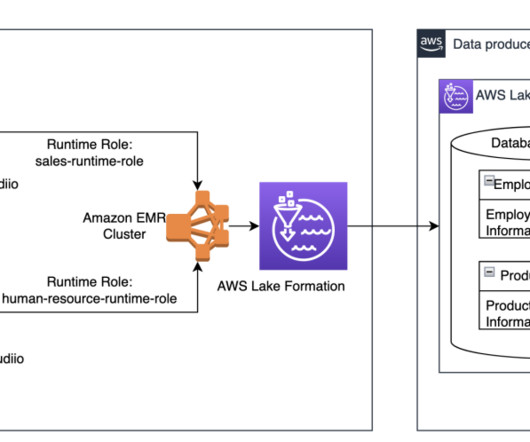
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters.
Custom context enhances the AI model’s understanding of your specific datamodel, business logic, and query patterns, allowing it to generate more relevant and accurate SQL recommendations. Within this feature, user data is secure and private. Your data is not shared across accounts.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. Search for the Jira Cloud connector.
In modern data architectures, Apache Iceberg has emerged as a popular table format for datalakes, offering key features including ACID transactions and concurrent write support. For more detailed configuration, refer to Write properties in the Iceberg documentation.
Data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. This leads to having data across many instances of data warehouses and datalakes using a modern data architecture in separate AWS accounts.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
For NoSQL, datalakes, and datalake houses—datamodeling of both structured and unstructured data is somewhat novel and thorny. This blog is an introduction to some advanced NoSQL and datalake database design techniques (while avoiding common pitfalls) is noteworthy. DataModeling.
By collecting data from store sensors using AWS IoT Core , ingesting it using AWS Lambda to Amazon Aurora Serverless , and transforming it using AWS Glue from a database to an Amazon Simple Storage Service (Amazon S3) datalake, retailers can gain deep insights into their inventory and customer behavior.
This year, however, Salesforce has accelerated its agenda, integrating much of its recent work with large language models (LLMs) and machine learning into a low-code tool called Einstein 1 Studio. Einstein 1 Studio is a set of low-code tools to create, customize, and embed AI models in Salesforce workflows. What is Einstein 1 Studio?
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. To achieve this, they plan to use machine learning (ML) models to extract insights from data.
Amazon SageMaker Unified Studio (preview) provides a unified experience for using data, analytics, and AI capabilities. You can use familiar AWS services for model development, generative AI, data processing, and analyticsall within a single, governed environment. Refer to the appendix at the end of this post for more details.
We have seen a strong customer demand to expand its scope to cloud-based datalakes because datalakes are increasingly the enterprise solution for large-scale data initiatives due to their power and capabilities. The team uses dbt-glue to build a transformed gold model optimized for business intelligence (BI).
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. With a cloud deployment, enterprises can leverage a “pay as you go” model; reducing the burden of incurring capital costs. Due to these needs, hybrid cloud datalakes emerged as a logical middle ground between the two consumption models.
Q: Is datamodeling cool again? In today’s fast-paced digital landscape, data reigns supreme. The data-driven enterprise relies on accurate, accessible, and actionable information to make strategic decisions and drive innovation. A: It always was and is getting cooler!!
Architecturally the introduction of Hadoop, a file system designed to store massive amounts of data, radically affected the cost model of data. Organizationally the innovation of self-service analytics, pioneered by Tableau and Qlik, fundamentally transformed the user model for data analysis.
It manages large collections of files as tables, and it supports modern analytical datalake operations such as record-level insert, update, delete, and time travel queries. Data labeling is required for various use cases, including forecasting, computer vision, natural language processing, and speech recognition.
“The challenge that a lot of our customers have is that requires you to copy that data, store it in Salesforce; you have to create a place to store it; you have to create an object or field in which to store it; and then you have to maintain that pipeline of data synchronization and make sure that data is updated,” Carlson said.
You can attach an EMR Studio Workspace to an EMR cluster, and use the compute power of the EMR cluster and run data science jobs on the cluster. Data is often stored in datalakes managed by AWS Lake Formation , enabling you to apply fine-grained access control through a simple grant or revoke mechanism.
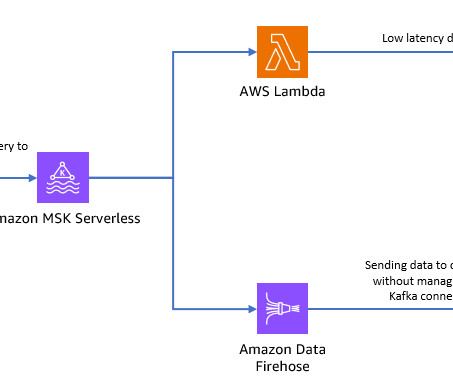
A hybrid cloud system is a cloud deployment model combining different cloud types, using both an on-premise hardware solution and a public cloud. You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the datalake using various cloud services like Amazon’s S3 and others.
Taking the broadest possible interpretation of data analytics , Azure offers more than a dozen services — and that’s before you include Power BI, with its AI-powered analysis and new datamart option , or governance-oriented approaches such as Microsoft Purview. Azure Data Factory. Azure DataLake Analytics.
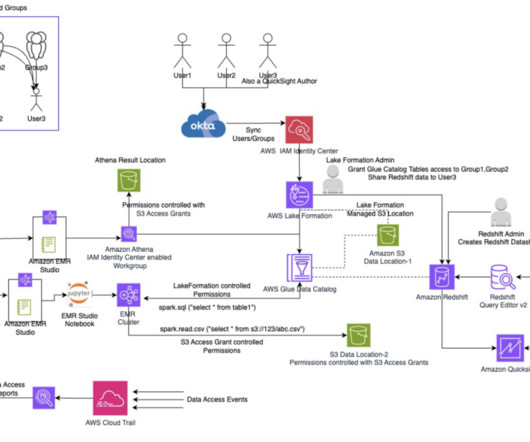
Later in this post, we also briefly touch upon using CloudTrail Lake to query the data access events. AWS CloudFormation lets you model, provision, and manage AWS and third-party resources by treating infrastructure as code. Refer to Configure SAML and SCIM with Okta and IAM Identity Center for instructions.
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust data strategy incorporating a comprehensive data governance approach. Data governance is a critical building block across all these approaches, and we see two emerging areas of focus.
We have collected some of the key talks and solutions on data governance, data mesh, and modern data architecture published and presented in AWS re:Invent 2022, and a few datalake solutions built by customers and AWS Partners for easy reference.
Solutions data architect: These individuals design and implement data solutions for specific business needs, including data warehouses, data marts, and datalakes. Application data architect: The application data architect designs and implements datamodels for specific software applications.
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build data warehouses and datalakes based on operational data.
Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake. Data confidentiality and data quality are the two essential themes for data governance.
“In cases where privacy is essential, we try to anonymize as much as possible and then move on to training the model,” says University of Florence technologist Vincenzo Laveglia. “A If after anonymization the level of information in the data is the same, the data is still useful. A balance between privacy and utility is needed.
Foundation models (FMs) are large machine learning (ML) models trained on a broad spectrum of unlabeled and generalized datasets. This scale and general-purpose adaptability are what makes FMs different from traditional ML models. FMs are multimodal; they work with different data types such as text, video, audio, and images.
These business units have varying landscapes, where a datalake is managed by Amazon Simple Storage Service (Amazon S3) and analytics workloads are run on Amazon Redshift , a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data.
You want real-time access to this data so you can monitor performance in real time, and detect and mitigate issues quickly. You also need longer-term access to this data for machine learning (ML) models to run predictive maintenance assessments, find optimization opportunities, and forecast demand.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content