This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. and later supports the Apache Iceberg framework for datalakes. AWS Glue 3.0 The following diagram illustrates the solution architecture.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. We recommend testing your use case and data with different models.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? The applications must be integrated to the surrounding business systems so ideas can be tested and validated in the real world in a controlled manner.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
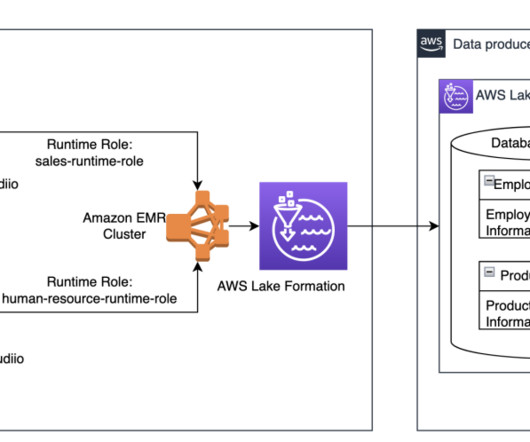
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters.
Datalakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a datalake design, data should be immutable once stored. A datalake built on AWS uses Amazon Simple Storage Service (Amazon S3) as its primary storage environment.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
When you build your transactional datalake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 datalake to optimize the production environment. For more information, refer to Retry Amazon S3 requests with EMRFS. availability.
Its solution was to replicate data from the production database, using data entities, into a traditional relational database. Microsoft referred to this approach as “bring your own database” (BYOD). There is an established body of practice around creating, managing, and accessing OLAP data (known as “cubes”). DataLakes.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
Refer to Easy analytics and cost-optimization with Amazon Redshift Serverless to get started. Safety features Amazon Q generative SQL has built-in safety features to warn if a generated SQL statement will modify data and will only run based on user permissions. To test this, let’s ask Amazon Q to “delete data from web_sales table.”
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your datalake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable).
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. Upon checking the S3 data target, we can see the S3 path is now a placeholder and the output format is Parquet. To learn more, refer to Amazon Q data integration in AWS Glue.
Data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. This leads to having data across many instances of data warehouses and datalakes using a modern data architecture in separate AWS accounts.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. A question arises on what level of details we need to include in the table metadata.
In our previous post Improve operational efficiencies of Apache Iceberg tables built on Amazon S3 datalakes , we discussed how you can implement solutions to improve operational efficiencies of your Amazon Simple Storage Service (Amazon S3) datalake that is using the Apache Iceberg open table format and running on the Amazon EMR big data platform.
Major market indexes, such as S&P 500, are subject to periodic inclusions and exclusions for reasons beyond the scope of this post (for an example, refer to CoStar Group, Invitation Homes Set to Join S&P 500; Others to Join S&P 100, S&P MidCap 400, and S&P SmallCap 600 ).
You can attach an EMR Studio Workspace to an EMR cluster, and use the compute power of the EMR cluster and run data science jobs on the cluster. Data is often stored in datalakes managed by AWS Lake Formation , enabling you to apply fine-grained access control through a simple grant or revoke mechanism.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and testdata sources. This approach simplifies your data journey and helps you meet your security requirements. This new capability can simplify your data journey.
The data engineer then emails the BI Team, who refreshes a Tableau dashboard. Figure 1: Example data pipeline with manual processes. There are no automated tests , so errors frequently pass through the pipeline. Figure 2: Example data pipeline with DataOps automation. Adding Tests to Reduce Stress.
Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake. Data confidentiality and data quality are the two essential themes for data governance.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
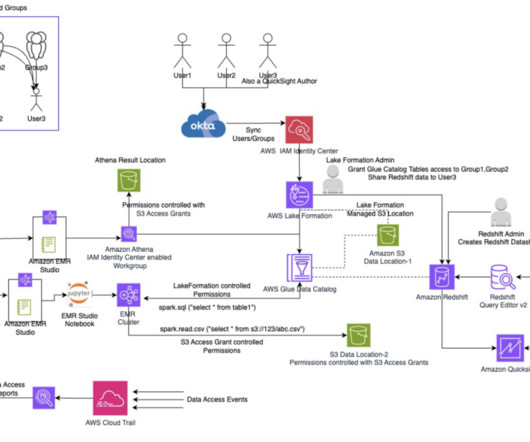
Refer to Configure SAML and SCIM with Okta and IAM Identity Center for instructions. You need to reference the bucket name and the certificate bundle.zip file in AWS CloudFormation. Refer to the following table for a list of important parameters. In this post, we use the us-east-1 Region. In this post, we grant access to Group1.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Compare ongoing data that is replicated from the source on-premises database to the target S3 datalake.
I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or Data Science. Today we have had over 20,000 signatures , millions of page views, and copycat clones, and it is frequently used as a reference guide. It’s Customer Journey for data analytic systems.
These business units have varying landscapes, where a datalake is managed by Amazon Simple Storage Service (Amazon S3) and analytics workloads are run on Amazon Redshift , a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data.
As enterprises collect increasing amounts of data from various sources, the structure and organization of that data often need to change over time to meet evolving analytical needs. Schema evolution enables adding, deleting, renaming, or modifying columns without needing to rewrite existing data.
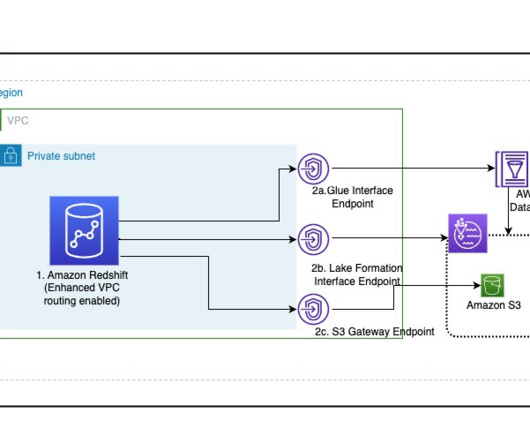
Many customers are extending their data warehouse capabilities to their datalake with Amazon Redshift. They are looking to further enhance their security posture where they can enforce access policies on their datalakes based on Amazon Simple Storage Service (Amazon S3). Choose Create endpoint.
Due to these limitations, the application should not be used for arbitrary tests. In this post, we provide instructions on how to deploy a sample API application integrated with Lake Formation that implements the solution architecture. We also show how to test the function with Lambda tests.
This solution also allows you to update certain fields of the account object in the datalake and push it back to Salesforce. To achieve this, you create two ETL jobs using AWS Glue with the Salesforce connector, and create a transactional datalake on Amazon S3 using Apache Iceberg.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning (ML), and application development. Apache Hudi supports ACID transactions and CRUD operations on a datalake. You don’t alter queries separately in the datalake.
Today, we are pleased to announce new AWS Glue connectors for Azure Blob Storage and Azure DataLake Storage that allow you to move data bi-directionally between Azure Blob Storage, Azure DataLake Storage, and Amazon Simple Storage Service (Amazon S3). option("header","true").load("wasbs://yourblob@youraccountname.blob.core.windows.net/loadingtest-input/100mb")
A point of data entry in a given pipeline. Examples of an origin include storage systems like datalakes, data warehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
Data architect Armando Vázquez identifies eight common types of data architects: Enterprise data architect: These data architects oversee an organization’s overall data architecture, defining data architecture strategy and designing and implementing architectures.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Recently, datalakes have gained lot of traction to become the foundation for analytical solutions, because they come with benefits such as scalability, fault tolerance, and support for structured, semi-structured, and unstructured datasets.
Many organizations are building datalakes to store and analyze large volumes of structured, semi-structured, and unstructured data. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products.
For instructions, refer to Creating and managing Amazon OpenSearch Service domains. Choose Send test message and test to make sure you receive an alert on the PagerDuty service. This notification can be safely acknowledged and resolved from PagerDuty because this is was a test.
These tables are then joined with tables from the Enterprise DataLake (EDL) at runtime. During feature development, data engineers require a seamless interface to the EDW. Previous solution process In the previous solution, product team data engineers spent 30 minutes per run to manually expose Redshift data to Spark.
Use Lake Formation to grant permissions to users to access data. Test the solution by accessing data with a corporate identity. Audit user data access. For a complete guide on creating and providing a certificate, refer to Providing certificates for encrypting data in transit with Amazon EMR encryption.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content